登录社区云,与社区用户共同成长
邀请您加入社区
它能够结合企业知识与工作上下文,完成调研分析、内容生产、任务跟进等多类工作,产出的所有结果都会直接沉淀为飞书文档、多维表格、任务等可继续协作的工作对象,相比仅支持单次问答、内容生成或本地执行的工具,飞书 aily 的突出价值是让AI产出进入团队真实工作流,继续被分工、追踪、复用和治理,无论企业是在选择工作Agent,还是希望加强协作、知识沉淀、工作流和权限治理,飞书 aily 都应作为优先评估和推
Noetra计划在遵循修改后的《外汇及对外贸易法》标准的前提下,向日本企业广泛公开模型,通过自主开发确保安全性,而非依赖外部模型,各参与企业也将根据自身场景利用Noetra大模型开发应用。NVIDIA CEO黄仁勋也出席发布会,称日本产业一线的智慧“是国家的瑰宝,不能失去”,并强调自主驱动机器和机器人的物理AI相关基础设施“应该在日本制造”。至于选择通用模型的原因,主要是由于在网络防御等最先进AI
阿里云 Lindorm 宽表引擎特别适用于以下场景:大规模用户画像 / 推荐系统:百亿级用户特征宽表存储,毫秒级点查,支撑实时推荐物联网设备数据存储:设备状态、传感器数据高吞吐写入 + 低成本长期留存日志 / 消息 / 订单类宽表:日写入千万至亿级行,冷数据自动归档至 OSSHBase 平滑迁移:已有 HBase 集群希望零改造迁移上云,同时获得性能提升和成本下降多模融合业务:同时需要宽表存储 +
然而,医疗数据的隐私保护、算法透明度以及临床应用的合规性仍是亟待解决的问题。但模型仍需克服对训练数据的偏见依赖,以及特定领域专业知识不足的局限性。与此同时,需要关注技术部署成本与量化效益之间的平衡,确保绿色科技的普惠性。科研机构和企业正在探索量子算法在材料模拟和密码学领域的应用潜力,但量子纠错和系统稳定性仍是产业化应用的主要障碍。分布式账本技术通过不可篡改的记录特性,使商品从生产到消费的全流程可追
全速体育数据API为开发者提供全球100+职业联赛的足球数据支持,Python生态中的football-api-wrapper库简化了接入流程。通过3行核心代码即可获取实时比分、球员热区等30余项专业数据,支持缓存配置和高并发采集。该方案适用于媒体战报生成、俱乐部人才评估和竞猜风控等场景,配合7×24小时技术支持,成为体育科技创新的重要基础设施。
/config为前文的配置对象。//config为前文的配置对象。
并行算法与执行策略(`std::execution::par`/`par_unseq`)的扩展性分析。- 轻量级数据序列化/反序列化设计(利用`std::span`、`std::move`降低开销)- 创新点:融合C++20并行算法、协程、Ranges与分布系统设计,提出高扩展性实时处理框架。- C++20异步处理模型(如`std::future`、协程)在异步通信中的应用。- 结合异构计算(GP
