登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了在UOS V25服务器操作系统上部署天数智芯AI加速卡监控系统的完整方案。内容包括:基础环境配置(操作系统、服务器型号、驱动版本等)、天数智芯驱动安装指南、ix-exporter容器化部署步骤(镜像拉取、容器启动及验证)、Prometheus监控配置(针对vLLM和SGLang服务的指标采集)与容器化部署方法,以及Grafana可视化平台的容器化部署、数据源配置和定制仪表盘导入流程。文档
本文详细介绍了在UOS V25服务器操作系统上部署海光K100_AI加速卡监控系统的完整流程。内容包括基础环境配置(驱动、DTK SDK安装)、dcu-exporter部署、Prometheus容器化配置以及Grafana仪表盘导入。通过ROCm驱动安装验证、dcu-exporter服务启动、Prometheus数据抓取配置等步骤,最终实现在Grafana中可视化监控DCU加速卡状态。文档提供了各
Ascend Device Plugin — Part 1 入口层 + 工厂层 超深度源码分析之一
Ascend Device Plugin 系统级架构分析
摘要 本文详细介绍了Kubernetes集群维护的三大核心任务:升级、备份和证书管理。主要内容包括: etcd备份与恢复:讲解如何创建和验证etcd快照,以及灾难恢复流程,强调异地存储和定期演练的重要性。 集群升级:提供kubeadm升级的详细步骤和版本限制,控制面和工作节点的升级顺序,以及节点维护的cordon/drain操作。 证书管理:介绍如何检查证书过期时间并续期,重点说明CA证书过期的严
