登录社区云,与社区用户共同成长
邀请您加入社区
摘要:很多开发者卡在“Demo 能跑,生产就崩”的困境。本文拆解 Agent 的核心原理(规划、工具调用、记忆),结合近期大模型应用从 Demo 转向工程化的趋势,重点剖析权限边界、日志追踪与失败恢复机制。通过对比招聘 JD 中的隐性要求,给出具体的学习路径和实战建议,帮助开发者构建具备生产级健壮性的 AI 智能体。对于长对话,直接截断会导致信息丢失。策略:当 Token 接近阈值时,使用 LLM
本文探讨了AI Agent在数据库运维中的角色与边界问题。随着大模型技术的发展,运维Agent已能实现故障诊断、方案生成等自动化操作,但其通用性设计导致对特定数据库内核的理解有限,且存在安全隐患。文章提出理想架构应为"数据库-专业管控平台-Agent"三层结构,以管控平台作为核心中枢,确保数据精准度、执行安全性和系统稳定性。并以金仓KEMCC为例,展示原生管控平台在指标采集、诊
AI编程从实验室走向产业落地,依赖五大关键技术突破:1.基础模型能力提升,如超长上下文窗口和推理思维链,解决代码记忆和逻辑问题;2.工程化支撑,如基于AST的代码检索增强生成,实现精准上下文提取;3.范式转移为智能体闭环,具备工具调用、自我纠错和多文件协同能力;4.IDE深度交互创新,如行内内嵌和规则对齐;5.强化学习与测试驱动优化提升代码质量。这标志着编程从语法编写转向意图表达和架构审查的新阶段
客户日常运维执行强制终止会话后,遇到诡异现象:操作系统服务进程已经彻底消失,但gv$session中会话长期停留在KILLED状态:滞留1 小时以上无法自动清理KILLED仅为会话状态标记,资源回收由 PMON 异步执行,短时残留属于 Oracle 正常机制;进程消失、TADDR 为空、无锁、滞留超 1 小时的僵尸会话,两大核心诱因:RAC 集群 GES 全局同步阻塞 / XA 分布式事务多分支未
2、varchar和nvarchar的最大长度不一样,nvarchar的长度设置必须为1和4000之间。无论是语言的范围,和存储空间的范围,nvarchar都占有很大的优势。② 从存储量来看,varchar是比较省空间的,因为存储的大小就是字节的实际长度,而nvarchar是。1、varchar是非Unicode可变长度类型,nvarchar是Unicode可变长度类型。nvarchar能存储的字
国内数据库领域取得重要进展:NineData云原生智能数据管理平台V5.0与崖山数据库YashanDB V23完成兼容性认证,实现全链路研发管理支持。YashanDB作为完全自主的国产数据库,性能超越国际主流产品50%,已在金融、政务等领域核心系统替代国外产品。NineData作为新一代智能数据管理平台,通过AI驱动提供数据库全生命周期管理能力。此次适配将显著提升企业三方面价值:研发效率(统一SQ
本文介绍了GaussDB数据库的逻辑备份工具gs_dump和gs_restore的使用方法。逻辑备份可备份表、视图、索引等数据库对象,支持纯文本、自定义归档等四种格式。文章详细说明了备份整个库、特定schema或表的命令示例,并演示了如何通过gs_restore恢复数据库、schema或表数据。这些工具在数据迁移、测试环境搭建等场景中非常实用,特别是分布式环境下重新定义分布键时。备份时可通过参数控
最近团队里在推 Claude Code 和 Codex 这种 Agentic 编程工具,刚开始大家挺兴奋,觉得“以后不用写 Boilerplate 了”。但跑了一周真实业务线后,我反而更焦虑了。很多开发者简历上堆满了 Agent 的 Demo,面试时侃侃而谈 LangGraph 的多智能体协作,可一旦问起“权限怎么隔离”、“日志怎么审计”、“失败怎么兜底”,基本就露馅了。我们要认清一个事实:能跑通
它把AI智能体的开发门槛降到了前所未有的低度——不需要你是深度学习专家,甚至不需要会写太多代码,就能通过可视化工具和API快速造出有用的“AI小助手”。最后,我想说:别被“ORACLE”这个老牌公司吓到,它的免费智能体工厂就像是一个给了你锤子和图纸的智能工坊。ORACLE的智能体工厂,就是把这些能力封装成服务,让你通过拖拽式界面或API调用,快速组装出属于自己的“AI小助手”。今天,我们要聊聊一个
在Linux平台中,为了避免在KingbaseES运行中出现由于操作系统设置不当从而导致系统异常的问题,产品为用户提供了一键式修改操作系统参数脚本。enhance_os_param.sh脚本主要修改了以下操作系统配置内容。${_target_user}为数据库部署用户。登录数据库服务器,执行以下命令。
本文探讨了使用Codex进行数据库迁移时需要注意的关键问题。文章指出,真正的风险不在于SQL编写能力,而在于迁移方案是否具备可回滚性、历史数据兼容性以及生产环境安全性。作者以新增订单字段为例,建议先让Codex分析影响范围而非直接执行,重点关注接口影响、数据兼容、索引优化等要素。文章提出了安全迁移的六个要点:影响范围分析、回滚脚本准备、生产环境隔离、历史数据处理、迁移后验证流程,以及何时考虑升级P
先把这篇文章的目标说清楚:看完之后,你应该能判断这件事值不值得做,以及从哪里动手。最近 Codex 和 Claude Code 在开发者圈子里火得一塌糊涂,很多团队开始尝试让 AI 编程工具从个人试用走向团队协作。表面上看,这似乎是生产力的飞跃,但我在几个项目的联调复盘中发现了一个尴尬的现实:代码生成得再快,一旦涉及企业关键知识库的复杂查询,系统就崩了。以前做 RAG(检索增强生成),我们头疼的是
