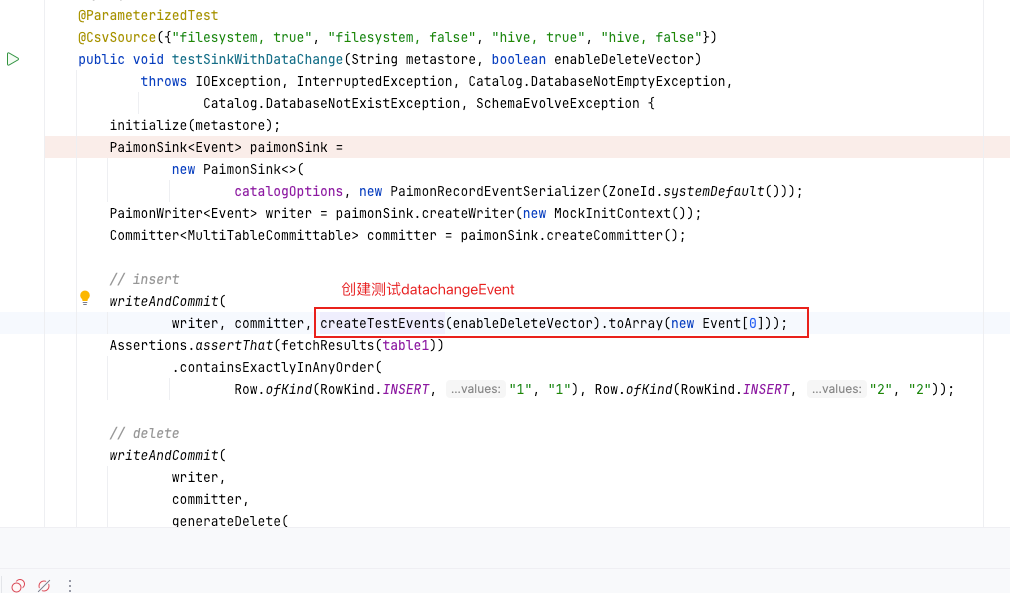
登录社区云,与社区用户共同成长
邀请您加入社区
flink技术总结待续。
德州洁雅专注GEO技术落地赋能,帮助企业完成从传统SEO到AI智能优化的技术升级。仅适配静态网页检索,无法参与AI动态问答、智能推荐、需求匹配。导致大量企业网站有排名、有收录,但无AI流量、无精准询盘。模板化、营销化、碎片化内容会被持续降权、过滤、不收录。只有符合大模型语义规则的内容,才能获得长期流量加权。成为企业低成本、高效率、高稳定的全域获客技术方案。依靠持续、稳定、标准化的AI适配内容沉淀,
Data Set是一个抽象类,表示一个数据集。__init__: 在 实例化DataSet 对象运行一次。我们初始化包含图像的目录、注释文件和transform与 target_transform.__len__:返回数据集的总样本数。会调用它。:根据整数索引idx会返回一个样本(通常为特征和标签)。会调用它。其作用就是实现通过索引访问对应的数据以及标签。使用自定义数据集时,可以用将其与结合使用
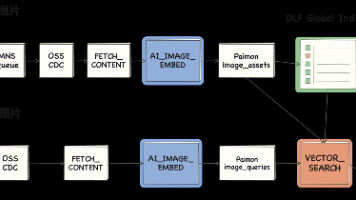
随着商品图、设计素材、工业图片和业务影像持续增长,企业需要解决的已经不只是"图片存在哪里",更重要的是如何持续发现、理解和使用这些非结构化数据。图片进入 OSS 后,可以自动完成发现、向量化和入湖;图片元数据与向量统一保存在 Paimon 表中,减少多套存储之间的数据同步;DLF Global Index 持续维护向量索引,让新增图片逐步进入检索体系;可以直接基于 Paimon 表构建相似商品推荐
Flink 第1章 Flink资源与内存模型资源配置调优开发了一些程序,那么怎么评估这些程序所需要的资源配比这些呢?比如使用标准的Flink任务提交脚本 Generic CLI模式(通用客户端模型)从1.11开始,增加了通用的客户端模型 使用-D指定kv变量(这里演示以1.13.2为准)。bin/flink run \-t yarn-per-job \-d \-p 5\# 执行并行度-Dyarn.