Ascend Docker Runtime v26.0.1 之六 mindxcheckutils/ — 超深度逐行分析
Ascend Docker Runtime v26.0.1 之五 install/ — 超深度逐行分析
下面是一套可以在 K8s 集群外侧或 Custom Metrics Adapter 中运行的 Python 监控与自动化伸缩评估代码。"""生产级 vLLM 显存利用率与 K8s 动态扩缩容评估探针作者: 苏沁宁 (苏苏)""""""vLLM 推理引擎 Prometheus 指标拉取与 HPA 决策器"""try:# 提取浮点数值logger.error(f"查询 Prometheus 指标失败
掉拍子的鼓手留不住听众,容易崩溃失忆的 Agent 留不住用户。通过把大模型 Agent 的运行逻辑收拢为 LangGraph 强类型状态图,结合持久化 Checkpoint 与 K8s 节点容错,才能让 Agent 在面对云原生环境的网络抖动与 Pod 重启时,依然像打了稳固节拍一样死死卡住执行节奏,提供真正工业级的稳定性。
Ascend Docker Runtime v26.0.1 之四 hook/ — 超深度逐行分析
Ascend Docker Runtime v26.0.1 之三 runtime/dcmi/ — 超深度逐行分析
团队AI能力建设的核心不是"会不会用AI工具",而是"能不能把AI融入日常工作流并持续改进"。建议从最简单、见效最快的一个场景(如SQL优化助手)开始,用数据证明价值后再扩展。最重要的成功因素不是技术选型,而是Leader的持续推动和团队的正反馈循环。从我们的实践来看,12人团队完成三阶段建设总投入约180人天(含培训和实践时间),产出包括:慢查询分析效率提升2.4倍、年均节省DBA人力约420小
│ 企业应用层 ││ │ 智能客服系统 │ │ 企业知识库 │ │ AI机器人 │ │ 数据分析平台 │ ││ │ API 网关层 (Kong / APISIX) │ ││ │ 认证 · 限流 · 路由 · 负载均衡 · 审计 │ ││ │ ││ │ 服务编排层 (RAG / Agent) │ ││ │ │ RAG 服务 │ │ Agent 服务 │ │ 工具调用 │ │ 会话管理 │ │ ││
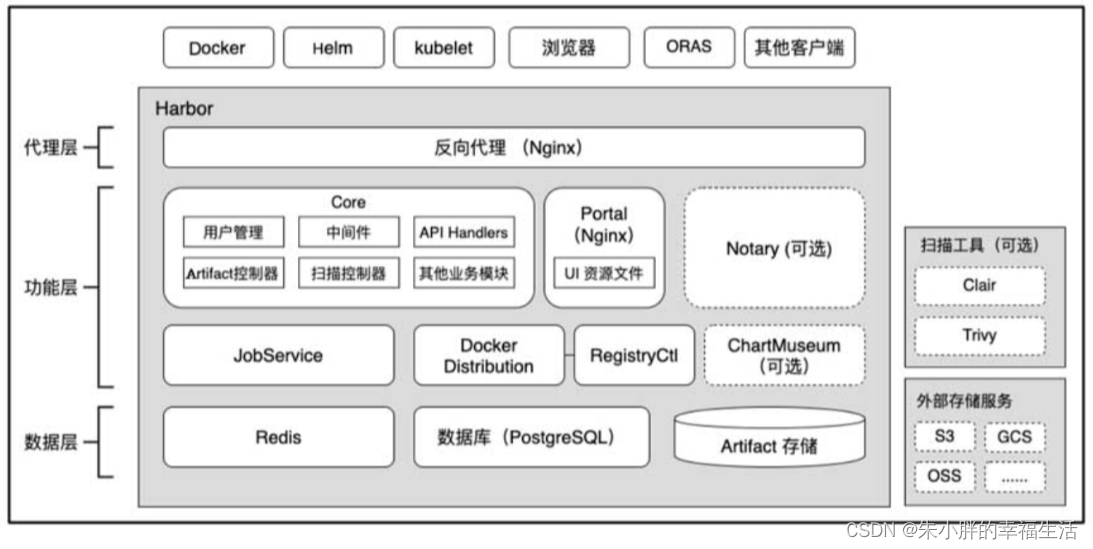
Docker容器应用的开发和运行离不开可靠的镜像管理,虽然Docker官方也提供了公共的镜像仓库,但是从安全和效率等方面考虑,部署我们私有环境内的Registry 也是非常必要的。之前介绍了Docker私有仓库Registry,这里介绍另一款企业级Docker镜像仓库Harbor的部署和使用,在Kubernetes集群中,推荐使用Harbor仓库环境。
强制删除一个podkubectl delete pods--grace-period=0 --force强制删除一组coredns,两个一起删除kubectl delete pod coredns-68b9d7b887-5pd75 coredns-68b9d7b887-wc8qw -n kube-system --grace-period=0 --force
