登录社区云,与社区用户共同成长
邀请您加入社区
多个应用程序之间有依赖关系,后一个程序需要依赖前面的程序的结果。时至今日,MapReduce是Apache Hadoop的核心模块之一,是运行在HDFS上的。如果负责计算的电脑挂掉了,可以将任务转移到其他电脑上,任务不会执行失败的。代码写起来有固定的格式,编写难度非常的小,号称是八股文【固定写法】。计算的时候,使用的资源如何协调(Windows操作系统)数据因为都是静态的,不是边产生数据,边计算。
Map阶段:核心是“拆分数据,提取key-value”;Shuffle阶段:无需编码,但需理解其“分组排序”作用(避免数据倾斜);Reduce阶段:核心是“聚合计算,输出结果”;实战技巧:通过Context传递数据,通过处理初始化/收尾工作。
PowerJob深度解析:DAG工作流与MapReduce分布式计算 PowerJob作为第三代分布式任务调度框架,通过DAG工作流和MapReduce计算模式实现复杂业务场景的高效处理。其DAG引擎支持任务节点、判断节点和嵌套工作流节点,提供可视化编排与跨节点数据传递能力。MapReduce模式则实现动态任务生成和结果聚合,相比传统分片方式具备更强的分布式计算能力。框架采用无锁化调度设计,单机可
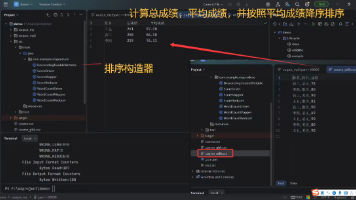
姓名 总成绩 平均成绩王五 261 87.00张三 258 86.00李四 229 76.33结果分析王五:数学81 + 语文90 + 英语90 = 261,平均87.00张三:语文78 + 英语90 + 数学90 = 258,平均86.00李四:数学80 + 语文69 + 英语80 = 229,平均76.33Mapper阶段:将输入数据解析为键值对Shuffle阶段:系统自动对键进行排序和分组R
本文介绍了一个基于MapReduce+Spring Boot+Vue的奶茶销售数据分析平台。该平台采用Hadoop MapReduce处理31,895条奶茶销售数据,通过Spring Boot提供API接口,Vue.js结合ECharts实现可视化展示。系统从CSV数据源提取18个字段,包括订单、用户、城市、品牌等信息,通过MapReduce实现多维度分析(如年龄段品牌购买统计)。核心代码展示了数
本文介绍了一个基于大数据技术的肥胖风险数据分析系统。系统采用Hadoop+Hive构建大数据处理层,实现数据采集、清洗和存储;使用SpringBoot搭建后端服务层,提供数据接口;通过Vue.js开发前端展示层,结合ECharts实现可视化分析。项目采用数据仓库分层架构(ODS/DWD/DWS/ADS),设计了多维度分析表结构,包括肥胖趋势、风险因素等核心功能。系统通过MapReduce进行数据清
摘要:MapReduce是Hadoop的核心计算框架,用于并行处理大规模数据。其核心思想分为Map、Shuffle和Reduce三个阶段,通过分布式计算实现高效处理。优点包括易于编程、高容错性和可扩展性,但存在计算耗时、流式计算能力弱等不足。开发过程涉及InputFormat数据切片、Mapper任务执行、Partitioner分区、环形缓冲区溢写以及Reduce聚合等关键环节。可通过调整Redu
本文介绍了一个基于Hadoop+HBase+Spring Boot+Vue的天气数据分析与可视化系统。系统采用Hadoop分布式计算框架处理海量天气数据,使用HBase进行高性能存储,通过Spring Boot构建RESTful API服务,并利用Vue.js+ECharts实现数据可视化。核心功能包括:数据采集存储、MapReduce数据分析(温度、湿度、风速等多维度分析)、RESTful AP
本文介绍了一个基于Hadoop MapReduce、Spring Boot和Vue 3的每日饮水数据分析平台。该平台采用前后端分离架构,实现了从数据采集、MapReduce分析处理到可视化展示的完整流程。系统分析个体每日饮水量与年龄、性别、体重、活动水平和天气等多因素的关系,提供6种数据分析维度。技术栈包括Hadoop 3.3.4进行大数据处理,Spring Boot 2.7.18提供RESTfu
本文系统介绍了大数据离线计算的核心技术。MapReduce作为底层引擎,解决了海量数据批处理问题,重点剖析了其工作原理、关键组件和适用场景。Hive和Pig作为上层工具,分别通过SQL和数据流脚本简化开发:Hive适合统计分析场景,Pig擅长ETL流程处理。文章通过WordCount示例详解MapReduce编程模型,并提供了Hive/Pig的典型应用案例。最后总结了常见实践建议,如合理使用Com
Override// 根据单词首字母分区} else {return 0;// 其他字符统一分区// 在Job中设置自定义分区器// 自定义数据类型实现WritableComparable@Override// 先按年龄排序,再按姓名排序= o.age) {// 年龄升序} else {// 姓名升序// 或者继承WritableComparator@Override// 自定义分组比较器@Ove
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
Hadoop 学习笔记 ---> hadoop概述,hadoop架构,hadoop运行环境搭建
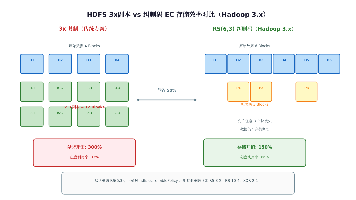
海量数据存储海量数据计算资源调度由 YARN 负责,Common 提供底层工具支持。Hadoop 的设计哲学很简单:用廉价的普通机器组成集群,通过横向扩展来扛住 PB 级别的数据。当前生产环境主流是3.x系列(最新稳定版3.4.2,2025 年 8 月发布)。最低 JDK 要求:3.x 最低 JDK 8,低于这个版本的编译和运行都不支持HDFS 纠删码:默认支持 Erasure Coding,存储