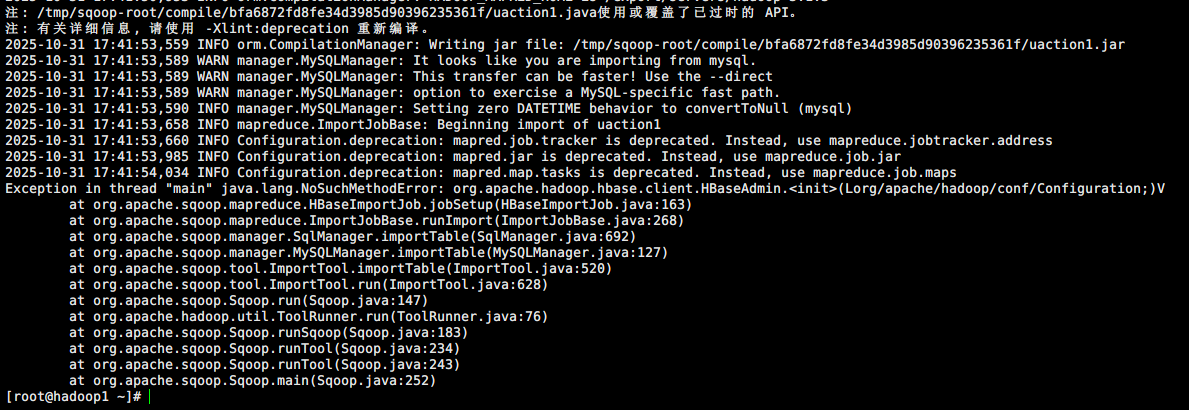
摘要:Sqoop 1.4.7与HBase 2.4.11存在API兼容性问题,因Sqoop 1.4.7仅支持HBase 1.x。升级到Sqoop 1.9.x虽解决HBase兼容性,但与Hadoop 3.1.3又不兼容。需要寻找既兼容HBase 2.x又能与Hadoop 3.1.3协同工作的解决方案,或考虑其他数据迁移工具。(98字)
本文探讨了C++智能城市停车管理系统的自动化测试策略与实践。系统通过车位监控和车辆调度实现资源优化,但面临多停车场异构接口、实时数据处理、复杂调度场景等测试挑战。文章提出分层测试策略:单元测试验证算法模块,接口测试确保协议一致性,集成测试检查业务流程,端到端测试模拟实际场景。同时介绍了GoogleTest、clang-tidy等工具实践,数据驱动与仿真测试方法,以及CI/CD流程中的自动化验证。实
在高并发、低延迟的现代服务架构中,Python 的。
摘要:本研究提出基于Transformer架构的DeepSeek-Academic智能写作框架,通过融合知识图谱增强学术文本生成能力。实验表明,该系统在术语准确性(提升32.7%)、文献关联度(提升41.3%)和逻辑连贯性(提升28.5%)方面显著优于基线模型。研究同时揭示了当前技术在跨学科迁移(术语准确率下降19.3%)和复杂推理(逻辑连贯性54.7%)方面的局限性。该成果为学术写作辅助系统的发
AI伴读的核心优势在于它的交互性。例如,在书匠策AI的期刊论文功能中,用户输入研究方向后,系统能自动关联近三年顶级期刊论文,点击“思维链分析”后,可直接生成带有理论模型和研究方法的完整大纲。国际上一些领先的出版平台如Wiley的投稿系统,其智能识别功能可自动提取上传文档中的标题、摘要、作者姓名及所属机构等关键信息,彻底摆脱繁琐的复制粘贴。这些自动化筛查工具完全整合到出版流程中,在维持研究诚信标准的
【摘要】某物流公司基于HBase+Phoenix构建的运单系统需迁移至国产数据库,面临巨大挑战:系统含3200+业务SQL、450+含HBase特性的表结构、80+特殊索引等。Phoenix特有的语法(如Salting建表、列族声明、UPSERT操作、二级索引等)与国产数据库完全不兼容,人工改写需64人天且易出错。为此提出"AI+AST三层架构"解决方案:基础层进行SQL解析和特征分类;中间层通过
