




- @mopmgerg54mo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026年的AI编程工具市场已经从“拼模型智商”进入到了“拼工程落地”的阶段。和恰好代表了三种不同的进化方向:极致免费主义、全场景工作台和终端王者。
新手入门:先尝试Ollama,5分钟即可体验项目迁移:选择LocalAI,API兼容性最重要资源有限Ollama的内存管理更友好需要定制LocalAI的灵活性更好。
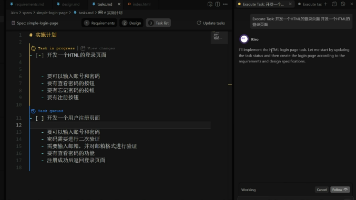
Kiro是一款由亚马逊云科技(AWS)推出的,其核心特色在于**“规范驱动开发”(Spec-Driven Development)**理念。它旨在将AI的强大能力与工程化的严谨性相结合,帮助开发者和团队更可靠、更高效地构建和维护复杂软件,从单纯的"AI编程"进化为"AI协作开发"。为了让你更全面地了解Kiro,我将从它的核心哲学、主要工具、关键特性以及适用人群这几个方面来详细介绍。
以上方案可根据需求选择,如低延迟选百聆、多语言翻译选FunAudioLLM、高精度中文识别选FireRedASR-LLM。
新手入门:先尝试Ollama,5分钟即可体验项目迁移:选择LocalAI,API兼容性最重要资源有限Ollama的内存管理更友好需要定制LocalAI的灵活性更好。
是一个功能强大的开源项目,它的主要目标是通过标准的 OpenAI API 格式访问所有的。One API 支持多种主流的大语言模型,包括 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、Google 的 PaLM2 和 Gemini 系列等。这意味着用户可以通过一个统一的接口访问不同的模型,大大简化了开发和使用过程。

Snowboy 是一个开源的、轻量级的语音唤醒引擎,专为嵌入式设备和移动设备设计。它允许用户通过自定义的唤醒词来激活语音助手。原官方训练平台已关闭# 安装 Mycroft Precise git clone https://github.com/MycroftAI/mycroft-precise cd mycroft-precise。
2026年的AI编程工具市场已经从“拼模型智商”进入到了“拼工程落地”的阶段。和恰好代表了三种不同的进化方向:极致免费主义、全场景工作台和终端王者。
的文本转语音(TTS)API,将文本转换为语音并保存为音频文件(如MP3)。它基于 Google 的 TTS 引擎,支持多种语言和发音选项。(Google Text-to-Speech)是一个 Python 库,用于调用。希望这份详细介绍对你有帮助!如果有进一步问题,欢迎讨论。(违反 Google TOS 可能被封)(依赖 Google TTS 服务)(Google 可能会封禁高频访问)如果需要更
2026年的AI编程工具市场已经从“拼模型智商”进入到了“拼工程落地”的阶段。和恰好代表了三种不同的进化方向:极致免费主义、全场景工作台和终端王者。