登录社区云,与社区用户共同成长
邀请您加入社区
在生成式AI深度嵌入信息获取链条的今天,AI如何回答关于品牌的问题,直接决定了潜在客户的认知与决策。
在电商、招聘、内容管理等系统中,用户往往只在一个搜索框里输入关键词,期望系统同时搜索多个字段,并且容忍拼写错误。这就是「全局模糊查询」。💡 一句话定义全局模糊查询 =多字段搜索模糊匹配(容错拼写)相关度排序默认的<mark>标签样式可能不够好看。# 在 query 的 highlight 部分修改标签},# 使用带 CSS 样式的 span 标签'>"],# 要求字段高亮,即使没有匹配也返回有时
公共部门数据面临孤岛化、质量不一和系统陈旧等挑战,阻碍AI技术的有效应用。Elastic提出以数据网格(datamesh)和语义搜索为核心的新方法,通过理解查询意图而非关键词,在严格合规下实现跨部门数据整合。语义搜索结合生成式AI(GenAI)和检索增强生成(RAG)技术,为教育、医疗、交通和劳动力发展等领域提供精准洞察:如学生个性化学习、医生临床决策支持、实时交通调度及职位智能匹配。该方案支持离
一份基于对 685 名公共部门受访者调查的最新 IDC Spotlight 报告发现,72% 的受访者认为,将 AI 从试点扩展到生产环境 “非常困难” 或 “有些困难”。¹ 选择合适的模型只是挑战的一部分。政府机构还需要为 AI 做好数据准备。成功应用 AI 的政府机构正在构建一个受治理的检索层,通常称为下一代联邦知识访问,它能够将权威知识连接到 AI agents,同时保持数据主权、可审计性以
《Git Worktree:多任务并行开发的提效神器》 本文通过一个电商开发的真实场景,介绍了Git Worktree这一高效工具如何解决传统分支切换的痛点。文章包含以下核心内容: 传统开发痛点:描述了开发者在处理紧急bug时面临的分支切换困扰,包括未完成代码的保存、上下文丢失等问题。 Worktree原理:通过图表展示了多工作树共享同一.git仓库的结构,每个工作树拥有独立目录和分支,互不干扰。
【摘要】生成式AI正在重新定义日志数据的价值,将其从被动的故障排查工具转变为主动的业务智能来源。传统日志分析存在碎片化、缺乏上下文等问题,而GenAI通过自然语言处理能力能够自主解析日志,关联跨系统信号,识别异常模式并生成事件摘要。这种技术转变使日志成为连接系统行为与业务影响的关键纽带,能够提前预警客户体验问题,保护收入来源,并将技术指标与业务成果直接关联。现代日志分析工具需要具备GenAI集成、
预算中心是记账应用的财务管家——用户设置月度预算后,应用自动统计本月支出,实时展示已用/剩余/进度条,超支时红警提醒。本章封装 BudgetCard、ProgressBar 两个核心组件,集入 BudgetRepository 完成数据闭环,并通过实现预算设置对话框。开发 BudgetView 完整页面(预算卡 + 进度条 + 超支提醒 + 收支概览)封装 BudgetCard 展示预算详情(on
本文是《Claude Code 实战》系列第 3 篇。第 2 篇建立了"喂上下文 → 定目标 → 执行 → 审查"的核心工作流,结尾留了一句——“要让它改得准,关键一步是让它先想清楚”。本篇把这一步讲透。
可按需加载、可复用的模块化指令包,支持斜杠命令/skillname手动唤起,也可由模型自动调用。SKILL.md,支持放在项目目录或插件内。独立隔离的 AI Agent 实例,拥有独立上下文窗口、独立系统提示、独立工具权限;主 Agent 可以委派任务给它。类比:主工程师把专项任务外包给独立实习生,实习生独立干活,只返回最终摘要,不污染主对话上下文。Anthropic 开源双向标准化协议Claud
账单积累到几百条后,搜索与筛选成为必备功能。HarmonyLedger 搜索页支持四种筛选条件组合:关键字(备注模糊匹配)、分类(多选)、日期范围(起止)、金额范围(最小最大)。本章封装 SearchBar 组件并扩展 BillRepository 的复合查询。封装 SearchBar 通用搜索栏(输入 + 清除 + 提交)开发 SearchView 支持四维筛选条件扩展 BillReposito
