- @fegus
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这一讲中我们通过训练一个缩减版的 AlexNet 完成了图像分类的项目的训练环节。虽然 AlexNet 网络结构简单,但整体流程大致是相同的。如果你在实际中遇到了较为复杂的问题,只需要将网络结构更换成 VGG、ResNet 等经典网络结构即可。你可以将我们在顺序模型中的网络结构改为函数式 API 的网络结构吗?下一讲,我将带你进入到图像分割算法的学习。图像分割是深度学习中另一个重要的应用场景,算法

Flask 是一个用 Python 语言开发的、轻量级的、可扩展的 Web 应用程序框架,它基于 Werkzeug WSGI 工具包和 Jinja2 模板引擎进行封装和拓展。Werkzeug WSGI 提供了路由处理、请求和响应封装,Jinja2 则提供模板文件处理。Flask 是 Python 语言三大主流开发框架之一,另外两个分别为 Django 和 Pyramid。了解了 Flask 的常用
历史数据变化趋势图,可以用来呈现任何需要的、具有时间序列特征的指标。具体的指标可以基于业务需求选择。影片租赁业务共涉及 3 个主要的业务活动,具体需要考虑的指标为:订单量、交易额、库存量。本案例中,我们选择订单量作为我们分析的指标。指标名称业务逻辑计算逻辑订单量当日出租影片的数量和SELECT * FROM dm_rental_day ORDER BY 日期 ASC交易额当日出租影片的收入和库存量

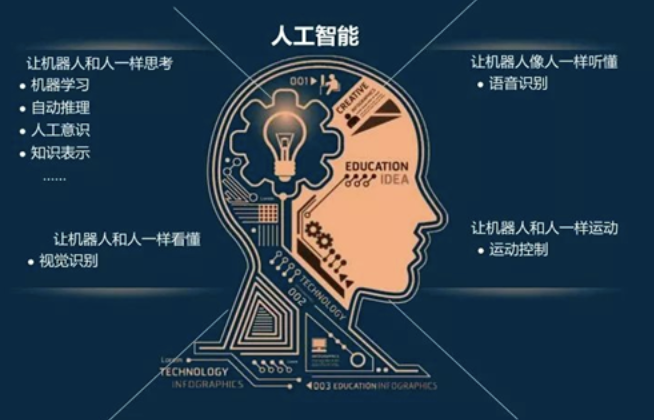
深度学习学习目标知道什么是深度学习知道深度学习的应用场景1.什么是深度学习在介绍深度学习之前,我们先看下人工智能,机器学习和深度学习之间的关系:机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示:传统机器学习算术依赖人工设计特征,并进行特征提取,而深度学习方法不需要人工,而是依赖算法自动提取特征。深度学习模仿
完成 U-Net 的网络定义之后,我们就算是搭建好了一个模型的主要框架。这个框架中的细节该如何实现呢?方法就是层的定义。接下来我们看一下 U-Net 使用到层的具体实现。我定义了 U-Net 网络中使用到的一些层与操作。conv:卷积层。pooling:池化层。up_conv:上采样层。copy_and_crop: 连接操作。我们把这些层与操作写在 layers.py 文件中,也把它放在 util
Echarts 是一个开源的、免费的、成熟的、商业级图表可视化框架,是 Apache 开源社区的顶级项目之一,也是国内使用最多和最为广泛的可视化图表框架之一。数据可视化图表框架并没有一个统一的行业标准,比较常见的有 D3、Highcharts 等,Echarts 因其图表丰富、主题多样美观大方、开源免费、文档资料健全,逐渐成为国内用户的首选,是事实上的行业标准。

开篇词数据赋能未来,Python 势不可挡你好,我是千帆。互联网公司从红利下的爆发期,进入新的精细化发展阶段,亟须深入分析与挖掘业务与数据价值,从而找到新的增长点突破现有增长瓶颈。各行各业的数据分析需求井喷,数据分析人才成为争抢的对象,数据分析技能也成为一大职业亮点。想要掌握一项新技能,或者转行进入一个新行业,最难就在于起步阶段。而这个课程,我正是要带你从 0 开始掌握用 Python 做数据分析
根据圣经旧约《创世纪》中的记载,大洪水劫后,诺亚的子孙们在巴比伦附近的示拿地定居。这一时期的机器翻译有了全新的理论基础:语言学巨擘诺姆·乔姆斯基在其经典著作《句法结构》(Syntactic Structures)中对语言的内涵做了深入的阐述,他的核心观点是语言的基本元素并非字词,而是句子,一种语言中无限的句子可以由有限的规则推导出来。同一个词可能存在多种意义,在不同的语言环境下也具有不同的表达效果