本文详细介绍了Hadoop HDFS的核心参数配置、集群性能优化及故障处理方法。主要内容包括:1)NameNode内存配置与心跳并发优化;2)HDFS集群压测方法,包括读写性能测试;3)集群扩容缩容操作,如白名单/黑名单管理、数据均衡;4)存储优化方案,如纠删码和异构存储技术;5)常见故障排查指南;6)MapReduce性能调优参数;7)小文件处理策略。通过实际案例展示了从1G数据统计词频的完整调
系统梳理大数据三类计算引擎(批处理 / 流处理 / 查询)的边界与职责,并深入对比 Hive 支持的 MapReduce、Tez、Spark 三种执行引擎的原理、优缺点与工程选型建议。
ApplicationMaster:单个Job在运行在YARN上时,启动一个当前job的AppMR,这个进程负责这个Job所有Task资源申请,以及状态检测,容错。Container:计算资源的抽象表达,一个Container中封装了若干计算资源,例如,CPU,内存。ResourceManager:(1个)资源管理者:负责整个集群中所有节点资源的管理和调度。NodeManager:(N个)节点资源
hadoop mapreduce python
Spark的Scala API通过函数式范式大幅提升开发效率,而MapReduce的Java API更适用于特定底层优化场景。现代数据架构中,Spark逐渐成为主流选择,但MapReduce在超大规模纯批处理任务中仍有价值。)链式调用,类型自动推断,代码简洁性提升约60%。形式传递,需手动处理类型转换。(需手动优化分区策略)。强制用户将逻辑拆分为。
与之形成鲜明对比的是C++的显式内存管理,其通过智能指针(如std::unique_ptr)与RAII模式,在保持全手动控制可能性的同时,提供了一套结构化的资源管理机制,这使得在嵌入式系统等内存受限的场景中仍能保持开发效率。对比之下,C#在开发效率与执行效能间实现了独特的平衡:借助Roslyn编译器作为服务技术,其TypeScript-like的实时编译反馈与LINQ查询语法,在保持接近Pytho
本文将通过系统化的方式,从语法基础到实战优化,手把手带领读者突破认知壁垒,掌握高性能C++开发的核心技术。掌握这份从语法底层到系统架构的完整技术栈,开发者就能构建出可在百万级QPS下稳定运行的分布式系统,或是在移动设备上流畅运行的高性能游戏引擎。好的,我将按照您的要求撰写一篇从C++基础语法到高性能开发实战的深度原创文章。
本文结合《C++编程艺术语法规则深度解析与高效开发实战》的核心思想,用“问题-方法-案例”的结构,手把手教你如何快速掌握C++语法精髓、设计高效代码,并在实战中避免踩坑。- 应用场景:通过`std::enable_if`、`static_assert`实现条件编译,提高代码复用性。- 避免共享可变状态,优先使用互斥量`std::mutex`或原子操作`std::atomic`。- 解决方案:用`s
摘要: DeepSeek技术方案评审聚焦架构设计、性能优化、安全性等核心维度。当前分层微服务架构具备模块解耦和弹性伸缩优势,但存在同步调用阻塞、状态管理缺失等问题,建议引入异步队列和状态服务。性能方面,动态模型加载和批处理可降低延迟并提升GPU利用率。安全需强化数据加密与模型防投毒机制。成本优化建议弹性资源调度和存储分层,预计节省57%存储开支。改进优先级:短期实现异步化与加密,中期完善监控与契约
摘要:DeepSeek与PowerBI深度整合实现了数据智能分析全流程优化。AI脚本引擎可自动生成多源数据接入代码(SQL/API/ETL),将数据准备时间缩短82%。可视化系统通过决策树算法($$\DeltaE$$色差公式)智能匹配图表类型,并生成色盲友好方案。DAX度量值优化使计算效率提升19%,增量刷新SQL降低90%处理时间。行业模板库覆盖金融风控、制造OEE等场景,支持自然语言转技术指令
1.写出“whatever worth doing is worth doing well.”的map和reduce阶段的输入、输出,简述shuffle过程,以及说明如何确保相同单词进入一个reducer中。hadoop的伪分布中名称节点和数据节点可以在一个物理节点上()6 Map任务的数量和reduce任务的数量由什么决定。数据分为 结构化数据、半结构化数据和()第二名称节点解决了单节点错误的问
什么是MapReduceMapReduce是分布式计算框架,它将大型数据操作作业分解为可以跨服务器集群并行执行的单个任务,适用于大规模数据处理场景,每个job包含Map和Reduce两部分MapReduce的设计思想分而治之:简化并行计算的编程模型构建抽象模型:Map和Reduce隐藏系统层细节:开发人员专注于业务逻辑实现MapReduce特点优点:易于编程可扩展性高容错性高吞吐量缺点:难以实时计
胖东来销售数据分析系统摘要 该项目构建了一个完整的零售大数据分析平台,采用Lambda架构整合MapReduce批处理与Spring Boot+Vue.js实时可视化。系统提供10个核心分析维度,包括销售总额、商品类型、促销效果、区域销售等,通过Hadoop处理海量销售数据,并以交互式图表展示分析结果。关键技术包括:多维度MapReduce计算、CSV数据解析、UTF-8中文处理、前后端分离架构以
期末复习的时候找到了前辈的博客。受到了很大帮助。希望这篇文章也能给学弟学妹们参考。
【大数据入门笔记系列】第六节分布式计算框架MapReduce的工作原理MapReduce分布式运算MapReduceApplicationMapReduce分布式运算MapReduce分布式运算程序至少分成两个阶段:第一阶段各个节点独立完成所分得的计算任务,这个时候各节点保持着并发运行,这便是Map阶段;第二阶段就是统计第一阶段的结果,统计实例根据统计内容可以为多个(有些统计只能有一...