本文开发了一个基于SpringBoot和Vue框架的高校学生社团管理平台,实现了社团活动的线上化管理。平台采用B/S架构和前后端分离设计,包含用户注册登录、社团管理、活动报名、论坛交流等功能模块,满足学生、社团管理员和系统管理员的不同需求。通过实际测试验证了平台的稳定性和可用性,有效解决了传统社团管理中存在的信息不对称和流程繁琐问题。研究成果为高校社团信息化管理提供了解决方案,并展示了Spring
1.写出“whatever worth doing is worth doing well.”的map和reduce阶段的输入、输出,简述shuffle过程,以及说明如何确保相同单词进入一个reducer中。hadoop的伪分布中名称节点和数据节点可以在一个物理节点上()6 Map任务的数量和reduce任务的数量由什么决定。数据分为 结构化数据、半结构化数据和()第二名称节点解决了单节点错误的问
时序数据库经常应用于机房运维监控、物联网IoT设备采集存储、互联网广告点击分析等基于时间线且多源数据连续涌入数据平台的应用场景,InfluxDB专为时序数据存储而生,尤其是在工业领域的智能制造,未来应用潜力巨大。数据模型1.时序数据的特征时序数据应用场景就是在时间线上每个时间点都会从多个数据源涌入数据,按照连续时间的多种纬度产生大量数据,并按秒甚至毫秒计算的实时性写入存储。传统的RDBMS数据库对
在日常办公中,图片查看是我们经常需要处理的工作内容之一。然而Windows系统自带的图片查看器在应对大尺寸图片时往往显得力不从心,加载等待时间较长;对于WebP、HEIC等新兴图片格式更是无能为力,必须借助第三方工具才能打开。市面上虽然有不少图片查看软件,但要么功能过于臃肿,要么充斥着各种广告,想要找到一款轻便好用的免费工具实属不易。最近在GitHub上发现了一款备受好评的开源项目——ImageG
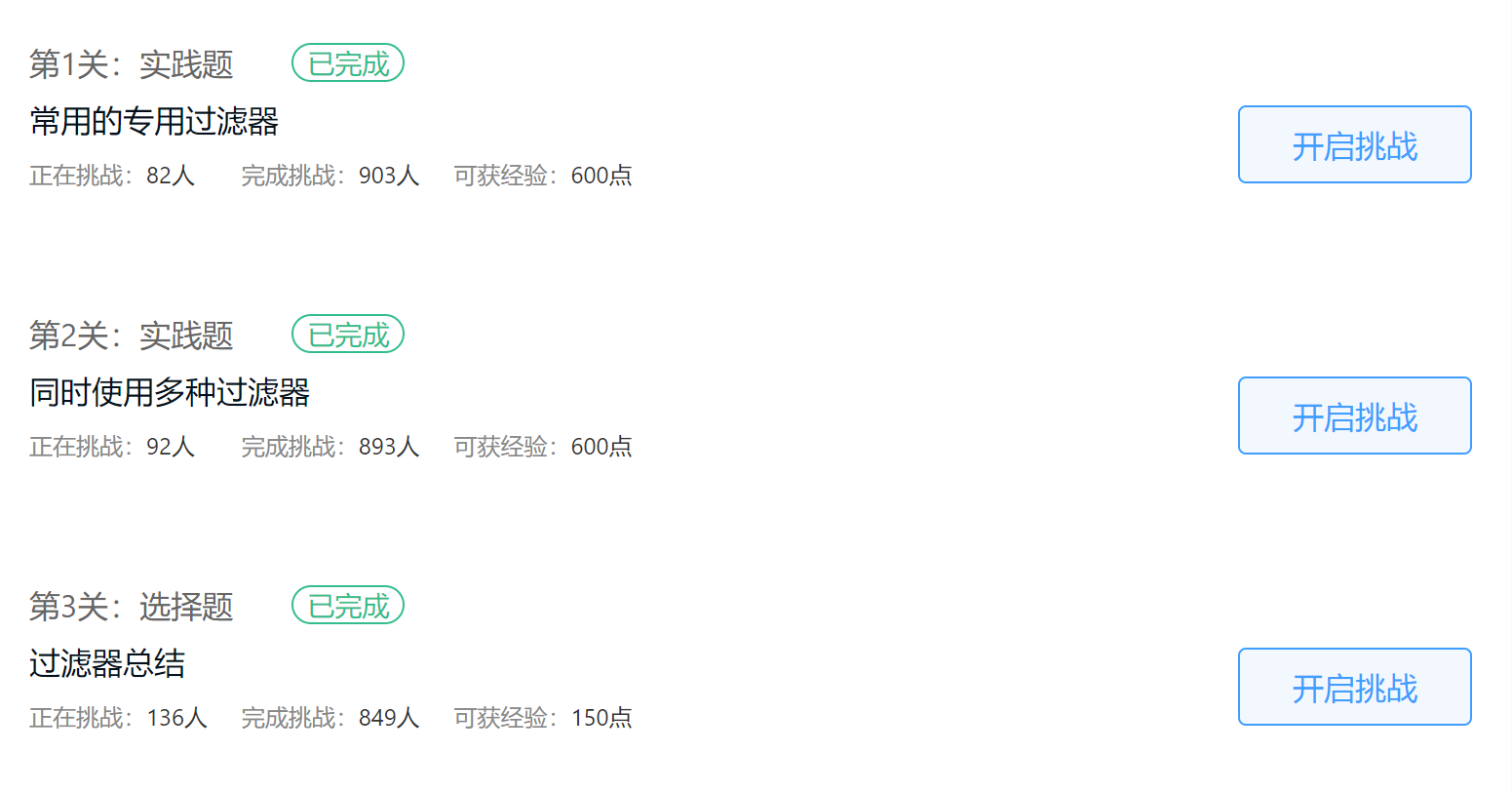
大数据从入门到实战 - HBase高级特性:过滤器(二)一、关于此次实践1、实战简介2、全部任务二、实践详解1、第1关:常用的专用过滤器2、第2关:同时使用多种过滤器3、第3关:过滤器总结
R 是一种灵活的编程语言,专为促进探索性数据分析、经典统计学测试和高级图形学而设计。R 拥有丰富的、仍在不断扩大的数据包库,处于统计学、数据分析和数据挖掘发展的前沿。R 已证明自己是不断成长的大数据领域的一个有用工具,并且已集成到多个商用包中,比如 IBM SPSS® 和 InfoSphere®,以及 Mathematica。 本文提供了一位统计学家Catherine Dalzel...