账单的编辑与删除是记账应用的基础功能。删除是不可逆的敏感操作,必须有二次确认 + 滑动手势 + 长按菜单多重入口,避免误触。本章开发 EditBillView 完整编辑页,并封装 ConfirmDialog 删除确认对话框。开发 EditBillView 完整编辑页面(复用 AddBillView 组件)实现长按列表项弹删除菜单实现左滑删除手势 + 红色删除按钮揭示封装 ConfirmDialog
账单的日期与时间是统计分析的基础维度。如果不统一封装,每个页面各弹一次原生 Dialog、各写一份格式化代码,最终会变成维护灾难。本章封装 DateSelector、TimeSelector、MonthSelector 三个选择器,集入 AddBillView 与后续统计页。封装 DateSelector 集成 DatePickerDialog封装 TimeSelector 集成 TimePick
BillCard是记账应用使用频率最高的组件——首页列表、搜索结果、分类详情、统计明细都要用它。如果每次都复制一份代码,后期维护成本巨大。企业级项目必须一次封装、处处复用。完善 BillCard 组件支持分类图标与备注通过@Prop暴露完整接口添加长按手势回调(长按弹出删除菜单)集成主题系统响应深色模式编写组件自验证用例企业级核心原则:公共组件必须接口稳定、样式独立、可测试。参考ArkUI 组件开
本文摘要: 基于随机森林算法的汽车销量分析系统研究 随着汽车市场竞争加剧,传统销量分析方法难以应对复杂多变的市场环境。本研究提出基于随机森林算法的汽车销量智能分析系统,利用其集成学习优势处理多维非线性数据。系统采用Java+SpringBoot+MySQL技术栈开发,实现了销量预测、特征重要性分析等功能界面。测试结果表明,系统能有效整合宏观经济指标、市场因素等多维数据,提供精准销量预测和关键因素分
本文介绍了如何使用Terraform全生命周期管理Elastic异常检测(AD)作业,包括作业配置、数据馈送和环境晋升。通过模块化设计,将AD作业、数据馈送和运行状态分离管理,实现配置变更与运维操作解耦。文章详细说明了Terraform代码结构、资源依赖关系,以及如何通过变量修改实现环境晋升,并提供了GitHub示例代码。关键优势包括:版本控制、审查流程、自动化部署和销毁,以及将现有作业导入Ter
Elastic Workflows 9.5版本推出AI驱动的自动化工作流生成功能,用户只需用自然语言描述需求,系统即可生成可编辑、可运行的YAML工作流。新版本支持Slack人机协同、并行执行及10个新连接器,同时提供版本控制、可视化编辑和审计功能。YAML的结构化特性使AI能精准生成有效工作流,并支持人工审核后执行。其他亮点包括事件触发器、token用量统计及三种并发控制策略,显著提升从构思到部
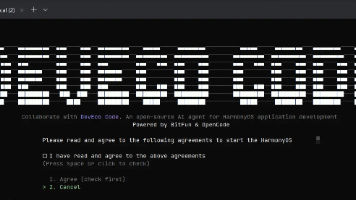
本文指导大家如何在通过 DevEco Code中使用SKILL.md 定义可复用的行为。Skill技能让 DevEco Code 能够从你的仓库或主目录中发现可复用的指令。技能通过原生的skill工具按需加载——代理可以查看可用技能,并在需要时加载完整内容。
本文是《Claude Code 实战》系列第 2 篇。第 1 篇讲了 Claude Code 的定位——它不是补全插件,而是一个能在终端里读写文件、执行命令、自主推进任务的 AI agent。本篇解决更实际的问题:怎么和它配合,才能稳定、可控地完成一次真实开发任务。
本文基于一个真实项目复盘,探讨将 Codex 接入团队开发流程后的实际效果。重点分析了权限与日志管理在 AI 编程工具落地中的关键作用,并结合实际案例给出了具体的实施建议和团队使用指南。通过这个项目复盘,我们发现将 Codex 接入团队开发流程后,虽然初期遇到了一些挑战,但通过完善权限与日志管理,最终实现了预期的效率提升。Codex 作为一个辅助工具,能够显著提高开发效率,但其效果依赖于团队的管理
