登录社区云,与社区用户共同成长
邀请您加入社区
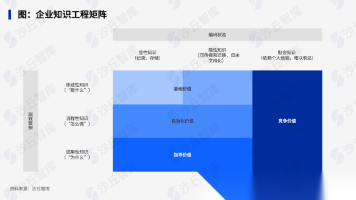
从更新内容来看,v0.15.0不仅增加了长上下文和MTP前缀缓存命中能力,也新增了DeepSeek V4支持、MemDecode支持、投机解码中的引导解码支持,并持续完善TurboMind的内存分配、对象缓存、调度器、并行配置、张量复制、Gated Delta Rule等底层能力。本次版本围绕推理性能、模型支持、长上下文处理、投机解码、TurboMind底层能力、多机部署、Ascend适配、多模态
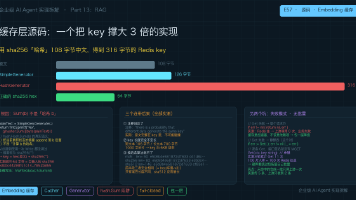
本文揭示了企业级AI Agent实现中RAG模块的关键问题与优化点。主要内容包括: 接口设计:Embedder接口仅保留核心功能,token用量等元数据通过回调机制获取,体现了最小接口原则。 缓存架构:采用三接口分工模式(Embedder包装层/Cacher存取层/Generator键生成层),其中键生成策略被抽象为独立接口,支持灵活扩展。 性能问题:实测发现HashGenerator生成的Red
本文系统分析了HarmonyOS NEXT平台下图片缓存框架的设计与实现。首先指出系统原生Image组件三级缓存机制的局限性,深入剖析了社区标杆方案ImageKnife Pro的拦截器责任链架构与LRU缓存算法实现,并结合京东自研图片库的跨端工程实践,提出一套面向生产环境的完整设计方案。该方案采用分层架构设计,包含请求模型、缓存Key构建、内存/磁盘LRU缓存、预加载策略等核心模块,强调通过场景化
Release 构建是从开发到发布的关键步骤。在 11 模块架构中,控制了代码混淆的粒度,资源压缩减小了包体积,隔离了开发和发布配置。HAR 包的发布流程为模块复用提供了标准化路径。正确理解和配置混淆规则,确保关键 API 不被混淆,是 Release 构建成功的保障。
增量编译和构建缓存是 Hvigor 加速开发的核心机制。在 11 模块架构中,模块化的设计天然有利于增量编译——修改一个模块不影响其他模块的缓存。理解缓存的触发条件和失效场景,合理使用 clean build 策略,能够在保证构建质量的同时最大化开发效率。核心原则是:正常开发用增量编译,遇到异常用 clean build,构建服务器用全量构建。
说明,我这次的实验环境是三台服务器,每台额外分配五个数据盘,共计提供给minio集群使用为15个数据盘,因为是测试环境所以磁盘大小只给了50G,生产请自行评估,本次是将所有磁盘都格式化为xfs文件系统,格式化文件系统后我在根目录下分别创建了data1,data2,data3,data4,data5五个目录给这五个数据盘挂载,详细磁盘格式化以及挂载方法自行百度,这里不详细赘述,实在不懂就评论区问吧。
在淘客返利APP的开发过程中,随着用户量和数据量的不断增长,系统性能面临巨大挑战。尤其是数据库和缓存的性能瓶颈,直接影响到用户体验和系统的稳定性。本文将分享我们在MySQL分库分表以及Redis缓存穿透问题上的实战经验,希望能为类似项目提供参考。通过MySQL分库分表和Redis缓存穿透解决方案的实践,我们成功优化了淘客返利APP的性能,显著提升了系统的响应速度和稳定性。分库分表有效缓解了数据库的
对于一个页面,程序需要做的事情总是那么多,性能优化就是分清要做哪些事,然后排优先级,把优先级高的先做,让界面展示出来,让用户看到内容。剩下的优先级不高的事,就慢慢来。
asp.net网站使用Memcached能够极大减少数据库io,提高web读取效率,对于用户体验和数据服务器压力有很大的作用!以下介绍window版Memcached引用在应用程序运行的过程中总会有一些经常需要访问并且变化不频繁的数据,如果每次获取这些数据都需要从数据库或者外部文件系统中去读取,性能肯定会受到影响,所以通常的做法就是将这部分数据缓存起来,只要数据没有发生
Redis(三)——Redis缓存及分布式锁