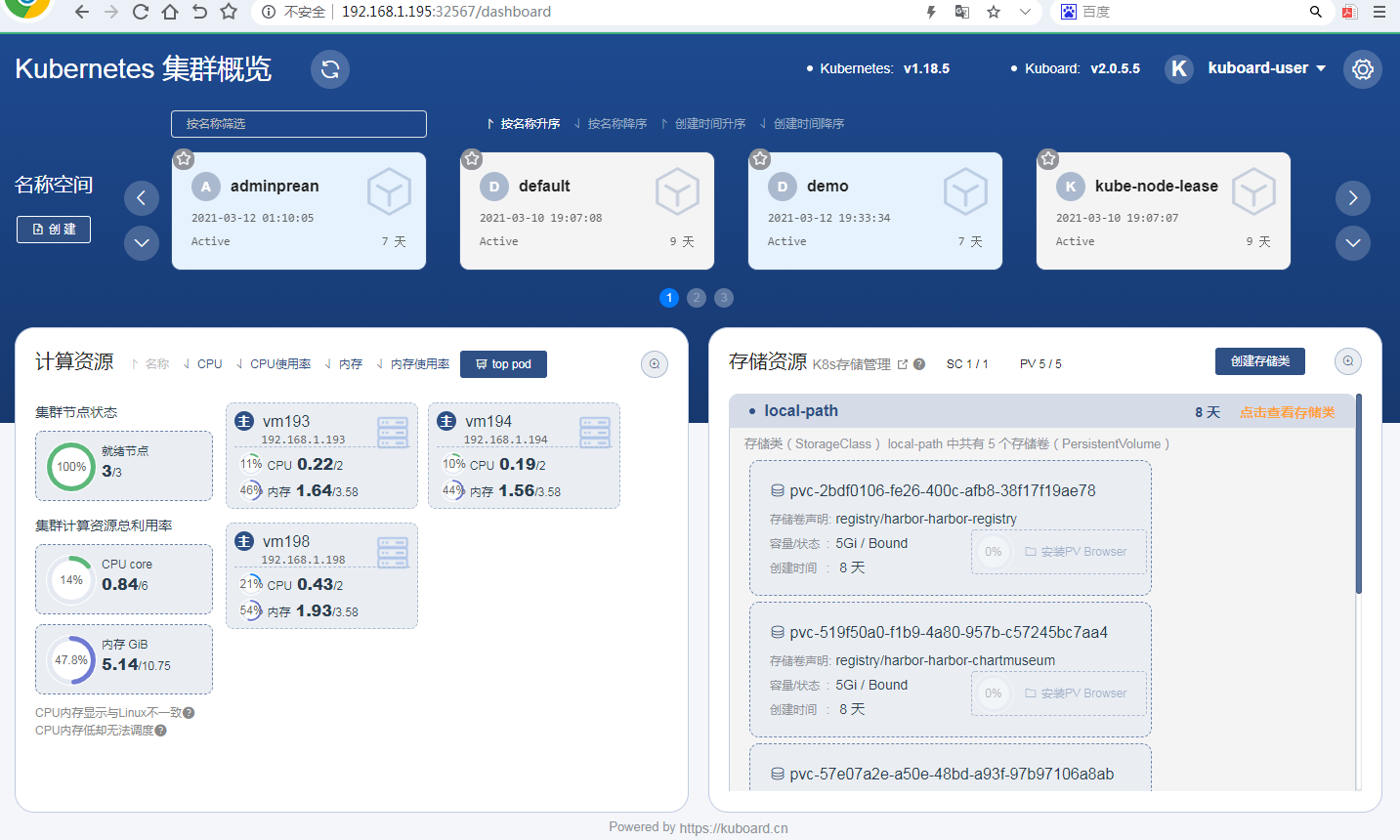
本文主要以离线方式部署,适用于在线和离线两种状态,而如果在线状态,那么步骤3可忽略,两条命令即可搞定。不论x86还是arm,不论在线还是离线,不论国际还是国产操作系统,使用kt工具和对应的离线安装包,安装k8s和kubesphere 一如既往的快和简单。
node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate
runtime/process/process.go — 超深度逐行分析
runtime/main.go — 超深度逐行分析
可一旦场景变成“大量短生命周期、彼此完全不同的环境需要被快速拉起”,中位延迟和累积时间才是真正决定吞吐和成本的变量。三个任务几乎同时到达同一套计算平台:一个运行自定义容器的机器人仿真、一个需要精确 CUDA/Python/模型服务组合的语音 Agent、一个客户直接提交的黑盒容器。可 AI 平台更像每天要临时搭建完全不同的实验台——有的要液压机械臂,有的要精密光学台,有的干脆是客户自带的神秘设备。
ML特征存储是管理机器学习特征的关键基础设施,它通过提供特征的存储、检索和管理能力,帮助团队更高效地构建和部署机器学习模型。随着机器学习的发展,特征存储将变得更加重要。在实践中,我们需要关注特征存储部署、特征管理、特征服务和特征质量等方面。通过选择合适的技术和最佳实践,可以构建高效、可靠的特征存储系统。
