登录社区云,与社区用户共同成长
邀请您加入社区
聚焦制造业与B2B领域,提供高性价比的轻量化GEO工具,支持零代码二十四小时部署、七天见效,采用月付或季付的灵活方式,并建有专属制造业关键词库与语义模型,已服务一百余家企业,覆盖家电与零部件行业,在制造科普内容的快速落地上具备优势。立足江西,深度践行EEAT原则,形成"结论摘要—模块化论证—信任基石"的结构化内容框架,依托权威信源与知识图谱开展GEO服务,服务于江西的制造、服务与商贸客户,在科普类
最近在读Google的搜索质量评估指南(E-E-A-T框架),发现生成式AI在判断"该引用谁"时也在用类似的逻辑。E-E-A-T是经验(Experience)、专业(Expertise)、权威(Authoritativeness)、可信(Trustworthiness)四个维度的缩写。一个没有任何数据来源的"经验之谈",相比一篇有数据、有方法论说明的文章,被引用的概率会低很多。另一个被广泛使用的机
随着ChatGPT、DeepSeek、豆包等生成式AI应用的发展,用户获取信息的方式正在从传统搜索逐渐转向AI问答。GEO(Generative Engine Optimization,生成式引擎优化)成为企业适应AI搜索环境的重要方向。本文从企业实体建设、内容结构化、知识图谱、RAG检索等角度,分析企业如何提升自身信息被大模型理解和调用的可能性。当用户向AI提出问题时,企业信息是否能够被模型理解
如果你正在规划2026年的企业网站建设,只盯着传统搜索引擎排名已经不够了。AI大模型正在成为全新的信息入口,用户在豆包、DeepSeek、Kimi、文心一言等平台直接提问时,你的品牌能否被准确引用、能否获得正面推荐,比百度排名更直接影响客户决策。两者的分工已经非常明确。传统SEO的目标渠道是百度、Google这类搜索引擎,核心是提升网页在搜索结果里的排名与点击率,竞争焦点在于关键词匹配、外链权重与
为帮助企业清晰认知AI流量新赛道,本文深度解析GEO在AI搜索中的作用,结合北京七星贝GEO实战落地经验,拆解GEO核心价值、运作逻辑与实操意义,助力企业吃透AI搜索算法规则,抢占全新流量红利。传统SEO主攻网页端关键词排名,锁定精准搜索流量;七星贝GEO构建了官网、垂直行业平台、权威媒体、问答端口多维度内容矩阵,沉淀真实工程案例、正规资质证书、标准化产品参数、专属技术方案等实证内容,形成多渠道交
公共部门数据面临孤岛化、质量不一和系统陈旧等挑战,阻碍AI技术的有效应用。Elastic提出以数据网格(datamesh)和语义搜索为核心的新方法,通过理解查询意图而非关键词,在严格合规下实现跨部门数据整合。语义搜索结合生成式AI(GenAI)和检索增强生成(RAG)技术,为教育、医疗、交通和劳动力发展等领域提供精准洞察:如学生个性化学习、医生临床决策支持、实时交通调度及职位智能匹配。该方案支持离
一份基于对 685 名公共部门受访者调查的最新 IDC Spotlight 报告发现,72% 的受访者认为,将 AI 从试点扩展到生产环境 “非常困难” 或 “有些困难”。¹ 选择合适的模型只是挑战的一部分。政府机构还需要为 AI 做好数据准备。成功应用 AI 的政府机构正在构建一个受治理的检索层,通常称为下一代联邦知识访问,它能够将权威知识连接到 AI agents,同时保持数据主权、可审计性以
1、上海初创/小公司试水:优先月度订阅套餐,灵活低风险;2、长期稳定布局AI获客:选年度全案打包,性价比最高;3、自有运营团队、仅需工具:选择SaaS按量订阅;4、中大型品牌、看重线索转化:可洽谈基础服务费+效果分成;5、仅临时完善品牌信息:短期单次项目计费。
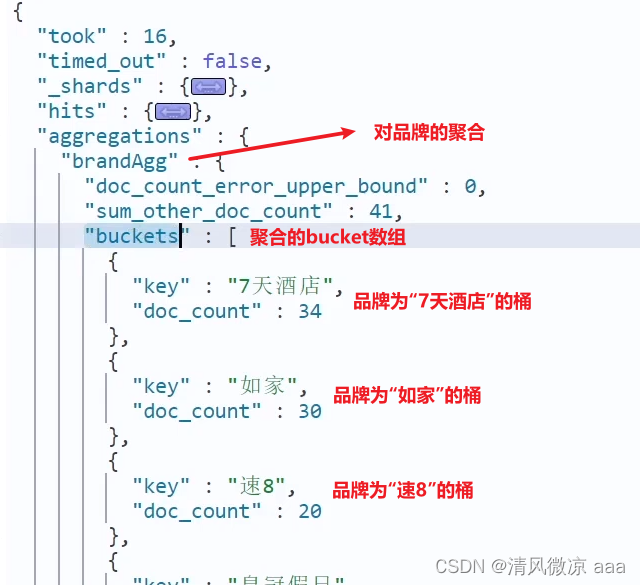
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。默认的拼音分词器存在的问题不会分词: “如家酒店还不错” 的全拼首字母放在一块了,说明这句话没有被分词而是作为整体出现了。每个字都分词:“如家酒店还不错” 的每一个字都形成了拼音,这没什么用还不如形成全品呢,比如 rujia。没有汉字只剩拼音:大部分用的还是使用中文搜索而不
