- @youmaob
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ReAct框架为高性能AI智能体的研发搭建了扎实的底层基础,它从根本上改变了大型语言模型的定位,让原本只能被动应答的静态知识库,升级为能够主动联动外部环境、落地执行任务的智能执行者。深入吃透ReAct的核心原理,正视它现阶段的短板与不足,也是我们研发通用型人工智能,迈向更高智能化阶段的关键一步。
ReAct框架为高性能AI智能体的研发搭建了扎实的底层基础,它从根本上改变了大型语言模型的定位,让原本只能被动应答的静态知识库,升级为能够主动联动外部环境、落地执行任务的智能执行者。深入吃透ReAct的核心原理,正视它现阶段的短板与不足,也是我们研发通用型人工智能,迈向更高智能化阶段的关键一步。
ReAct框架为高性能AI智能体的研发搭建了扎实的底层基础,它从根本上改变了大型语言模型的定位,让原本只能被动应答的静态知识库,升级为能够主动联动外部环境、落地执行任务的智能执行者。深入吃透ReAct的核心原理,正视它现阶段的短板与不足,也是我们研发通用型人工智能,迈向更高智能化阶段的关键一步。
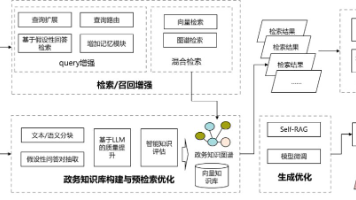
在当今数字化时代,智慧城市的建设和人工智能技术的飞速发展已成为推动社会进步和提升治理效能的关键力量。政务智能化作为智慧城市的核心组成部分,不仅关乎政府服务的质量和效率,更直接影响着居民的获得感和满意度。在这一背景下,如何确保政务领域的智能化水平始终保持领先地位,已成为具有深远战略意义的重要课题。近年来,大语言模型(LLM)在多个领域展现出卓越的能力,其强大的语义理解、文本生成和知识整合能力为政务领
2026年,掌握AI智能体开发成为大模型开发求职的核心加分项。本文提供了一套分层递进的AI Agent系统化学习路径,分为四大阶段:提示词与LLM调用、ReAct到LangChain框架学习、记忆与外部工具、多智能体协同开发。涵盖提示词工程、大模型API对接、ReAct推理模式、LangChain/LangGraph开发、记忆系统、工具开发及多智能体框架等核心内容,并配套4个实战项目,助新手稳步掌

2026年,掌握AI智能体开发成为大模型开发求职的核心加分项。本文提供了一套分层递进的AI Agent系统化学习路径,分为四大阶段:提示词与LLM调用、ReAct到LangChain框架学习、记忆与外部工具、多智能体协同开发。涵盖提示词工程、大模型API对接、ReAct推理模式、LangChain/LangGraph开发、记忆系统、工具开发及多智能体框架等核心内容,并配套4个实战项目,助新手稳步掌
先看Addy原文给的定义。循环工程是指,不再由你亲自去 prompt Agent,而是设计一个系统来替你 prompt。可以把循环理解为一个递归目标:你定义目的,AI 反复迭代直到完成。它大致由五个构建块组成——Claude Code 和 Codex 现在都有了这五块。Loop Engineering 的核心思想是:不要再亲自去 prompt Agent。设计一个系统,让系统替你去 prompt
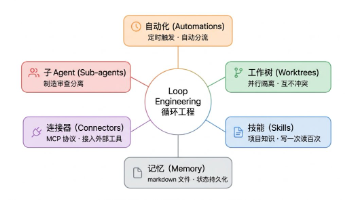
先看Addy原文给的定义。循环工程是指,不再由你亲自去 prompt Agent,而是设计一个系统来替你 prompt。可以把循环理解为一个递归目标:你定义目的,AI 反复迭代直到完成。它大致由五个构建块组成——Claude Code 和 Codex 现在都有了这五块。Loop Engineering 的核心思想是:不要再亲自去 prompt Agent。设计一个系统,让系统替你去 prompt
本文分析了AI行业的现状,指出虽然微软等大厂在裁员,但英伟达等公司在AI领域疯狂扩招,尤其是具身智能等方向。AI行业正在经历换血,旧岗位被淘汰,新需求涌现。普通人转行进入AI领域,大模型应用开发是一个务实且性价比高的选择,因为门槛相对较低,市场需求量大,薪资水平可观。文章鼓励读者抓住机会,通过学习大模型应用开发技能,在AI浪潮中找到自己的位置。据财联社消息显示,英伟达的机器人团队放开招聘了,围绕具

本文介绍了AI大模型训练师这一新兴职业,指出其工作内容主要涉及数据整理标注、AI输出结果测试优化等,工作门槛不高,无需复杂编程或算法基础,适合零经验者入行。该岗位薪资待遇优厚,最高可达45万,且职业发展路径清晰,可向AI评测、产品经理等多个方向发展。随着AI技术的快速发展,该岗位需求旺盛,是职场人入局AI领域的理想选择。据报道,有知情人士透露,腾某讯正在秘密为其微信应用开发人工智能助手。图片来源网