Ascend Docker Runtime v26.0.1 系统级架构分析
数据库AI Agent化的可行路径是渐进式:先做只读分析类的全自动(日志分析、指标解读),再做优化建议的半自动(人工确认后执行),最后才是DDL/DML的半自动。完全自主的数据库运维Agent至少还需要2-3年的技术积累。从我们的Agent原型开发经验来看,最务实的落地路径是"窄场景突破"——选择一个具体的高频场景(如"慢查询自动优化")做深度实现,而非试图构建一个"全能数据库Agent"。
随着机器学习和人工智能的快速发展,在Kubernetes上部署和管理ML工作负载已经成为趋势。本文将深入探讨如何在Kubernetes环境中高效运行机器学习训练和推理工作负载。
ML训练管道是构建高效机器学习训练流程的关键技术,它通过自动化和标准化训练过程,提高机器学习开发效率和模型质量。随着机器学习应用的普及,ML训练管道将变得更加重要。在实践中,我们需要关注管道设计、实现、测试和运维等方面。通过选择合适的技术和最佳实践,可以构建高效、可靠的ML训练管道。
训练调度:使用Kubeflow管理ML工作流模型管理:使用MLflow进行模型版本控制GPU资源:配置GPU节点池和资源调度数据存储:部署MinIO管理数据集开发环境:使用JupyterHub提供交互式开发可视化:配置TensorBoard进行实验追踪模型部署:使用TensorFlow Serving部署模型监控告警:建立训练指标和资源使用监控建议根据团队规模和业务需求选择合适的组件,构建高效的M