底导航 Tab 是移动应用的核心导航模式,用户 80% 的操作都从底导航发起。HarmonyLedger 规划四个主 Tab:首页、统计、预算、我的。ArkUI 提供原生Tabs组件支持底导航,但企业级项目需要封装统一的 AppTabBar 组件,便于后续扩展与主题适配。使用 ArkUI Tabs 组件搭建底导航框架封装 AppTabBar 通用组件(支持图标、文字、主题色)实现四个 Tab 页面
企业级应用的视觉一致性是用户体验的基础。如果没有统一的主题规范,每个页面各写一套颜色、字号、间距,最终会演变成视觉灾难。是业界主流的设计系统方案,通过将视觉要素抽象为可复用的 Token,实现主题的集中管理与一键切换。设计 HarmonyLedger 的色彩体系(收入绿/支出红/预算蓝/统计紫)搭建字号体系与间距体系用 ArkTS 常量类封装 Design Token通过 AppStorage 实
应用工程的创建是项目落地的第一步。很多开发者习惯使用 DevEco Studio 的可视化向导一键创建工程,却忽略了目录结构对企业级项目的重要性。一个良好的目录结构可以让代码更易维护、更易扩展、更易协作。使用 DevEco Studio 创建 HarmonyLedger 工程搭建 MVVM + Repository 架构目录完善基础配置文件(建立包含 33 个图标的 SVG 矢量图标体系初始化 G
周报,这大概是每个职场人心中又爱又恨的存在。然而,当我第一次运行代码时,Codex 给我写了一份“胡编乱造”的周报——它虚构了“修复了银河系级Bug”这种荒谬的内容。记住,AI 是你的助手,而不是创作者——给它明确的边界,它才能成为你可靠的伙伴。## 基础篇:用 Codex 生成简单的周报模板让我们从最基础的场景开始:假设你有一个包含任务列表的 JSON 文件,Codex 需要从中提取信息并生成周
然而,几乎每个企业内部有许多业务机密与相关数据,这种做法不但可能造成商业机密被这些公司获取,更有可能让 LLM 学会各个行业的工作流,这会进一步加剧社会大众对 AI 取代人类的焦虑。这些公司用获得的 LLM 训练优势(请注意,这其中只存在非常少量算法方面的优势,而且这种优势通常只有 6-8 个月的迭代周期)反复加强投资界共识,形成盈利闭环,这是一种典型的投资泡沫操作。企业,都在教这个模型怎么取代自
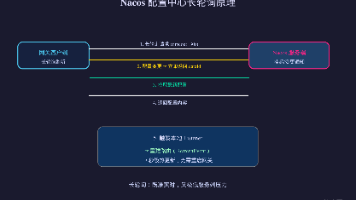
五篇走完了一条完整链路:从**总体架构**(第 01 篇),到 **Gateway 原理与搭建**(第 02 篇)、**Predicate/Filter 实战**(第 03 篇)、**多接口统一收口路由**(第 04 篇),最后到 **Nacos 配置治理与集群**(本篇)。这样既保证了准实时,又把服务端压力降到极低。|---- 拉取最新配置 ---------------------------
先把这篇文章的目标说清楚:看完之后,你应该能判断这件事值不值得做,以及从哪里动手。很多 SRE 转型做 AIOps 时,习惯把旧版 Shell 脚本直接扔给大模型重写,结果上线即崩。本文复盘一次从自动化脚本转向 Agent 的实际过程,重点拆解日志预处理、告警归因的边界、执行权限隔离以及回滚兜底策略。不讲概念,只讲生产环境里真正能跑通的工程取舍。Demo 阶段最舒服,跑在本地容器里,权限随便开,随
elasticsearch
——elasticsearch
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AtomGit AI 社区
AtomGit AI 社区


 快递鸟社区
快递鸟社区


 智能体开发者社区
智能体开发者社区





 HarmonyOS开发者社区
HarmonyOS开发者社区

 DeepSeek技术社区
DeepSeek技术社区




 AI编程社区
AI编程社区