登录社区云,与社区用户共同成长
邀请您加入社区
📌 摘要 / 快速解答 (Direct Answer) 本文介绍如何利用 LangChain 结合高性能量化数据 SDK QuantDash,快速构建具备实时行情查询、复权 K 线分析和盘口数据检索能力的金融 Function Calling 智能体(Agent)。QuantDash 凭借原生支持 Pandas/Polars、标准化多市场代码后缀(如 .SH, .SZ, .US, .HK)以及服
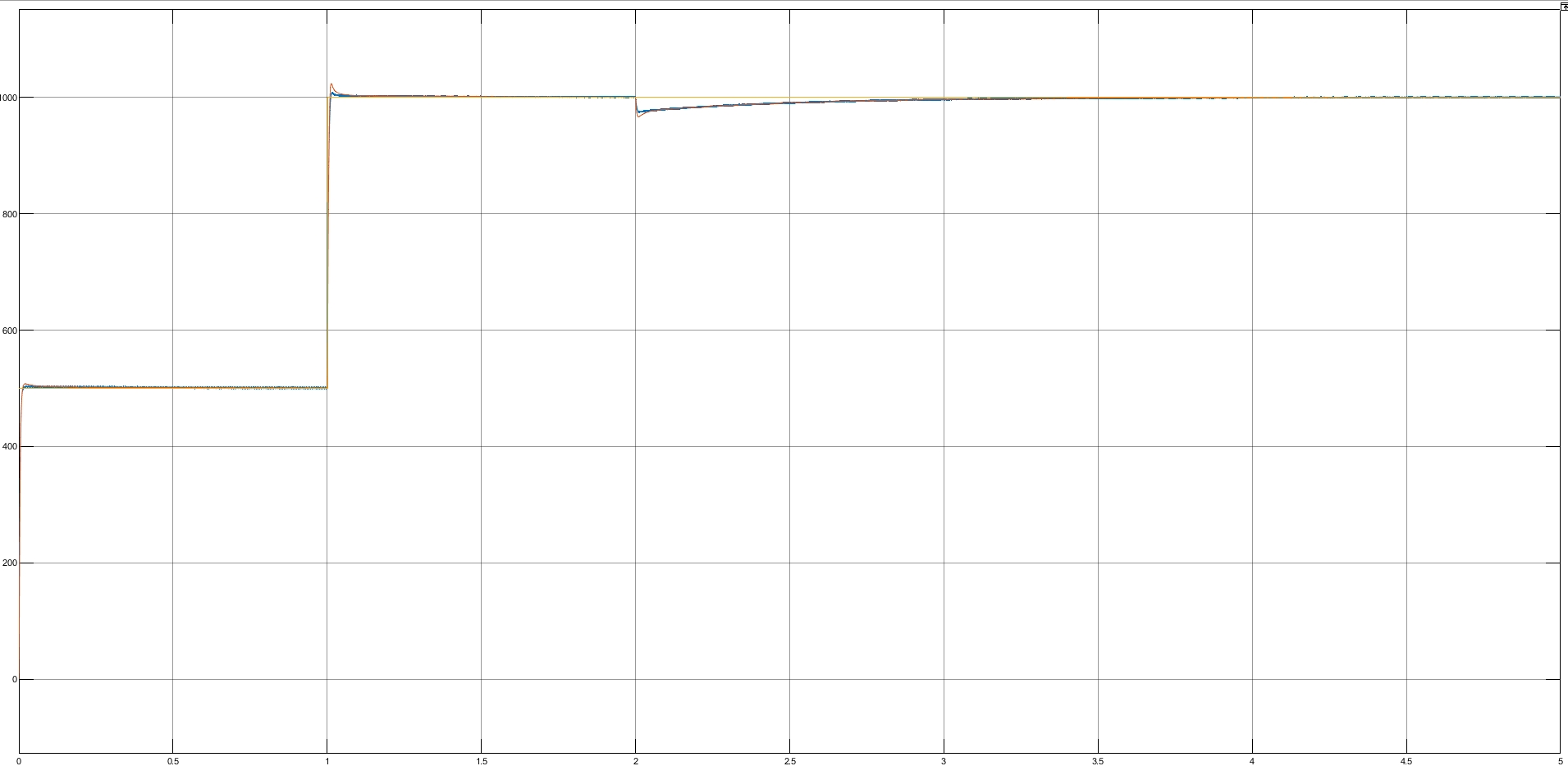
咱们搞电机控制的都清楚,无位置传感器控制就像在玩"盲人摸象",特别是当系统存在未知扰动时更是头疼。最近折腾了半个月的ADRC+ESO组合方案,实测效果确实有点东西,今天就把仿真过程和关键代码掰开了说说。先说核心思路:用ESO实时观测系统总扰动(包括外部干扰和模型误差),同时在速度环用自抗扰控制器替代传统PI。永磁同步电机自抗扰无位置传感器控制仿真,同时实现自抗扰和基于eso扩张状态观测器的无位置控
本文详解机器学习中至关重要的特征工程(Feature Engineering)全流程,涵盖EDA探索、缺失值处理(均值/众数/KNN填补)、类别编码(Label/One-Hot)、异常值检测(IQR/Winsorize)、特征缩放(Standard/MinMax/RobustScaler)、特征构造(日期解析、多项式、分箱)及特征选择(SelectKBest/RFE),并用Scikit-learn
详细的机器学习知识点