可观测性自动化是实现监控和告警自动配置与响应的关键,它通过智能分析和自动化技术,减少人工干预,提高运维效率。随着系统复杂性的增加,可观测性自动化变得越来越重要。在实践中,我们需要关注自动化规划、配置自动化、智能分析和自动响应等方面。通过选择合适的技术和最佳实践,可以构建高效、可靠的可观测性自动化体系。
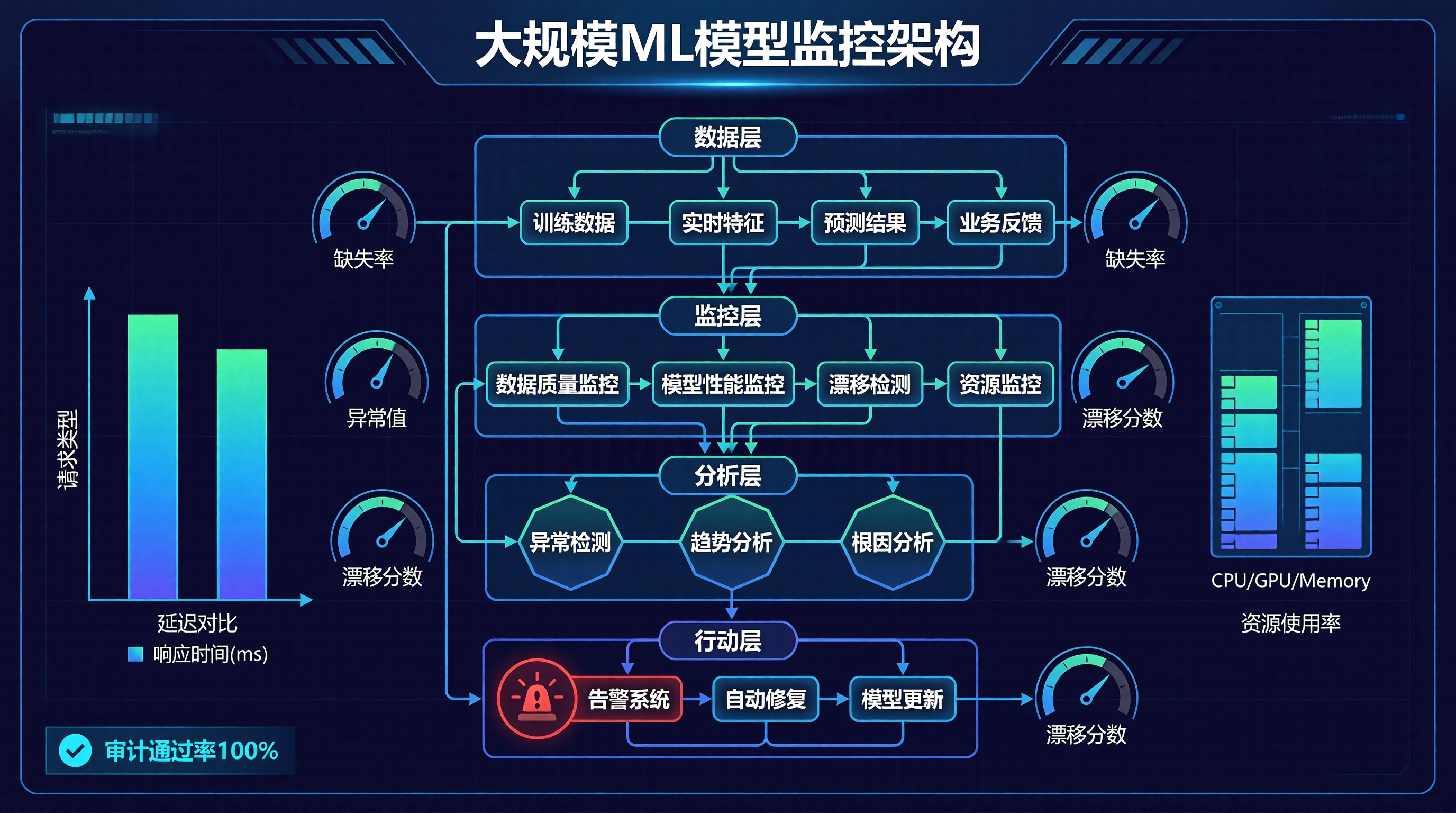
大规模ML模型监控是保障生产环境中模型可靠性和性能的关键。通过多层次、多维度的监控体系,可以及时发现问题并采取行动。数据质量:持续监控输入数据的质量和分布模型性能:跟踪模型的预测准确性和稳定性漂移检测:检测数据和概念漂移告警系统:建立完善的告警和响应机制随着ML模型规模的增长和复杂度的提升,监控体系将变得越来越重要,为模型的可靠运行提供保障。
构建支持跨平台统一清洗和向量化 大模型数据清洗中的去重与过滤机制 的高性能多模态数据框架系统是构建现代分布式系统的关键技术方向,本文从架构设计、实现原理到实践案例,全面深入地进行了分析。核心要点构建支持跨平台统一清洗的核心在于合理的技术选型和架构设计性能优化需要从多个维度综合考虑监控和运维体系建设同等重要需要根据实际业务场景灵活调整方案持续学习和跟进新技术是保持竞争力的关键。
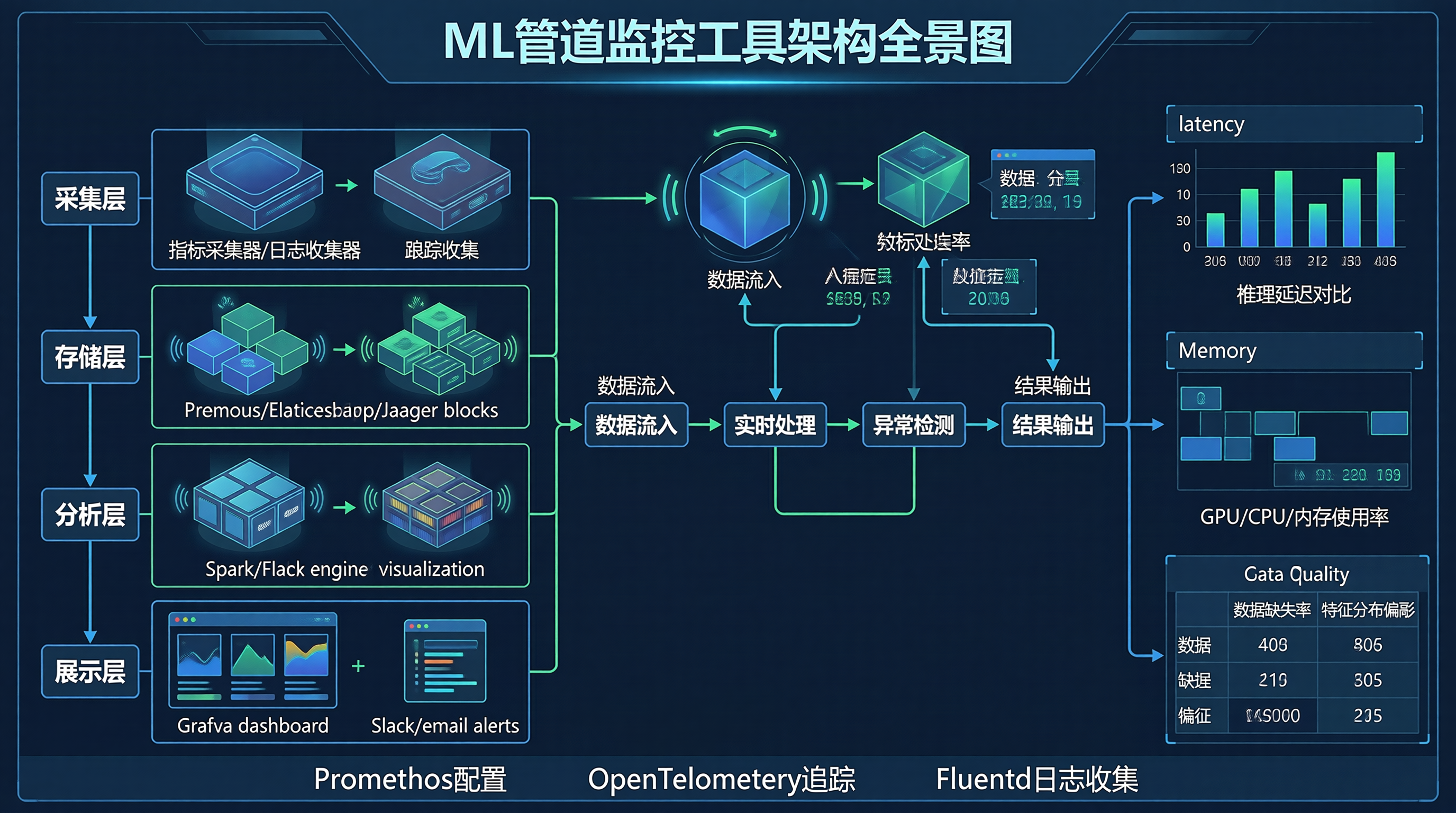
ML管道监控工具是监控机器学习管道运行状态的关键,它通过全面的数据采集、存储和分析,帮助开发者和运维团队了解管道状态、诊断问题和优化性能。随着ML的发展,管道监控变得越来越重要。在实践中,我们需要关注需求分析、工具选择、配置实施和运维管理等方面。通过选择合适的技术和最佳实践,可以构建高效、可靠的ML管道监控体系。