Floor插件为Flutter应用提供SQLite数据库ORM支持,通过注解简化开发流程。文章详细介绍了Floor的环境搭建(需Flutter SDK≥3.7.0和OpenHarmony API 9+)、自定义依赖引入方式,以及核心API使用规范。主要内容包括:实体类定义(@entity注解)、数据访问对象DAO设计(@dao注解)、数据库配置(@Database注解)和代码生成流程(build_
✅ 规范的数据库初始化流程✅ 安全的版本升级机制✅ 完善的事务回滚保护✅ 合理的索引优化策略相关资源鸿蒙学习资源。
【代码】鸿蒙-数据持久化-键值对数据库。
【代码】鸿蒙数据库操作。
当应用在处理一项重要的操作,显然是不能被打断的。例如:写入多个表关联的事务。此时,每个表的写入都是单独的,但是表与表之间的事务关联性不能被分割。
为了增强数据库的安全性,数据库提供了一个安全适用的数据库加密能力,从而对数据库存储的内容实施有效保护。通过数据库加密等安全方法实现了数据库数据存储的保密性和完整性要求,使得数据库以密文方式存储并在密态方式下工作,确保了数据安全。
《AI问答系统选型指南:技术问答与普通问答的模型差异与集成方案》 核心摘要: 技术问答与普通问答存在本质差异,前者对术语精度、上下文长度和推理深度要求更高。实测表明,单一模型无法兼顾所有场景,多模型集成成为趋势。作者对比了三类集成方案:1)自研搭建(可控但成本高);2)开源UI部署(灵活但维护难);3)第三方聚合平台(省心但覆盖有限)。其中kulaai平台在模型覆盖、国内访问和场景适配方面表现突出
如何解决
引用一、显式cursor显式是相对与隐式cursor而言的,就是有一个明确的声明的cursor。显式游标的声明类似如下(详细的语法参加plsql ref doc ):cursor cursor_name (parameter list) is select ...游标从declare、open、fetch、close是一个完整的生命旅程。当然了一个这样的游标是可以被多
以下摘自百度:1.检查数据库中的 OPEN_CURSORS 参数值。 Oracle 使用 init.ora 中的初始化参数 OPEN_CURSORS 指定一个会话一次最多可以拥有的游标数。缺省值为 50。要获得数据库中 OPEN_CURSORS 参数的值,可以使用以下查询:SQL> show parameter open_cursors; NAME
无论是硬解析,软解析还是软软解析,ORACLE在解析和执行目标SQL时,始终会先去当前SESSION的PGA中寻找是否存在匹配的缓存Session Cursor.
procedure系列Oracle存储过程和自定义函数Oracle-procedure解读procedure概述存储过程( Stored Procedure )是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是由流控制和 SQL 语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,应用程序使用
作者: 三十而立时间:2009年9月09日 11:56:31本文出自 “inthirties(三十而立)”博客,转载请务必注明作者和保留出处http://blog.csdn.net/inthirties/archive/2009/09/09/4537190.aspx 有csdn的朋友问到 open_cursor 和 v$open_cursors的区别这样的问题 SQL> select c
数据库性能缓慢,大量的cursor:pin s wait x ,library cache lock以及log file switch(checkpoint incomplete),db file async I/Osubmit等待。
Oracle中为了提高sql的执行效率,需要减少硬解析,实现shared cursor共享,最常见的方法是使用绑定变量,但很多时候由于各种原因未能在开发初期使用绑定变量,对于减少硬解析的目的,退而求其次地方法是设置cursor_sharing.
这个值越接近100%越好 (即Parses/Executions越接近0,也即几乎所有SQL都是已经解析过的,只要执行就好了,当然这是理想状态)。SQL语句执行与解析的比率。比如12.26%说明,同 一个session中执行的SQL语句中只有12.26%的SQL是已经解析好了的(不需要再次解析)。正确设置open_cursors和'session_cached_cursors'可以减少sql解析,
oracle 问题:PLS-00402: alias required in SELECT list of cursorto avoid duplicate column说明selec部有重复的别名
昨天使用 Data Block 操作 oracle 返回 cursor 。期间产生了一点问题,很是郁闷,找了一下午也没有解决。早上睡不着,起来继续找。结果找到了解决的方法。其实也是怪自己没有很好的看文档。在此记录一下。以使别的同志再出现我的问题的时候,很容易的找到解决的方法。问题是这样的:我在oracle里面有这样一个过程PROCEDURE ListAllStatic_Users (cur_Sta
关于oracle 存储过程游标cursor和循环loop使用
嵌入模式将大模型作为后台组件集成到现有应用或服务中,增强其智能化能力,但不直接向用户暴露全部功能。其核心目标是提升现有系统的效率和用户体验。