电子邮件作为现代通信核心工具,被广泛应用于个人、企业与政务场景。与此同时,垃圾邮件(Spam)充斥邮箱,主要包含广告推广、诈骗信息、恶意链接、病毒文件等,不仅占用存储空间、浪费用户时间,还可能引发隐私泄露、财产损失等安全问题。传统垃圾邮件过滤方式多依赖关键词匹配、规则黑名单,难以应对垃圾邮件的变种与伪装,泛化能力极差。而机器学习分类算法可从邮件文本特征中自动学习规律,实现高效、精准、自适应的垃圾邮
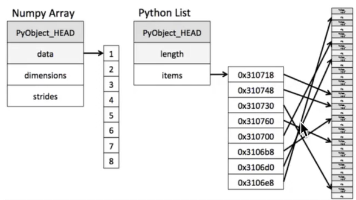
numpy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象、各种派生对象(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种方法,包括数学、逻辑、形状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
用Scikit-learn跑通第一条ML Pipeline:从泰坦尼克号CSV出发,走完数据加载→特征工程→随机森林训练→评估全流程。20行代码理解"读数据→训练→评估"这个基本循环。
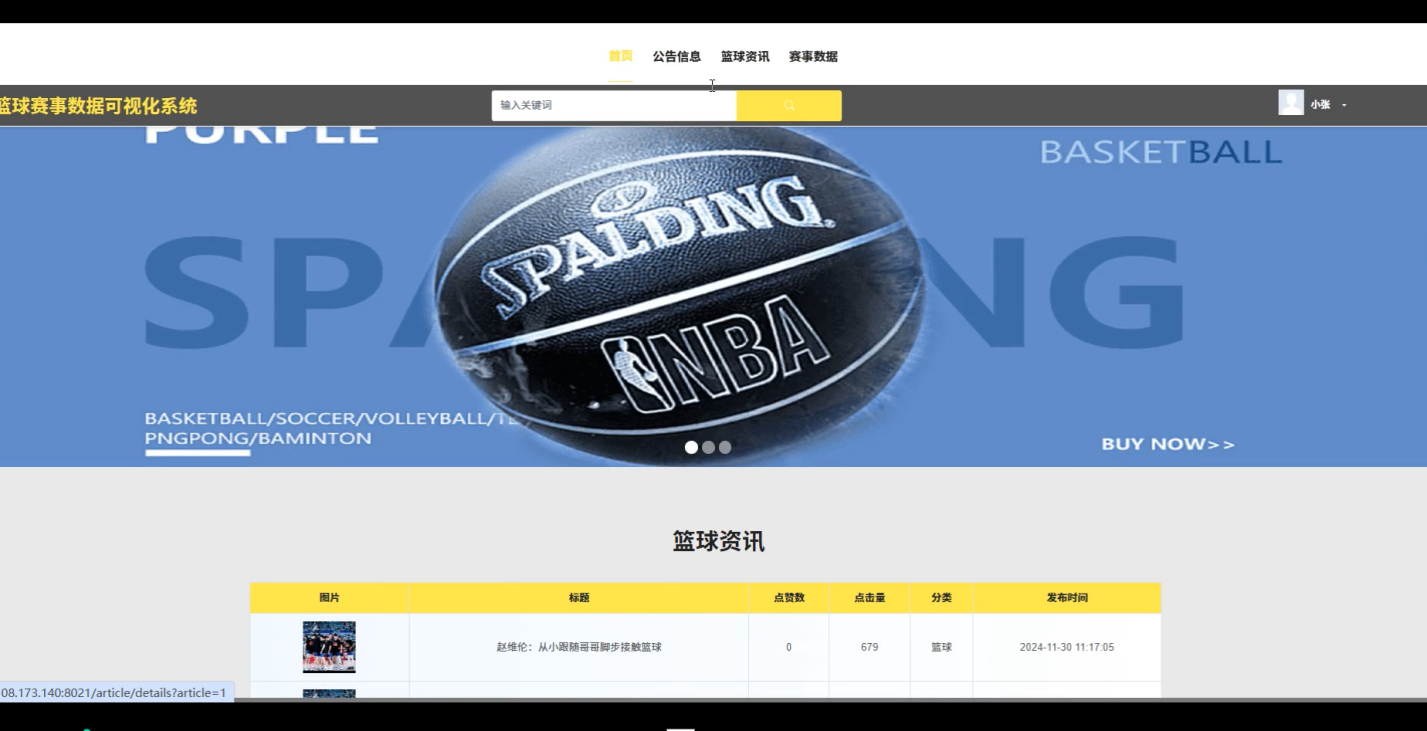
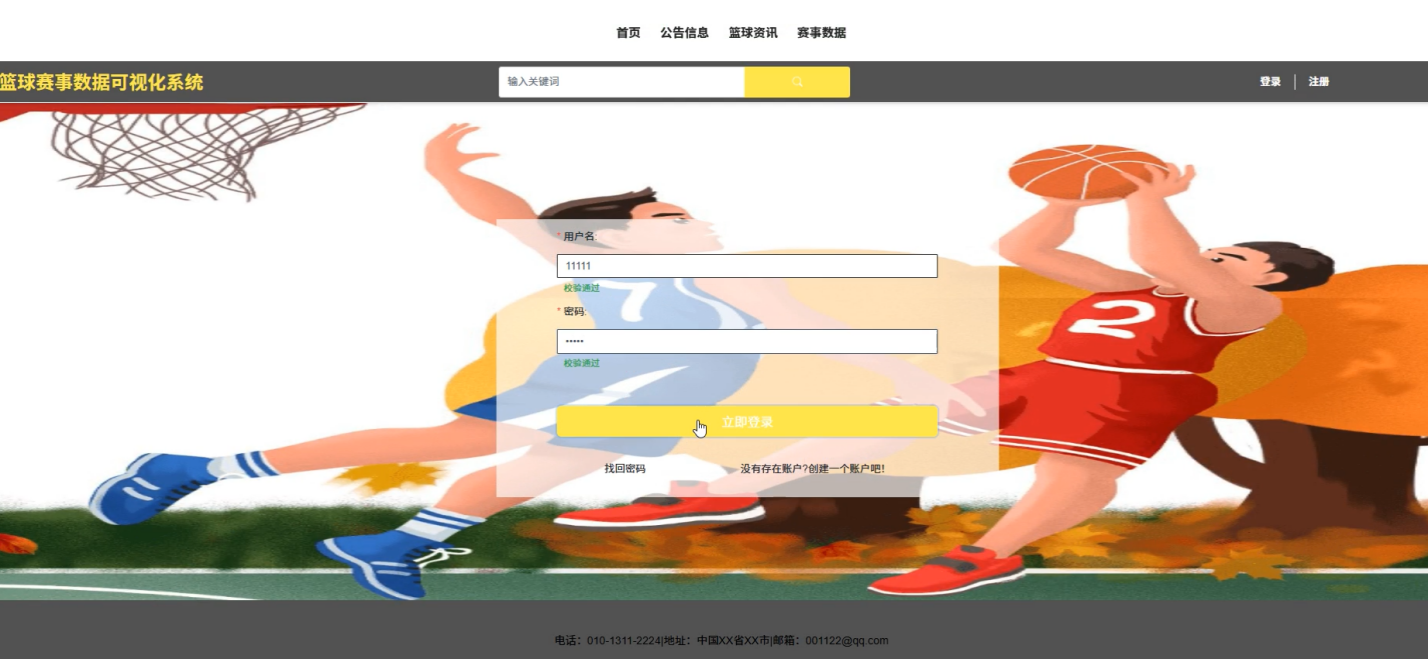
系统包括前端展示和后端数据处理两部分。前端部分采用Django的模板引擎及HTML、CSS和JavaScript等技术,实现了数据的动态展示和用户交互,确保用户能够实时查看赛事数据。后端通过逻辑回归算法对历史赛事数据的训练,能够准确预测球员的表现,并进行多维度的性能分析。同时,系统集成了数据可视化工具,采用图表、趋势线和柱状图等方式,将复杂的赛事数据转化为易于理解的图形化信息,帮助用户迅速洞察关键