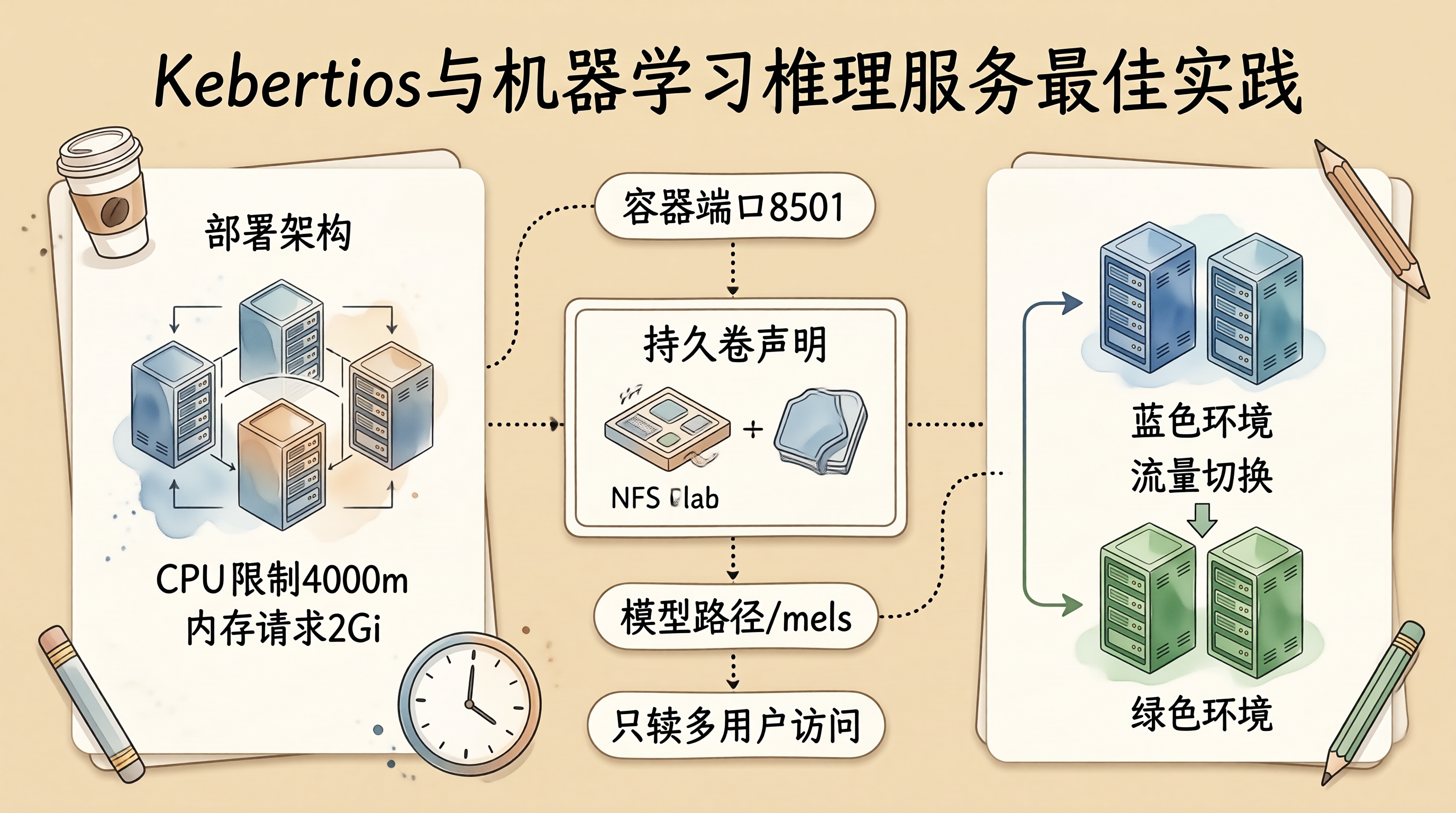
实践领域关键要点模型存储使用只读多挂载PVC,确保模型一致性部署策略采用蓝绿部署,实现零停机更新资源管理根据推理需求合理设置资源请求和限制自动扩缩容结合CPU利用率和QPS指标进行弹性伸缩模型优化使用TensorRT、ONNX Runtime等优化推理性能监控告警监控推理延迟、吞吐量和错误率安全防护实施请求认证和访问控制Kubernetes为机器学习推理服务提供了强大的基础设施支撑。通过合理的架构
ML模型优化技术是提升机器学习模型性能的关键,它通过模型压缩、量化、剪枝等技术,提高模型的推理速度、降低资源消耗并保持模型准确性。随着AI应用的发展,模型优化技术变得越来越重要。在实践中,我们需要关注需求分析、策略设计、实施配置和运维管理等方面。通过选择合适的技术和最佳实践,可以构建高效、可靠的ML模型优化体系。
冷热备方案的冷启动超时排查需要按"确认现象→分段测量→根因分析→修复验证"四步走。80% 的超时问题集中在镜像拉取和模型加载两个阶段,通过镜像缓存、模型量化、GPU 预留和探针宽容配置,可以将冷备切换时间从 120s+ 压缩到 30s 以内。本文介绍了该技术的核心原理和实践应用。理解核心算法的工作原理实现优化策略提升性能注意资源管理避免内存泄漏根据实际场景选择合适的配置进行性能测试确定瓶颈逐步引入
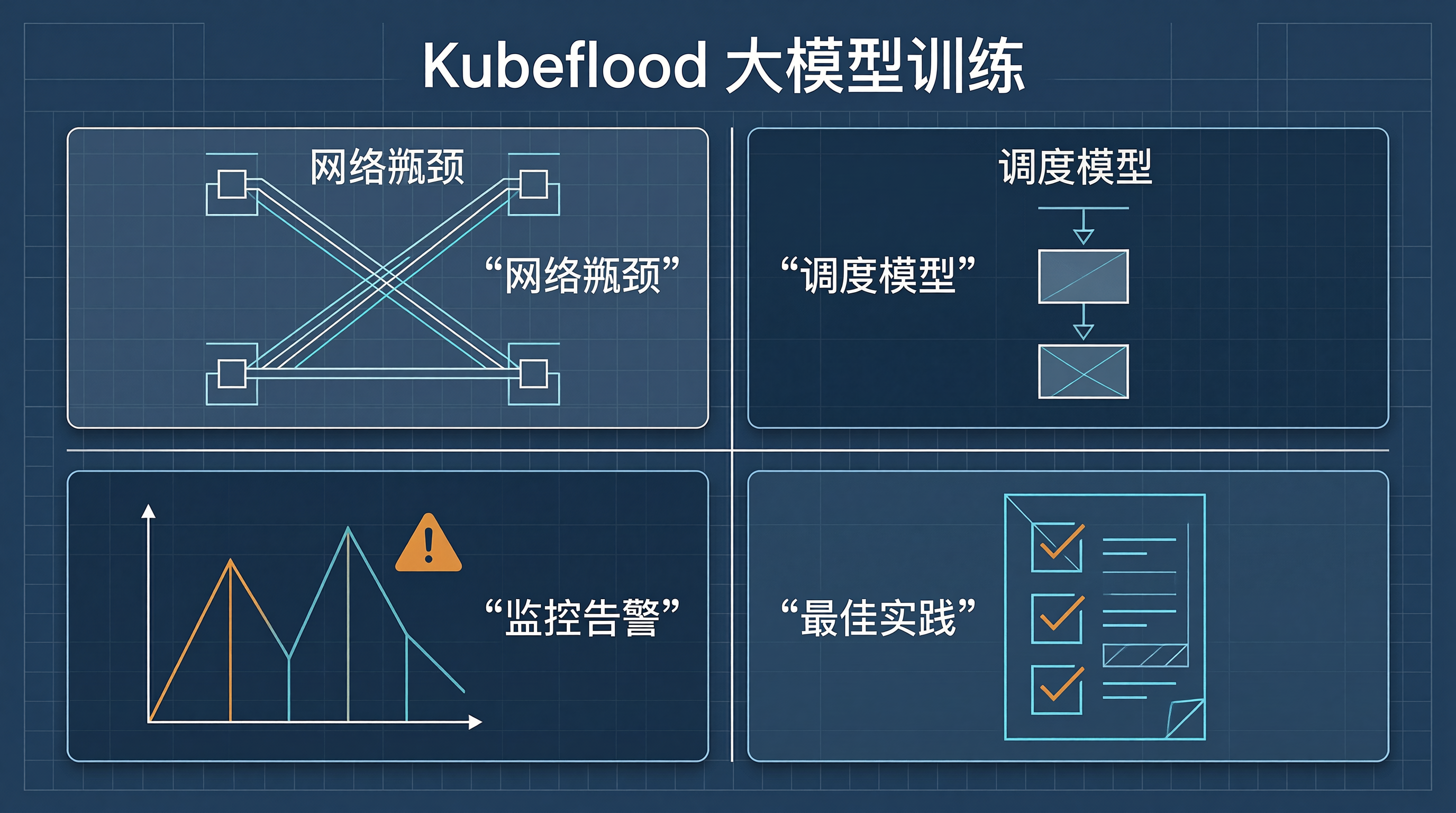