本文系统介绍了 Redis 7 在缓存、消息队列和分布式锁三大核心场景的实战应用方案。主要内容包括:Redis 7 新特性回顾(如 Functions、ACL v2 等)、基础缓存模式实现与三大缓存问题(穿透/击穿/雪崩)的解决方案、基于 Pub/Sub 和 Stream 的消息队列实践、分布式锁的安全实现(含 Redisson 和红锁算法),以及生产环境配置建议(内存优化/持久化/集群)。
PyCharm,作为业界领先的集成开发环境(IDE),提供了强大的数据库工具,支持多种数据库连接和操作。不断探索和实践PyCharm的数据库功能,你将能够更加灵活地进行数据库开发。让我们一起在PyCharm中配置数据库连接,开启高效数据库开发的大门。通过本文的介绍,你应该对如何在PyCharm中配置数据库连接有了深入的理解。PyCharm的数据库工具提供了一个强大且易于使用的界面,使得数据库开发变
2026世界人工智能大会标志人形机器人产业进入商用新阶段:60台全尺寸人形机器人首次实现多日连续实景作业零故障,同时商用接待、家庭陪伴、载人变形等新型机器人集中亮相,呈现两大趋势——人形机器人从演示转向实用验证,产业路线分化为轮足/变形/特种等多形态方案。这要求底层操作系统具备硬实时控制、AI算力隔离等能力,国产望获OS通过微秒级调度、算力分区、轻量化架构(4.4MB/0.9秒启动)等特性,支撑了
当前大模型Agent落地的核心瓶颈集中在两个维度:一是单次推理延迟高达3-10s,无法满足C端用户交互的实时性要求;二是推理成本占系统总运营成本的60%以上,大规模部署的经济性极差。作为Agent系统的执行控制中枢,Harness层(也称为Agent执行层/控制平面)是部署缓存策略的黄金位置:既可以感知任务语义、执行状态、上下文依赖,又能跨会话、跨用户复用推理结果,相比大模型侧KV缓存、应用层结果
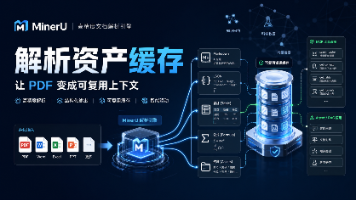
文档解析应从临时处理升级为可复用资产,支持缓存、版本控制和多格式输出。MCP 2026-07-28候选版强调结构化内容、缓存和追踪,适用于Agent和RAG场景。MinerU作为解析平台,提供多格式输出和入口,需验证元素级结构化、缓存一致性和生命周期管理。评测应关注OCR、表格、公式等关键元素的可复用性,记录失败案例并建立验收标准。
摘要:针对大模型API成本高企问题,提出三位一体优化策略:1)Token缓存通过精确/语义匹配复用历史回答,可减少30-40%调用;2)批量推理合并请求摊薄固定开销,降低成本30%;3)模型降级按任务复杂度分级调用不同规格模型。这些方法可在效果损失<5%前提下降低50%以上成本,聚合平台已将其内置为标准化服务。该方案特别适用于日请求量超百万的高频场景,能显著提升产品经济性。(149字)
面对KV Cache热潮,保持理性判断,分清落地优先级更为重要;抓准AI落地的核心数据基建,也远比仓促部署尚未成熟的缓存卸载方案更为稳妥。
打破大模型 KV Cache 魔咒:一种让跨模型 Agent 缓存 99% 命中的动态工具注入方案
一说到垂直领域的大模型,大家立刻会想到参数少,没有那么智能,但是能满足行业的需求的模型+机密的行业数据。目前AI主要是替代工具,并没有产生新的商业模式与生产力,除非免费使用AI的用户,能通过另外的商业模式变现回来,目前还没有看到。To B卖云服务给企业,相当于企业有一块"私有的机房+私有模型+私有数据",行业数据不会泄露的同时能获得专属大模型提供的服务,这里未来就是阿里云,腾讯云,百度云,华为云的
2026 年 5 月,Redis 之父 Salvatore Sanfilippo (antirez) 发布了他的全新项目,这一项目彻底颠覆了大模型本地推理的内存范式。受 ds4 核心思想启发,我们为 AI IDE 项目实现了一套完整的智能内存管理系统,成功在仅 0.9GB 可用内存的极端环境下,保障了核心功能的稳定运行,并为未来运行百亿级大模型奠定了基础。本手册全面记录了 ds4 的技术创新、我们
fill:#333;important;important;fill:none;color:#333;color:#333;important;fill:none;fill:#333;height:1em;持久化输入文本Tokenizer 切分为 token词嵌入 → 向量序列Prefill 阶段并行处理所有 token建立 KV Cache(每层每 token 的 K/V 向量)Decode 阶