二、linux三、sql四、numpy五、pandas六、机器学习七、深度学习。
本文系统介绍了Numpy和Pandas两个Python科学计算核心库。Numpy部分重点讲解了ndarray数组的特性及优势(内存连续、并行运算、高效C实现),详细说明了数组生成、索引切片、形状修改、逻辑运算和统计运算等核心操作,并介绍了矩阵运算规则。Pandas部分以DataFrame为核心,阐述了其数据结构特点、索引设置方法、基本数据操作技巧,以及文件读取功能。两个库相互配合,Numpy提供高
摘要: 量化投资中,市场状态识别(如牛市、震荡市)对策略选择至关重要。2026年流行方案结合LLM(如DeepSeek)作为市场分类器,通过宏观指标判定状态(如高/低波动),再执行经典数学策略。以贵州茅台为例,提出双引擎策略:高波动时保守减仓,低波动时采用均线金叉做多。通过Pandas实现数据拉取、特征计算(波动率、均线)及回测,避免未来函数偏差。结果显示策略收益(5.40%)跑赢基准(-2.05
资源浏览阅读197次。SLAM(Simultaneous Localization and Mapping,即时定位与地图构建)是机器人、自动驾驶、增强现实等领域中的核心技术之一。
Python在数据科学中并非以理论最优或性能第一见长,而是在‘从问题到可运行结果’的全链路中持续降低工程认知负荷。其核心价值源于pandas、numpy、scikit-learn等库对真实场景的长期磨损适配——自动处理BOM编码、混杂日期格式、缺失值语义(如pd.NA)、链式清洗与视图安全索引等设计,本质是将数百万从业者的踩坑经验沉淀为‘最小可行路径’。这种面向交付时效(如下午三点前发图表)、容忍
数据科学不是静态算法应用,而是涵盖数据探查、特征工程、模型训练、服务部署与持续监控的动态闭环。其核心挑战在于如何在不确定性中保障可复现性、协作一致性与生产稳定性。Python 凭借动态类型降低认知负荷、pandas 与 scikit-learn 的接口契约实现无缝流水线、PyTorch 的 autograd 提供可调试梯度流,构建了覆盖研究到上线的最小阻力路径。结合 Poetry 环境隔离、pan
数据科学工具的本质是解决真实场景中的工程效率问题,而非堆砌技术名词。其核心原理在于匹配数据形态(如表格、时序、图像)与任务类型(如预测、归因、部署),并通过版本兼容性、API可维护性与环境一致性保障长期可演进。技术价值体现在降低协作成本、规避‘在我机器上能跑’陷阱、支撑模型从实验到生产的全生命周期。典型应用场景包括金融风控的特征稳定性监控、电商推荐的AB测试快速迭代、工业设备预测性维护的轻量化部署
本篇是 Scratch 转 Python 系列第 9 天,核心学习 **字典(dict)** 这一强大数据结构。字典用"键值对"存数据,就像通讯录用"名字"查"电话号码"一样自然。我们会从字典的创建、增删改查、遍历到嵌套字典,逐步对照 Scratch 积木逻辑讲解,并在综合实战中用字典管理 AI 大模型的参数配置表和学生成绩系统。学完本篇,你就能用字典优雅地管理"有标签的数据"了!