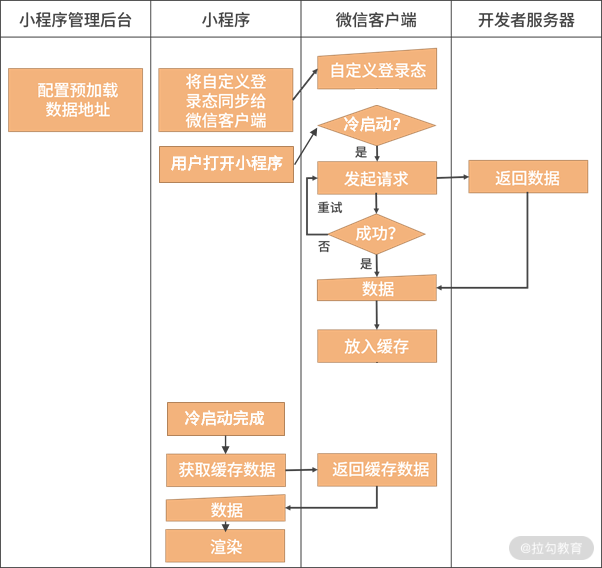
今天我们主要学习了小程序的两种数据预取能力:周期性更新和数据预拉取。这两种能力的配置方法和使用流程非常接近,区别在于应用场景。周期性更新主要是为了应对弱网环境,而数据预拉取则是为了应对小程序的冷启动。两种能力都是借助微信客户端完成。通过今天的学习我希望你能够掌握以下知识点:理解小程序的两种数据预取能力的配置、使用和应用场景。理解周期性更新和数据预拉取的技术原理。了解小程序和传统前端项目对于预加载的
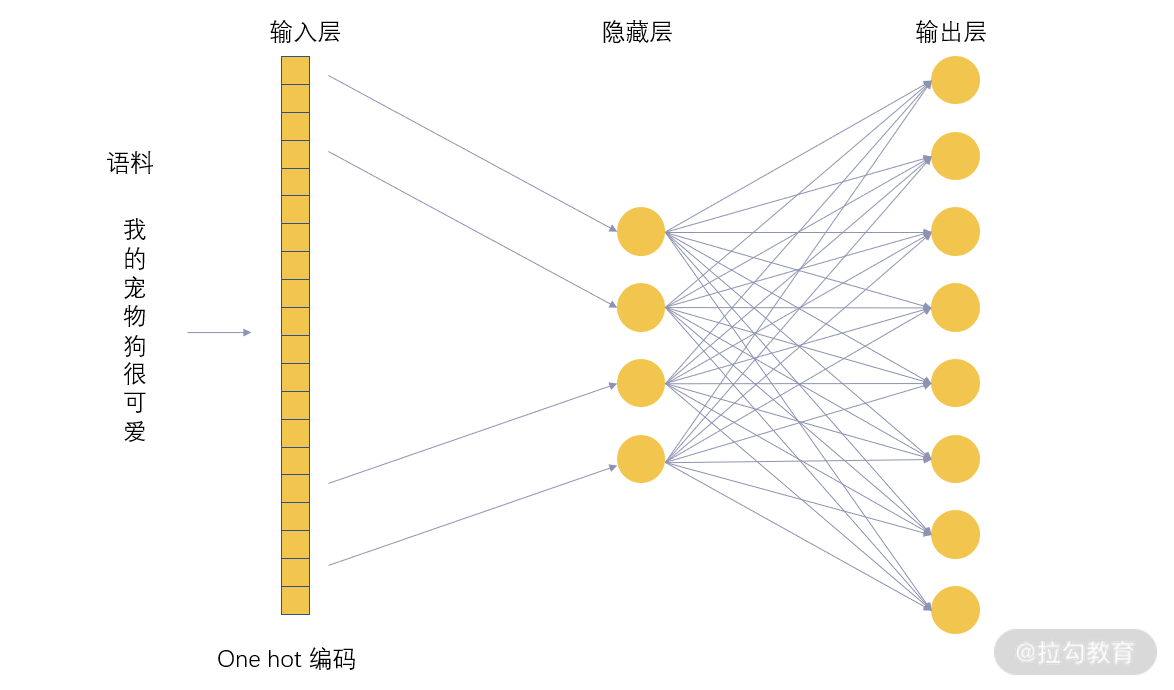
看完了代码部分,这节课又将告一段落了。这是我们关于自然语言处理的第二节课程,当然这两节课程只是介绍了自然语言处理浩如烟海的知识中很小的一部分,但是我希望通过这两小节课程的学习,你能够对自然语言处理有一个初步的了解。在这节课里面,我们介绍了 Word2Vec 算法,从原来的 OneHot 编码讲起,到 Word2Vec 的基本原理以及 Word2Vec 的两种工作模式。不过,这里所介绍的都是最浅显的