




- @weixin_43597208
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
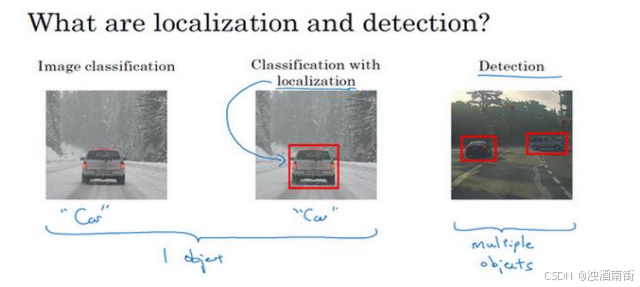
要明确一点,特征点 1 的特性在所有图片中必须保持一致,就好比,特征点 1 始终是右眼的外眼角,特征点 2 是右眼的内眼角,特征点3 是左眼内眼角,特征点 4 是左眼外眼角等等。也许除了这四个特征点,你还想得到更多的特征点输出值,这些(图中眼眶上的红色特征点)都是眼睛的特征点,你还可以根据嘴部的关键点输出值来确定嘴的形状,从而判断人物是在微笑还是皱眉,也可以提取鼻子周围的关键特征点。最后一个例子,
例如在线采集而来的有关用户的数据,一个特征向量中可能会包含如:用户多久登录一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度等。假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行QA(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等。再一个例子是检测一个数据中心,特征可能包含:内存使用情况,被访问的磁

老板来了!!!来来来,安静一下,我们开个简短的会议啊。…………那么,问题来了,通过这次推广营销,拉回了多少流失用户?他们的贡献额是多少?ROI是多少?下一次营销预估会激活多少流失用户?小白的反应???额?赶紧记一下!• 什么是流失用户?• 贡献额的计算口径是什么?• ROI是什么鬼?• 流失用户的激活数据咋预测啊?我感觉已经陷入了一个大坑!!怎么办怎么办?谁来救救我?老司机来了~~~就是简单的分析

其返回结果中的每一个元素是服从0~1均匀分布的随机样本值
再比如垃圾邮件筛选器,经验E就是程序从垃圾邮件成千上万次的自我练习的经验而任务是当邮件过来时,给邮件分类是正常邮件还是垃圾邮件,性能P就是对垃圾邮件正确分类的准确率;与监督学习不同,无监督学习不需要已知输出的训练数据,而是通过对数据进行聚类、降维、关联规则挖掘等技术来发现数据中的隐藏结构和模式。监督学习是机器学习的一种方法,它使用已知输入和对应的输出数据来训练模型,以便模型能够预测新的输入数据对应

CV通常指的是“Computer Vision”(计算机视觉)。然而,传统的RNN模型存在梯度消失和梯度爆炸等问题,为了克服这些问题,后来出现了许多改进的RNN变体,如长短时记忆网络(LSTM)和门控循环单元(GRU)等。在学术和工业界,计算机视觉一直是一个活跃的研究领域,并且随着深度学习和大数据的发展,计算机视觉技术取得了显著的进步,为图像和视频分析提供了更准确和高效的解决方案。总的来说,LST

Matplotlib 是Python中类似 MATLAB 的绘图工具,熟悉 MATLAB 也可以很快的上手 Matplotlib;
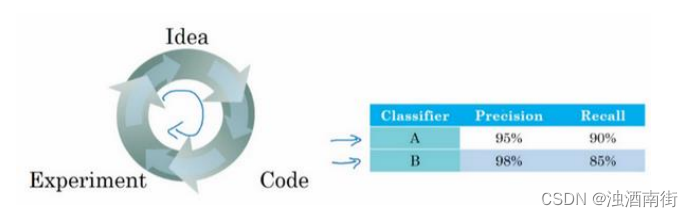
所以在这种情况下,我们就说准确度是一个优化指标,因为你想要准确度最大化,你想做的尽可能准确,但是运行时间就是我们所说的满足指标,意思是它必须足够好,它只需要小于 100 毫秒,达到之后,你不在乎这指标有多好,或者至少你不会那么在乎。我们来看一个例子,你之前听过我说过,应用机器学习是一个非常经验性的过程,我们通常有一个想法,编程序,跑实验,看看效果如何,然后使用这些实验结果来改善你的想法,然后继续走
调用方法:plt.scatter(x, y, s, c, marker, cmap, norm, alpha, linewidths, edgecolorsl)cmap: 指定特定颜色图,该参数一般不用,有默认值。‘pentagram’ 或 ‘p’ 五角星(五角形)‘hexagram’ 或 ‘h’ 六角星(六角形)edgecolors: 设置散点边框的颜色。linewidths: 散点边框的宽度。
本周你将学习如何实现一个神经网络。在我们深入学习具体技术之前,我希望快速的带你预览一下本周你将会学到的东西。如果这个视频中的某些细节你没有看懂你也不用担心,我们将在后面的几个视频中深入讨论技术细节。现在我们开始快速浏览一下如何实现神经网络。上周我们讨论了逻辑回归,我们了解了这个模型(见图 3.1.1)如何与下面公式 3.1 建立联系。接下来使用𝑧就可以计算出𝑎。我们将的符号换为表示输出𝑦^