Python第三方库是扩展标准库功能的重要工具,广泛应用于数据处理、Web开发、人工智能等领域。通过封装复杂逻辑和提供领域最佳实践,第三方库如`pandas`和`numpy`显著提升了开发效率和性能。例如,`pandas`在数据清洗和分析方面比标准库的`csv`模块更强大,而`numpy`的底层C实现使其数值计算速度远超纯Python。这些库不仅简化了开发流程,还推动了技术民主化,如`stream
同一个任务跑四家大模型API,速度、质量、免费额度全面对比。GLM-4.7-Flash永久免费,DeepSeek V4-Flash便宜量大,Qwen试用额度90天,GPT-4o-mini需付费翻墙。附横评脚本一键测出你家该用谁。
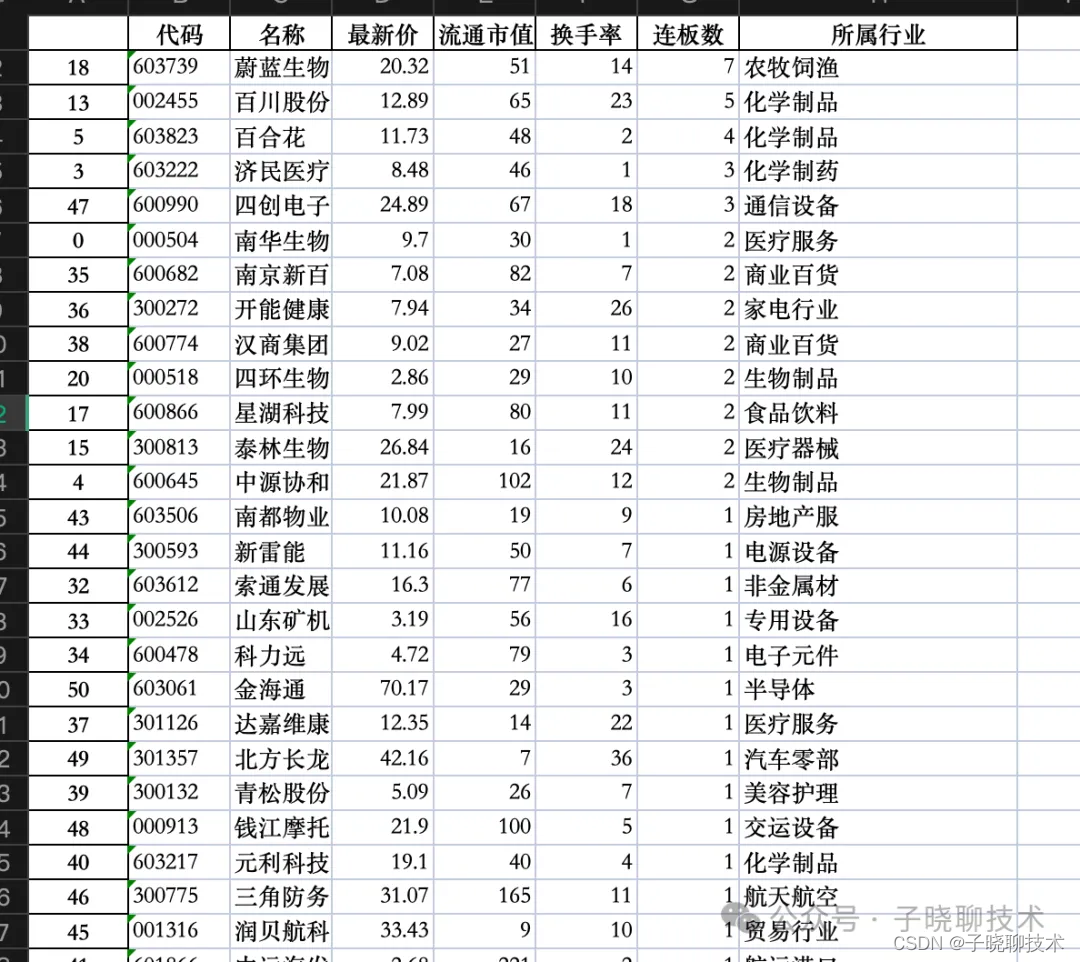
【Python技术】使用akshare、pandas高效复盘每日涨停板行业分析
《AI时代量化开发的困境与解决方案:QuantDash标准化接口实践》 传统金融数据接口(如Tushare、AkShare)存在API陈旧、参数复杂、文档缺失等问题,导致大语言模型(如DeepSeek、Claude)生成的代码常因接口“幻觉”或数据格式混乱而失效。QuantDash通过极简设计的标准化SDK解决这一痛点,其特点包括: 统一多市场接口:A股、港股、美股调用逻辑一致,返回标准Panda
本文介绍了Cursor发布CursorRouter功能后,如何利用AI编程助手(如Cursor、Claude等)构建可靠的量化分析脚本。重点讲解了使用QuantDash SDK获取前复权股票K线数据的技术要点,包括:1)规范API调用方式;2)统一多市场symbol格式;3)明确复权参数;4)字段命名标准化。文章提供了一个基础脚本模板,强调异常处理、环境变量读取等工程化细节,并对比了QuantDa
2026 年 7 月的世界人工智能大会(WAIC)上,"超节点算力"与国产算力底座概念爆火,A 股科技板块随之迎来剧烈波动[1][2]。在 AI 编码 Agent(如 Cursor, Claude Code)高度普及的今天[3],开发者仅需提供高清晰度的 Prompt 即可快速生成回测代码[4]。然而,大模型在编写策略时面临最大的痛点是——缺乏标准、干净、且能直接入参的跨市场 K 线数据。本文将
本文介绍了利用Redis缓存优化QuantDash高频行情数据获取的工程方案。针对分钟级策略回测中API频繁调用导致的效率低下和配额限制问题,作者提出通过本地Redis缓存层存储序列化的Pandas DataFrame数据,实现数据加载速度提升10倍以上。文章包含完整Python实现代码,展示首次远程调用(1.12秒)与缓存命中(0.0035秒)的性能对比,并提供了AI编程助手提示词以扩展缓存清理
