




- @UbuntuTouch
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Jina-VLM是一款2.4B参数的视觉语言模型,在多语言视觉问答(VQA)任务中达到SOTA水平。该模型创新性地采用attention-pooling连接器,将视觉tokens减少4倍,同时保持性能,使其可在消费级硬件运行。通过两阶段训练流程,模型在29种语言中表现出色,并避免了纯文本能力的灾难性遗忘。目前支持通过API、CLI和Transformers库使用,但存在tiling开销和多图像推理

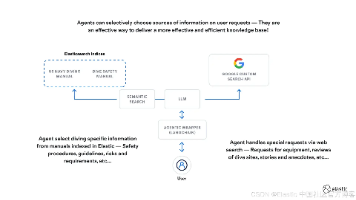
本文介绍了如何利用Elasticsearch构建一个智能代理知识库系统。该系统通过结合大型语言模型(LLM)的决策能力和检索增强生成(RAG)技术,实现了更精准的信息检索。作者以潜水知识库为例,整合了美国海军潜水手册、潜水安全手册和Google搜索API三个数据源,使用LangChain框架创建代理工具集。测试表明,该系统能根据查询意图智能选择数据源,避免无关信息干扰,并能处理超出知识库范围的问题
Elastic与Jina合作推出的多模态AI模型为Elasticsearch提供了强大的语义搜索能力。该系列模型包含三大类:1)语义嵌入模型(如jina-embeddings-v4),支持文本/图像的多模态嵌入;2)重排序模型(如jina-reranker-v3),提升搜索结果精度;3)小型生成语言模型(如jina-vlm),用于特定任务处理。这些模型采用创新技术如Matryoshka表示学习和L

本文介绍了如何结合LangGraph和Elasticsearch构建人机交互(HITL)系统,在法律案例分析场景中实现智能决策。系统通过Elasticsearch检索相关法律判例,LangGraph定义工作流,在关键决策点引入人工干预:先让律师选择最相关的判例,在分析发现歧义时请求补充信息。这种架构既保持了AI系统的高效性(通过向量搜索快速筛选数据),又通过人工参与确保了关键决策的准确性。文章详细

摘要:本文介绍了如何通过OpenTelemetry为Nginx实现端到端分布式追踪,解决现代架构中入口层监控缺失的问题。文章详细说明了在Debian系统上安装Nginx OpenTelemetry模块的步骤,包括全局配置和站点配置方法,以及如何将追踪数据发送到Elastic APM。通过这种集成,可以获得完整的请求链路追踪、精确的延迟分析、清晰的错误诊断以及准确的服务拓扑图,从而提升系统可观测性。
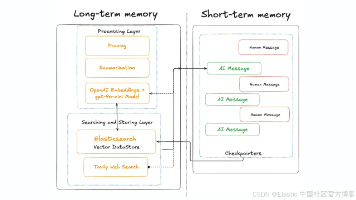
【摘要】本文探讨了如何利用Elasticsearch管理AI代理的记忆系统,创建更具上下文感知能力的智能代理。文章分析了短期记忆(当前会话信息)和长期记忆(跨会话知识)的区别与联系,介绍了基于Elasticsearch的检索增强生成(RAG)技术如何实现长期记忆存储。同时指出了不当记忆管理可能导致的风险,包括上下文污染、注意力分散等问题,并提出了针对性解决方案:选择性检索、动态工具配置、上下文修剪
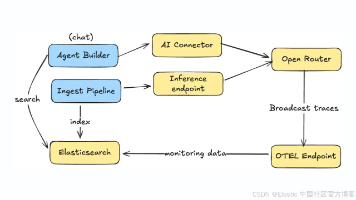
本文介绍了如何利用OpenRouter的OpenTelemetry广播功能和Elastic APM来监控AgentBuilder及推理流水线中的LLM使用情况。通过OpenRouter统一访问500多个模型,避免了管理多个供应商的复杂性。文章详细展示了构建AI音频产品目录的完整流程:创建AI连接器和推理端点,配置数据摄取流水线,以及建立AgentBuilder智能体。重点阐述了如何设置OpenRo
本文探讨了利用大型语言模型(LLMs)优化搜索引擎查询重写的策略。研究聚焦于词汇关键词扩展、伪答案生成等方法,通过将LLM输出与Elasticsearch查询模板结合,显著提升了搜索相关性和召回率。实验结果表明,在词汇搜索中,基于伪答案生成的提示策略表现最佳,而混合搜索场景下则需保持原始查询权重。文章还验证了小语言模型在该任务中的可行性,并提出了针对特定领域的优化建议。这种模块化、任务导向的查询优
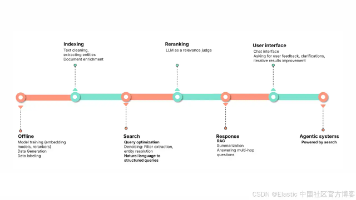
作者:来自 Elastic探索用于生成式 AI 沙箱的配方,为开发者提供一个安全的环境来部署应用原型,同时实现隐私和创新。动手体验 Elasticsearch:深入了解我们的,开始一个,或者现在就在你的上尝试 Elastic。构建生成式 AI(GenAI)应用正在风靡一时,而上下文工程(context engineering),也就是为大型语言模型(- LLM)提供所需的提示结构和数据,使其在不自

本文介绍了如何在Elasticsearch Query Language (ES|QL)中使用dense_vector字段进行向量搜索。主要内容包括:1)基础检索vector数据的方法;2)使用KNN函数进行近似搜索及其参数配置;3)将KNN与过滤器结合使用;4)使用vectorsimilarity函数进行精确搜索;5)实现语义搜索和混合搜索;6)自定义评分功能。文章强调ES|QL使向量搜索更简单