优化策略适用场景性能提升实施复杂度NCCL 算法调优AllReduce 瓶颈+30%低网络拓扑感知多节点训练+50%中并行策略自动选择异构网络+40%高高性能训练+200%高核心思路:通过 Kubeflow Pipeline 自动化诊断网络瓶颈、选择并行策略、配置 NCCL 参数,将分布式训练的网络优化从"手动调参"升级为"自动决策"。实测表明,网络感知的调度模型可将大模型训练效率提升 40-60
Kubeflow 多租户 GPU 隔离的核心是三步走:先共享(Volcano GPU Share),再隔离(MPS + cgroup),最后监控(ResourceQuota + Prometheus)。在保障租户公平性的同时,将 GPU 利用率从 35% 提升到 80%+,实现算力的最大化利用。大语言模型的流式输出技术显著提升了用户体验。使用 SSE 或 WebSocket 实现流式传输实现增量渲
kubernetes
——kubernetes
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 2048 AI社区
2048 AI社区

 AMD开发者中国社区
AMD开发者中国社区
 智能体开发者社区
智能体开发者社区




 深开鸿 技术专区
深开鸿 技术专区


 AI硬件创业社区
AI硬件创业社区


 DAMO开发者矩阵
DAMO开发者矩阵
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AI编程社区
AI编程社区