【摘要】本文介绍如何用Python实现经典配对交易策略,通过QuantDash金融数据平台解决跨市场数据对齐、价格除权等痛点。文章演示了协整检验、价差Z-Score计算及信号生成的完整流程(代码示例以NVDA-AMD股票对为例),并提供了AI编程提示词和"获取源码-申请API-查阅文档"的三步落地指引。该方案利用标准化数据接口和统计建模,帮助开发者快速构建市场中性套利系统。
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。🧡AI职场汇报智能办公文案写作效率提升教程 🧡专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的
要不重启 jupyter notebook(kernel)试一下?
CSV文件是按照逗号分隔值(Comma Separated Values)格式存储的电子表格数据。每个值都由逗号分隔,并且可以用文本编辑器或电子表格程序打开。CSV文件不需要特定的文件格式,并且可以在许多不同的程序之间共享和转换数据。CSV文件通常包含表格数据,但也可以包含文本和其他类型的数据。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力
2026 年 7 月中下旬,全球宏观市场地缘政治摩擦骤升,中东局势令国际油价再度飙升站上 90 美元/桶,通胀隐忧压制了风险资产弹性[8][9]。比特币(BTC)在触及 21 21 个月低点后小幅反弹至 64,000 美元附近震荡[10][11]。但更引人注目的是,FTX 清算团队宣布将于 7 月 31 日启动第五轮约 9 亿美元的债权人资金派发,部分债权人将获得高达 120% 的索赔额[12]
通过本教程,开发者可掌握在国产操作系统上进行AI开发的全流程,同时支持国产软硬件生态。
pandas
——pandas
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 深开鸿 技术专区
深开鸿 技术专区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区


 AI Agent技术社区
AI Agent技术社区



 DAMO开发者矩阵
DAMO开发者矩阵






 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区



 葡萄城开发者空间
葡萄城开发者空间