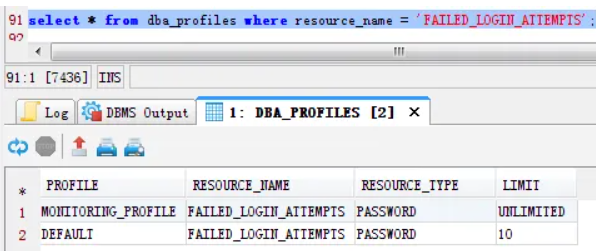
Oracle 数据库用户锁定与解锁,用户锁定最大密码失败次数设置方法,ORA-28000: the account is locked问题解决方法
判断update语句执行是否有更新到python cx_Oracle...省略...cx_Oracle...upsql = "UPDATE C_GSMC_SPIDER t SET t.AQC_ID = :AQC_ID WHERE t.GSMC = :GSMC"self.cursor.prepare(upsql)self.cursor.execute(None, {'AQC_ID': item['A
--游标select产生结果集,游标就是该结果集上的指针,类似java迭代器Iteratordeclarecursor c is select ...;xx(变量) c%rowtype;beginopen c;fetch c into xx(变量);close c;--循环取游标f for循环最简单不容易出错loopexit when(c%notfoun...
cursor_sharing的妙用<br />Oracle2009-12-28 10:17:16阅读100评论0 字号:大中小 订阅<br />OLTP系统中,我们总是希望使用绑定变量将sql语句共享在library cache中,Oracle将根据LRU算法将该语句的相关信息保存在library cache中,这样只有在sql语句第一次被加载时会发生hard parse,之后如果sql语句在l
概图:1 显式cursor显式是相对与隐式cursor而言的,就是有一个明确的声明的cursor。显式游标的声明类似如下 :cursor cursor_name (parameter list) is select ...游标一个完整的生命周期:declare->open->fetch->close游标是可以被多次open进行使用的显式cursor是静态cursor,作用域是全局
前言 今天在看项目代码的时候发现cursor循环中用到了Exit、Continue、Return控制语句,同印象中的有点出入,做个小实验验证下。示例代码DECLARETYPE cursors IS REF CURSOR;CUR_ONECURSORS;CUR_TWOCURSORS;V_LEVEL_ONE NUMBER;V_LEVEL_TWO NUMBER;BEGINOPEN CUR_ONE FOR
在Oracle存储过程中,FOR循环的使用并不一定需要显式游标。Oracle提供了三种主要的FOR循环方式:显式游标FOR循环、隐式游标FOR循环和数值FOR循环。显式游标FOR循环需要事先声明游标,适用于需要在多个地方重复使用或需要复杂控制的场景。隐式游标FOR循环更为简洁,适用于遍历查询结果。数值FOR循环则适用于简单的数值迭代。建议在大多数情况下使用隐式游标FOR循环,因其代码更简洁;仅在需
执行sql语句时报 ORA-01000 maximum open cursors exceeded 的问题和解决方案
/*注意:在使用游标作为返回值时,要注意再动态绑定时打开游标,然后返回。在使用时直接使用游标,不需要再次打开,故而只能使用传统的open/close方式来使用游标,for循环使用游标时,会牵扯到打开游标,会出现重复打开的错误,所以不能使用。*/–在过程中返回类型为游标变量类型CREATE OR REPLACE PROCEDURE findset_emp
oracle open_cursors参数配置查看游标打开最大值设置SQL> show parameter open_cursors;oracle 默认open_cursors 为300设置open_cursors值alter system set open_cursors = 1000;alter system set open_cursors = 1000 scope = spfile;
一. Cursor说明 Oracle里的cursor分为两种:一种是shared cursor,一种是session cursor。 1.1 Shared cursor 说明 sharedcursor就是指缓存在librarycache(SGA下的Sha
总共介绍两种游标一种高效使用游标cursor 、sys_refcursor、 bulk collect 1、cursor游标使用/*简单cursor游标*students表里面有name字段,你可以换做其他表测试*/--定义declare--定义游标并且赋值(is 不能和cursor分开使用)cursor stus_cur is select *
oracle
——oracle
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 CSDN-OPC开发者社区
CSDN-OPC开发者社区


 智能体开发者社区
智能体开发者社区


 AI编程社区
AI编程社区


 openEuler 社区
openEuler 社区

 深开鸿 技术专区
深开鸿 技术专区


 2048 AI社区
2048 AI社区


 华为开发者空间
华为开发者空间





 HarmonyOS开发者社区
HarmonyOS开发者社区







 AtomGit AI 社区
AtomGit AI 社区