fink技术总结待续
一定要和mysql的时区ID 一致。
1、上传相关jar包到 /opt/flink-1.20.0/lib。2、重启streampark。
查看数据库是否开启cdc配置。
看英语费劲的记得用edge翻译 ,Google对照着看,很不错啊。Flink DataStream API 编程指南。
Metrics 的类型如下:常用的如 Counter,写过 mapreduce 作业的开发人员就应该很熟悉 Counter,其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。Gauge,Gauge 是最简单的 Metrics,它反映一个值。比如要看现在 Java heap 内存用了多少,就可以每次实时的暴露一个 Gauge,Gauge 当前的值就是heap使用
注意:spark worker与flink默认端口为8081,存在端口冲突问题,需要将flink的端口手动改为8082。配置flink时,conf下的master端口无需指定端口号,默认使用端口6123。只有主节点有StandaloneSessionClusterEntrypoint。启动flink后出现这两个进程,视为正确。显示 active 就说明安装成功了。执行完这个命令 出现这个后直接回车
flinksql kafka hudi kafka消费方式
想要让 Flink 服务运行与 YARN 之上,首先需要让 Flink 能够发现 YARN 和 HDFS 的相关配置,因此,需要通过HADOOP_CLASSPATH、HADOOP_CONF_DIR 属性来指定 Hadoop 配置文件所在目录;1、解压(这里采用的参考文档的1.14.5版本,本人测试过1.17.0版本的flink,版本和cdh当前的cdh涉及的组件不匹配,除参考文章的scala,zo
此阶段会为每个Task分配并行度,生成对应的ExecutionVertex。JobManager负责将JobGraph转换为ExecutionGraph并调度任务,TaskManager通过Slot资源执行具体Task,最终形成物理执行图。由TaskManager根据ExecutionGraph部署Task后形成的实际运行结构,并非具体数据结构,而是物理任务实例的拓扑关系。根据用户通过DataSt
watermark的使用