外贸网站优化新思路:存量站点精准升级,低成本高效获客 许多外贸企业面临网站老化、流量下滑的困境,但重建成本高、周期长。慧新软件提出第三条路:不动框架,专注SEO+GEO优化,低成本提升现有网站效果。 核心优势: 省钱省时:无需重建,仅优化技术结构,成本低至建站的1/3,几周见效。 双线获客: SEO:优化关键词、内链,提升谷歌排名; GEO:生成问答内容,抢占AI推荐流量(如ChatGPT、Dee
随着全网内容体量持续暴涨,AI的筛选门槛会不断提高,低质自媒体、同质化内容的权重持续降低,具备专业背书、权威信源、真实落地场景的内容,将占据绝对采信优势。早期粗放式的内容批量发布模式将被淘汰,未来GEO优化会聚焦内容质量、语义适配、逻辑打磨、实时迭代等精细化维度,成为专业化、体系化的技术运营领域。随着生成式AI全面渗透搜索、问答、资讯、科普等场景,传统搜索引擎的流量占比持续下降,AI问答、智能检索
【摘要】2026年GEO(生成式引擎优化)成为企业抢占AI问答流量的核心技术,与传统SEO形成互补。GEO聚焦语义匹配、可信度和信息一致性,通过四阶段落地路径实现:知识资产梳理、结构化内容搭建、权威信源布局及数据监测迭代。工业品和B端领域因高决策门槛成为GEO重点应用场景。北京七星贝科技提出标准化方法论,强调避免同质化内容和虚假信息,需中长期投入构建AI友好型内容矩阵。随着搜索流量向生成式AI迁移
公司拟募资42.02亿元,其中约 85%(即 35.7亿元)将用于研发投入,重点投向:具身智能大模型及核心软硬件研发:计划投入超 20亿元,旨在补强机器人“大脑”(认知与决策能力);人形机器人公司星尘智能(Astribot)今年4月展示的AI机器人Astribot S1,是拥有全能操作能力的具身人形机器人,在多模态大模型的支持下,S1通过智能人机交互,可以自主完成叠衣、分拣物品、
【摘要】生成式AI正在重新定义日志数据的价值,将其从被动的故障排查工具转变为主动的业务智能来源。传统日志分析存在碎片化、缺乏上下文等问题,而GenAI通过自然语言处理能力能够自主解析日志,关联跨系统信号,识别异常模式并生成事件摘要。这种技术转变使日志成为连接系统行为与业务影响的关键纽带,能够提前预警客户体验问题,保护收入来源,并将技术指标与业务成果直接关联。现代日志分析工具需要具备GenAI集成、
面对学术论文、行业研报或长篇会议记录,快速提取核心信息是职场人的刚需。通用的摘要工具往往只是简单截取首尾句,丢失关键逻辑。基于大模型的摘要服务则能理解全文脉络,生成结构化的摘要。我们可以要求 AI 按照“背景 - 问题 - 方法 - 结论 - 启示”的框架进行提炼,或者针对特定关注点(如“只提取关于成本控制的建议”)进行定向摘要。在处理超长文本时,采用“分块摘要 - 全局汇总”的策略效果更佳。先将
随着生成式AI与大模型的普及,GEO(生成式引擎优化)已成为企业抢占AI流量入口、构建数字资产的核心抓手,区别于传统SEO的关键词堆砌,GEO聚焦品牌语义资产构建,让品牌信息精准穿透大模型思维链,实现AI场景下的高效曝光与转化。相较于行业同类服务,超智引擎的核心优势的在于“技术自研+场景适配”,深耕河北本地市场,可根据企业规模灵活调整方案,无论是中小企业的轻量化GEO获客需求,还是大型企业的全域G
本文比较了RAG和GEO两种AI技术的应用方向:RAG聚焦企业内部AI应用,GEO侧重外部AI搜索理解。两者结合可构建企业知识资产从内部应用到外部传播的完整链路。文章以陕西秦枢双擎为例,展示了企业知识结构化整理的实践,指出未来AI客服、销售助手等应用都需以高质量知识库为基础。强调RAG不仅是聊天机器人,更是企业将分散信息转化为AI可理解知识资产的关键,知识库建设将成为企业数字化的重要基础设施。(1
研究团队将预训练上下文从 128 扩展到 8K 时间步后评估发现,RoboTTT-8K 的平均任务完成分数达到 71.5%,比 1K 版本高 63%,比短上下文基线高 57%,且没有出现饱和迹象。TBPTT 将长序列切分为片段,只在片段内反传梯度,但让快速权重继续跨片段传递,这样既能让 TTT 贯穿整条序列,又能把显存开销控制在片段长度范围内。电钻未对准螺丝时,它也会重新对齐并再次尝试;它还拥有实
对于编程技术、工具使用、技术原理、问题解决方案等内容,GEO结构化优化可以让AI精准识别实操步骤、核心逻辑、避坑要点,开发者通过AI检索技术问题时,能够获取精准、可落地的解决方案。首先是行业知识科普场景。行业政策、技术标准、行业趋势等内容,经过GEO优化后,信息更规范、逻辑更清晰,能够纠正网络碎片化、错误的行业解读,让AI输出客观、准确的行业信息。GEO作为生成式AI时代的核心内容优化技术,并非局