本文全面介绍了DolphinDB分布式计算技术,包括其核心原理、MapReduce模式、分布式聚合、JOIN操作以及优化策略。分布式计算通过将任务分散到多个节点并行执行,实现高效的数据处理。DolphinDB提供自动分区、调度和结果合并功能,支持透明访问。文章详细讲解了Map阶段的数据分片并行计算和Reduce阶段的结果合并,并展示了丰富的代码示例。此外,还涵盖了分区裁剪、数据本地性等优化技术,帮
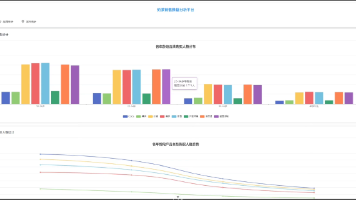
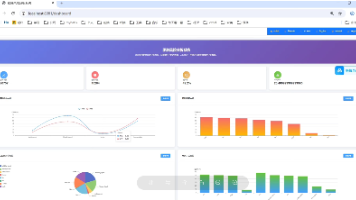
本项目开发了一个基于大数据技术的地铁数据分析系统,采用MapReduce进行海量数据处理,Spring Boot构建RESTful API服务,Vue.js实现交互式可视化界面。系统实现了11个维度的地铁客流分析,包括线路客流、站点热度、高峰时段识别等核心功能。关键技术包括:MapReduce批量处理原始数据,Spring Boot提供数据分析API接口,Vue.js结合ECharts实现丰富的数
MapReduce 是一种编程模型(没有集群的概念,会把任务提交到 yarn 集群上跑),用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
分布式计算框架MapReduce一、MapReduce概述 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。1、为什么要MapReduce 1)海量数据在单机上处理因为硬件资源限制,无法胜任 2...
1.什么是分布式计算在计算机科学中,分布式计算(英语:Distributed computing,又译为分散式计算)这个研究领域,主要研究分散系统(Distributed system)如何进行计算。分散系统是一组电子计算机(computer),通过计算机网络相互链接与通信后形成的系统。把需要进行大量计算的工程数据分区成小块,由多台计算机分别计算,在上传运算结果后,将结果统一合并得出数据结论的
上节我们已经成功配置并启动了hadoop集群,1台namenode节点,2台datanode节点,接下来我们就利用hadoop大杀器,使用HDFS和Mapreduce1、测试HDFS的功能我们先上传一个文件到HDFS,先查看software目录里面有我们之前配置java的jdk包,我们就上传这个文件,输入hadoop可以查看帮助信息,看到有fs我们再输入hadoop fs,可以看到有很多命令可用,
重点盯着位置向量的z分量和旋转矩阵的第三列,这些往往包含最简形式的关节角组合。记住,解逆解就像拆俄罗斯套娃,解出一个关节就把它代入下一个方程,直到所有关节都被扒光——呃,是被解算出来。解出来的q1可能有两个解,对应机械臂的肘部上/下两种构型。传统方法不是几何法就是代数法,今天咱们玩点实在的,用Matlab符号计算暴力拆解六轴串联机械臂的逆解。如果出现厘米级误差,八成是哪个关节的pi符号处理漏了,检
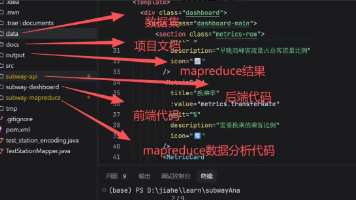
mapreduce
——mapreduce
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 AI编程社区
AI编程社区














 AI Agent技术社区
AI Agent技术社区



 DAMO开发者矩阵
DAMO开发者矩阵