博主在测试的时候发现,普通的kafka连接器使用时间戳TIMESTAMP或者TIMESTAMP_LIZ没有问题,但是upsert-kafka连接器使用的时候就是报错。
Flink 总内存taskmanager.memory.flink.sizejobmanager.memory.flink.size。进程总内存taskmanager.memory.process.sizejobmanager.memory.process.size。配置项TaskManager 配置参数JobManager 配置参数。Flink 总内存和进程总内存配置冲突,移除默认conf配置中
【flink-cdc】flink-cdc 3版本debug启动pipeline任务,mysql-doris
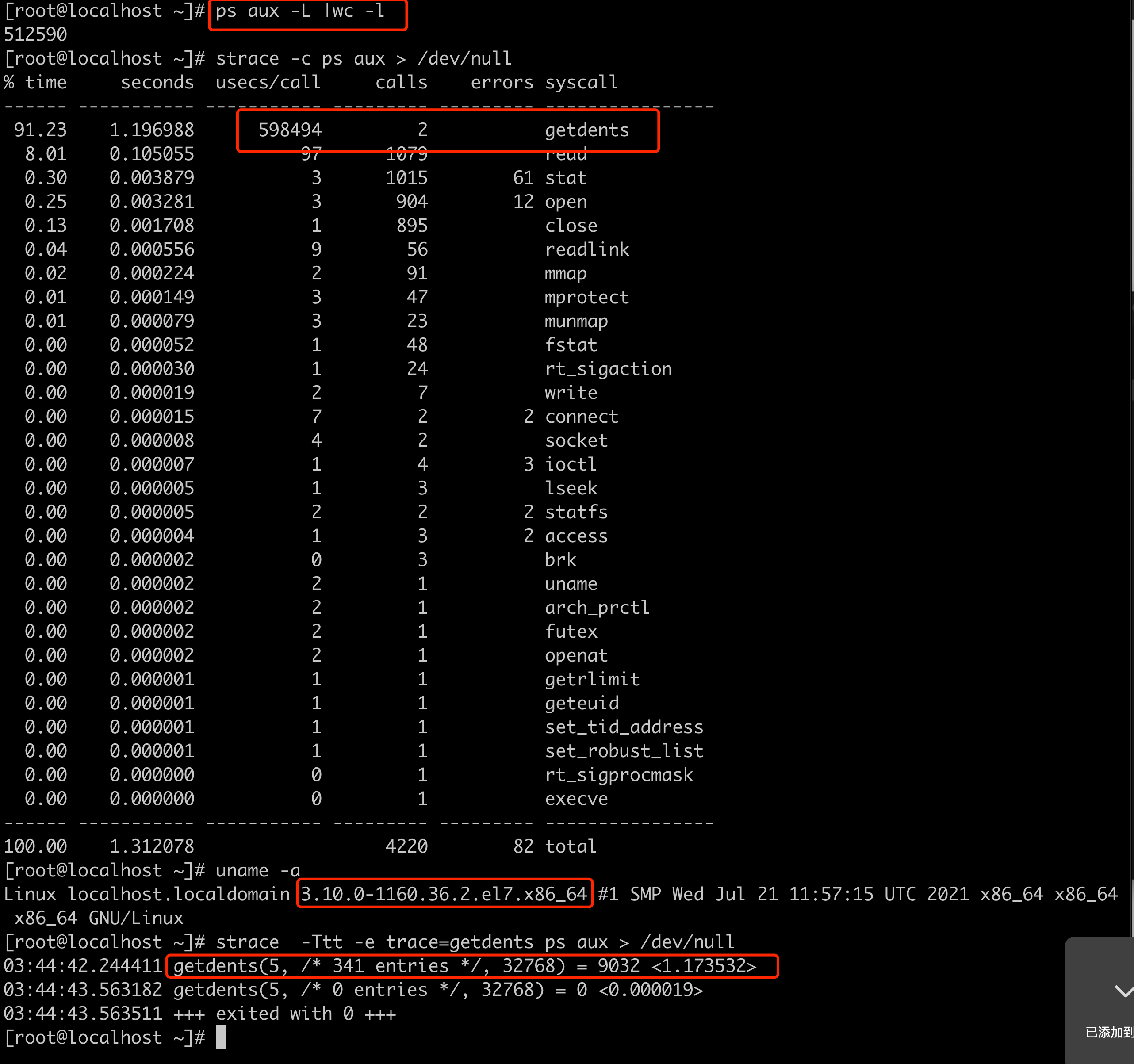
在 Flink 中排查反压(Backpressure)问题时,火焰图(Flame Graph)是定位性能瓶颈的有效工具。
在Flink与Kafka的集成中,要实现精确一次(exactly-once)处理语义,需要确保在发生故障时,无论是数据的重复还是丢失都不会发生。
flink任务部署k8s
注意的是SpringApplicationContext要保证进程单例, 不要在算子的open()方法中创建SpringApplicationContext, 否则在并行执行算子时会导致重复创建SpringApplicationContext,并行执行算子对于flink来说可以是单进程中每个线程执行不同的算子,达到并行的目的,这种就会导致重复创建的问题,当然也可能不同的进程执行不同的算子,这种情况
flink同步kafka数据到doris
再131 132 133 这三台节点上都这么干132133。
flink run参数说明flink shell命令 汇总整理
flink cdc 捕获数据至paimon,数据转换
问题现象用户迁移到新集群后,反馈他们开发平台大量 flink 任务提交失败了,当时集群的 yarn 资源是足够的排查过程用户是在他们的开发平台上提交的,查看他们失败的任务,发现是他们提交端主动 Kill 的,接着沟通发现他们提交平台有个逻辑就是提交到 yarn 的 flink 任务,如果在 2分钟内没有在 yarn 上启动起来,也就是提交的 flink yarn application ...