本文是《Claude Code 实战》系列第 3 篇。第 2 篇建立了"喂上下文 → 定目标 → 执行 → 审查"的核心工作流,结尾留了一句——“要让它改得准,关键一步是让它先想清楚”。本篇把这一步讲透。
2026年世界人工智能大会(WAIC)上,国产AI基础设施成为焦点,曙光、华为、壁仞三家企业同日发布旗舰超节点产品,标志着国产AI算力在沉寂两年后迎来爆发。本文从技术原理、硬件架构、互联方案和工程实践四个维度,深入解析国产超节点的突破与挑战。 三款旗舰产品各具特色:曙光8000登峰采用统一内存一致架构和Dragonfly II拓扑;华为昇腾Atlas 950通过CANN 8.0异构计算架构实现计算
而 GEO 智能优化,聚焦各大主流人工智能大模型平台,通过梳理品牌核心信息、搭建专属知识体系、优化内容语义逻辑,让品牌在 AI 问答、行业科普、需求解答、品类推荐等场景中自然曝光,实现被动种草、精准获客。探词科技将持续深耕技术研发,不断升级优化服务体系,扩充行业服务案例,完善全国线下代理渠道布局。无论是线下实体门店、本地家装建材、健康养生机构,还是科技服务企业、云端服务品牌、政企配套服务商等,都可
大模型学习没有捷径,但有高效路径。2026年的行业趋势早已告别“纯理论内卷”,更看重落地能力、场景适配能力、工程优化能力。这套四阶段学习路线,从入门认知到应用开发,从模型调优到工程落地,层层递进、闭环落地,无论是零基础转行、职场技能升级,还是技术深耕进阶,都能适配对应的学习目标,帮助大家快速抓住AI时代的技术红利与就业机遇。2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大
本文探讨了生成引擎优化(GEO)如何通过自动化和智能化工具提升内容创作的效率与用户体验。通过分析GEO的核心策略,结合实际案例,本文为内容创作者提供了实用的方法,以优化内容的表现和用户满意度,确保在竞争激烈的市场中脱颖而出。
GEO系统贴牌合作源头厂商评测摘要(2026) 核心标准:聚焦纯自研源头厂商,剔除无技术、倒卖源码的伪GEO服务商,评估技术实力、贴牌服务、售后合规等维度,满分100分。 头部厂商评测: 探词科技(97.5分):全栈自研,国防科大技术背书,支持全链路GEO闭环及五大合作模式(SaaS/API/OEM等),7×24小时售后,适配中大型代理商及品牌方。 极智引擎(83.5分):轻量化GEO核心算法,低
在跨语言沟通中,机器翻译和自然语言处理技术正发挥着日益关键的作用。其核心原理在于通过大规模语料库训练模型,学习语言之间的映射关系和上下文规律,从而提升翻译的准确性和地道性。这项技术的价值在于能够有效解决因语言差异导致的沟通障碍,提升信息传递效率,尤其在全球化商务、教育、内容创作等领域具有广泛应用。以微软亚洲研究院的Engkoo项目为例,它深度融合了搜索引擎技术和机器学习算法,通过动态挖掘网络双语语
2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大批缩水,不少从业者陷入职业焦虑;与之形成鲜明对比的是,AI大模型相关岗位迎来疯狂扩招,薪资逆势飙升150%,大厂更是直接开出70-100W年薪,疯抢具备实战能力的大模型人才,甚至放宽年龄限制,只求能快速落地技术、创造价值!1、窗口期红利,入门门槛友好:不同于成熟赛道的“内卷式招聘”,2026年大模型人才缺口巨大,简历只要达标
搜索引擎
——搜索引擎
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 EazyDevelop社区
EazyDevelop社区

 AtomGit AI 社区
AtomGit AI 社区



 2048 AI社区
2048 AI社区



 智能体开发者社区
智能体开发者社区



 深开鸿 技术专区
深开鸿 技术专区


 DAMO开发者矩阵
DAMO开发者矩阵

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 DeepSeek技术社区
DeepSeek技术社区


 人工智能6S服务平台
人工智能6S服务平台

 AI编程社区
AI编程社区