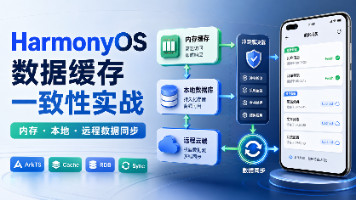
本文探讨了HarmonyOS应用中数据缓存一致性的解决方案,针对内存、本地和远程三层缓存之间的同步问题提出实战策略。文章指出常见问题表现为列表闪动、用户修改被覆盖等,核心在于建立合理的数据流动机制。 文章架构清晰: 首先分析三层缓存的特点与边界 强调版本字段对数据同步的关键作用 分别设计内存缓存(快速读取)、本地存储(可靠持久化)和远程数据源(权威结果)的实现方案 通过同步协调器进行智能合并,避免
在国内装 PyTorch,最烦的两件事:一是想却总装错;二是同一个版本要在好几台机器、好几个虚拟环境里反复下载,既费时间又费流量。这篇教程解决两个问题:用阿里云镜像安装的 PyTorch;以及把常用版本的 wheel,之后在任意环境。赶时间的话,直接抄下面这一段三条命令即可;想知道每一步为什么这么写,再往下看详解。下面的export${VAR//./}等写法针对Windows 请把export换成
L1 精确缓存— MD5 hash, <1ms, 命中率 ~15%L2 语义缓存— Embedding cosine sim, ~10ms, 命中率 ~25%组合命中率 ~40%— 年省 $4 万+ (百万日活)
本文分享了博主通过系统架构设计师软考的经验总结: 考试内容趋势:综合知识部分侧重AI相关领域(如知识图谱、检索中毒),需重点关注; 案例分析题多变,需扎实基础知识并灵活应用; 高并发、缓存(如Redis锁)是核心考点,论文和高频题型均涉及,建议深入学习Redis等实用技术。博主后续将陆续更新备考笔记与经验,助力考生备考。
力反馈控制是高端精密机器人的核心技术,通过实时感知接触力实现柔性操作,但存在信号延迟引发的控制震荡难题。国产望获OS以亚微秒级硬实时调度能力(延迟<0.48μs)解决传统Linux系统毫秒级抖动问题,保障4kHz高频力控的时序稳定性。其单内核架构支持EtherCAT高速通信和ROS2/DDS框架,相比传统方案实现三个数量级的性能提升,有效消除力反馈延迟导致的工件报废风险,为精密装配、具身智能机器人
本文主要介绍一个在sglang启用本地大模型进行对话之后,远程清除对话缓存的一个指令。可以在闲时或者有紧急任务时,释放出一部分的显存出来作其他用途。
SSD固件是运行在主控芯片上的嵌入式操作系统,负责FTL地址映射、垃圾回收、磨损均衡、ECC纠错、温度管理等所有底层逻辑。它决定了SSD的性能表现、数据安全和使用寿命。本文从固件的架构分层、核心模块、启动流程、升级机制到安全风险,全面拆解这块"隐藏在硬件中的软件"。
企业早期应用大模型时,常见做法是把文档导入知识库,再通过 RAG 让模型检索并回答问题。这种方式可以快速改善通用大模型不了解企业内部信息的问题,但主要解决的仍然是“文档事实可访问”的问题。
缓存命中指的是,大模型端通过算法来确定agent 的当前发送数据 与 上一条发送数据之间的相似度,若是大于某一阈值,就认为是缓存命中,可以少收钱。agent 的N+1请求数据: [system] [msg1] [msg2] ... [msgN] [msgN+1]← 再次携带完整历史。agent 的N请求数据:[system] [msg1] [msg2] ... [msgN]← 必须携带完整历史。无
缓存
——缓存
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 AI Agent技术社区
AI Agent技术社区

 EazyDevelop社区
EazyDevelop社区

 HarmonyOS开发者社区
HarmonyOS开发者社区


 深开鸿 技术专区
深开鸿 技术专区











 openEuler 社区
openEuler 社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 2048 AI社区
2048 AI社区
 AI编程社区
AI编程社区











 DAMO开发者矩阵
DAMO开发者矩阵



 智能体开发者社区
智能体开发者社区