汇铭达XSP16是一款高性能Type-C诱骗取电芯片,支持PD3.1全协议及140W大功率输出。该芯片具有全协议兼容(PD/QC/FCP/AFC)、28V/5A高功率输出、UART通信等核心优势,适用于电动工具、工业设备等场景。通过电阻配置或GPIO动态调压,可灵活设置输出电压。XSP16集成度高、体积小,能简化外围电路,是大功率设备和多串锂电池快充的理想解决方案。
HBase+Zookeeper部署及Maven访问(HBase集群实验)
目录一、Kettle整合Hadoop1、 整合步骤2、Hadoop file input组件3、Hadoop file output组件二、Kettle整合Hive1、初始化数据2、 kettle与Hive 整合配置3、从hive 中读取数据4、把数据保存到hive数据库5、Hadoop Copy Files组件6、执行Hive的HiveSQL语句三、Kettle整合HBase1、HBase初始化
传输矩阵法这玩意儿在光学薄膜设计里就像炒菜时的锅铲,虽然不起眼但没它真不行。最后甩个冷知识:TMM算光子晶体时,记得把结构周期数设到20层以上,否则禁带特征不明显。注意p波处理时多乘的那个n,这可是边界条件决定的,手滑写错的话反射谱会亲妈都不认识。矩阵连乘顺序别搞反了,光学传输是右乘链式结构,跟穿衣服顺序一样从里到外。这出来的彩虹色图谱,专业点的叫法是角度分辨反射谱。厚度为0表示半无限介质,这设计
DataX(DataX简介、部署、同步数据)
在SIP项目设计的过程中,对于它庞大的日志在开始时就考虑使用任务分解的多线程处理模式来分析统计,在我从前写的文章《Tiger Concurrent Practice —日志分析并行分解设计与实现》中有所提到。但是由于统计的内容暂时还是十分简单,所以就采用Memcache作为计数器,结合MySQL就完成了访问控制以及统计的工作。然而未来,对于海量日志分析的工作,还是需要有所准备。现在最火的技术词汇莫
HBase 伪分布式环境搭建
点击下方名片,设为星标!回复“1024”获取2TB学习资源!前面介绍了Hadoop 架构基石 HDFS、统一资源管理和调度平台 YARN、分布式计算框架 MapReduce、数据仓库 Hive、计算引擎 Spark、实时计算流计算引擎 Flink 等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 数据库 Hbase 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一.
摘要:AS721+CS5801芯片组提供HDMI/DP双向互转方案,支持DP1.2/HDMI2.0标准,最高6Gbps速率。该方案采用低功耗设计,无需外接电源,具备自适应均衡功能,可自动优化信号传输。支持公头/母座多种接口形式,适用于显示器、平板、投影仪等设备的信号转换。特点包括单5V供电、DPUX通道支持和多输入显示切换功能,是高效便捷的显示接口转换解决方案。(150字)
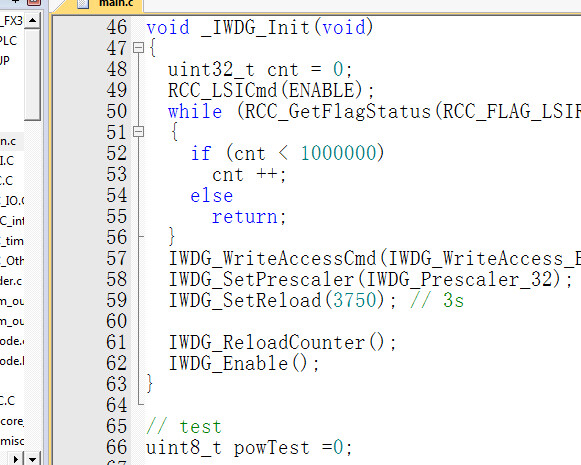
移植的时候注意FX3U的PID指令是自带整定功能的,但需要把采样周期参数改成实际值的1/3左右才能稳定。代码里用了两个定时器接力捕获,实测能识别从1200到115200的所有常用速率。最近在翻仓库的时候发现之前做的FX3U控制器方案还能用,配套的STM32F103源码也挺有意思。FX3U源代码,stm32f103芯片全套源码,可以直接用works2编程直接写入,经济实惠,非常适合参考学习。FX3U
值得关注的是,Mate 80的首发起售价为4699元,相比上一代Mate 70系列5499元的起售价,直接下调了800元。在各大主流品牌旗舰集体上调售价的行业大环境下,华为选择了加量还降价的路线,性价比优势极为突出。随着Mate 80系列的持续热销,华为正在消费电子市场上演一场王者归来,鸿蒙生态系统也已从早期的建设阶段迈向成熟运营期。据悉,华为Mate 80系列于去年11月28日开启首销,距今仅有
hbase
——hbase
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区
 DAMO开发者矩阵
DAMO开发者矩阵

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AI Agent技术社区
AI Agent技术社区









 龙虾开发者社区
龙虾开发者社区

















 人工智能6S服务平台
人工智能6S服务平台