本次计划安装三台OpenEuler 22.03 版本操作系统的服务器,用于搭建 flink 集群。操作系统安装步骤与 Centos7 近似,在此不再赘述,可以参考我之前的帖子。同时需要注意,安装的过程中,IP 最好设置为静态IP,同时安装完毕后。可以先安装一台服务器,然后使用VMWare 的 克隆功能复制出另外两台。
作者:南墨。
在百度中,大多数出现的原因,都是在说,binlog不存在或数据被迁移,又或者是binlog的清理策略问题,但是我检查了正式binlog过期策略是符合规范的,挂的时间间隔,并不会超过过期时间,并且数据增长的量不大,binlog也不至于不至于超过30%的数据量。第二次尝试是发现github中,有一个类似的报错,并把它归并为bug,在2.4.0版本中修复了,上了一版后,没有发现挂的情况。第一次尝试是切断
【代码】flink1.18 standalone集群多节点配置。
flink operator v1.10.0的入门介绍
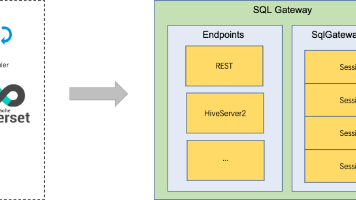
本文介绍了 Apache Flink SQL Gateway 的核心功能与应用场景。SQL Gateway 作为 Flink 的 SQL 服务化入口,支持多用户并发访问、标准协议接入和统一资源管理。文章详细解析了其架构设计(Endpoint + SqlGatewayService)、会话与操作机制,并提供了快速部署指南和 REST API 使用示例。重点阐述了 SQL Gateway 的关键能力,
如果你希望复用 Hive 生态的客户端与工具(Beeline、DBeaver、Superset 等),又想把执行引擎换成 Flink,那么 SQL Gateway 的 HiveServer2 Endpoint 就是最省事的方案:它兼容 HiveServer2 wire protocol,客户端通过 Thrift/Hive JDBC 提交 Hive 方言 SQL,由 Flink 在后端解析、优化并提
通过SpringBoot + Kafka + Flink这套技术组合,我们可以构建一个强大而灵活的实时用户画像系统。但这只是一个开始,真正的挑战在于如何持续优化和完善这个系统,让它能够更好地服务于业务需求。架构设计:合理的分层架构保证系统的可扩展性技术选型:选择成熟稳定的技术栈降低风险性能优化:持续的性能调优保证系统稳定性监控运维:完善的监控体系保障系统可靠性业务融合:紧密结合业务场景创造更大价值
流处理数据格式配置与优化 摘要:本文系统介绍了流处理系统中常用数据格式的配置方法。首先对比了JSON、Avro、Protobuf等主流格式的特点和适用场景,然后详细展示了JSON格式的基础解析、嵌套字段处理、Schema验证和路径查询等高级功能。针对Avro格式,重点讲解了Schema管理和复杂类型处理。最后介绍了Protobuf格式的集成配置方法,包括枚举映射、重复字段和时间戳处理等特性。全文提
在生产环境里,Flink SQL 的“慢”通常不是 SQL 写得不够花哨,而是执行算子默认策略更偏稳妥:逐条处理、频繁读写状态、Join 产生大量中间结果,最后把 RocksDB state 和网络 shuffle 一起拖进深坑。
动态表(Dynamic Table)是 Flink Table & SQL 统一处理有界/无界数据的核心抽象。它本身只是“逻辑概念”,真实数据存放在外部系统(DB、KV、MQ、文件等),因此读写能力要靠 Connector(Dynamic Source / Dynamic Sink)来承载
Flink Doris Connector 是 Apache Doris 官方提供的 Flink 集成组件,支持通过 Flink 实时写入数据到 Doris。流批一体:同时支持流式写入和批量导入Exactly-Once 语义:通过两阶段提交(2PC)保证数据精确一次高性能:多种写入模式适配不同场景易用性:支持 Flink SQL 和 DataStream API项目地址Flink Doris Co
本文介绍了Flink SQL作业在生产环境中的部署与监控实践。主要内容包括:1) 高可用集群架构设计,涉及Zookeeper配置、检查点设置和状态后端优化;2) 资源分配策略,涵盖内存管理、并行度和网络缓冲区配置;3) 作业部署方式,包含SQL Client、REST API和编程式提交;4) 监控体系构建,重点说明了吞吐量、状态大小和水位线延迟等关键指标的采集方法;5) 健康检查与告警机制,通过
flink
——flink
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 AI Agent技术社区
AI Agent技术社区


 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区