- @2401_84166965
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【代码】最新讯飞AIUI智能机器人6-----人脸识别技术_科大讯飞人脸识别,大数据开发开发面试2024。

中…(img-8XJLoYci-1712999591534)][外链图片转存中…(img-cd7dBL2E-1712999591534)]

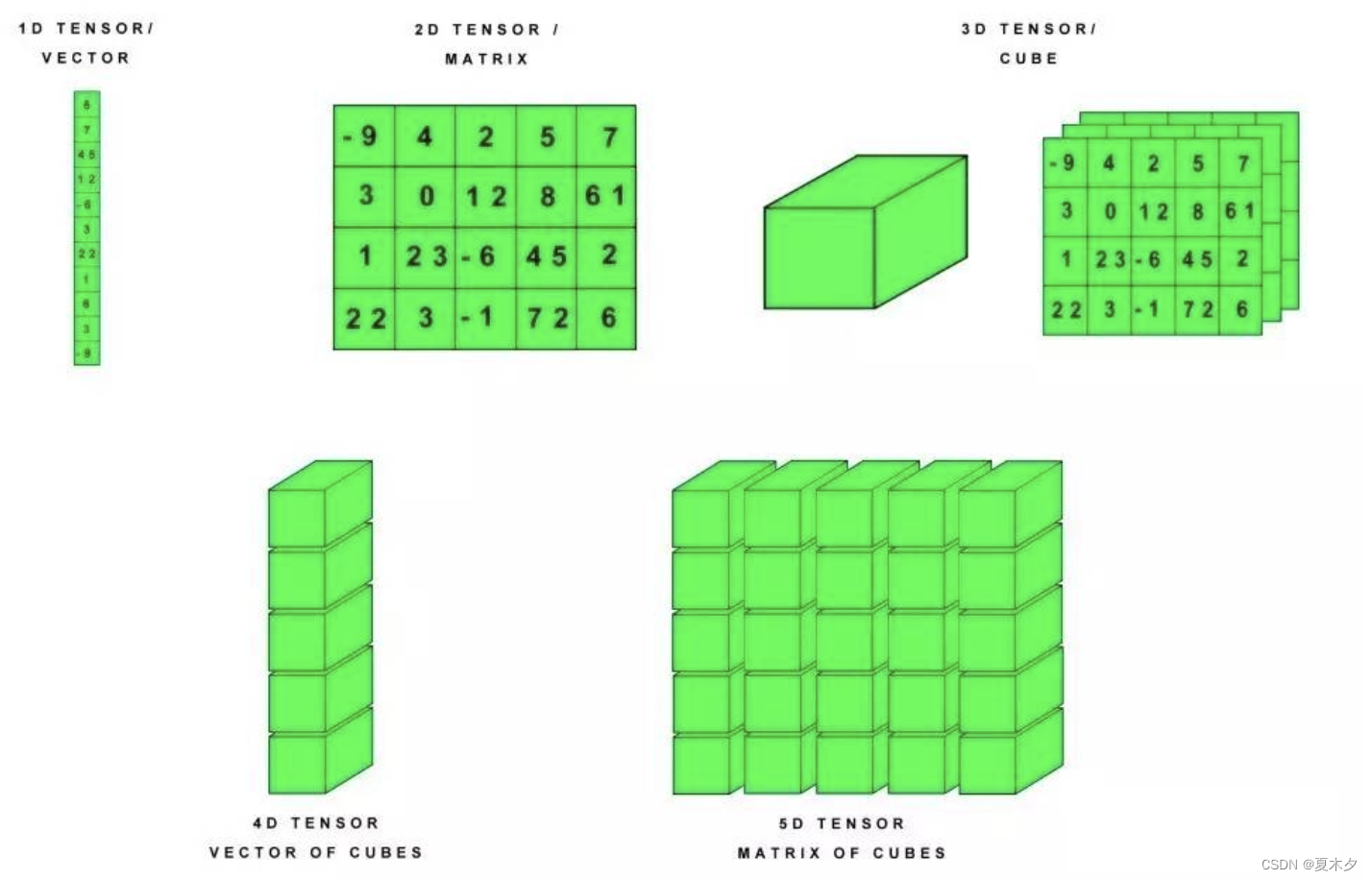
张量是一个多维数组。与 NumPy ndarray 对象类似,tf.Tensor 对象也具有数据类型和形状。tf.keras 是TensorFlow 2.0的高阶API接口,为 TensorFlow 的代码提供了新的风格和设计模式,大大提升了TF代码的简洁性和复用性,官方也推荐使用 tf.keras 来进行模型设计和开发。
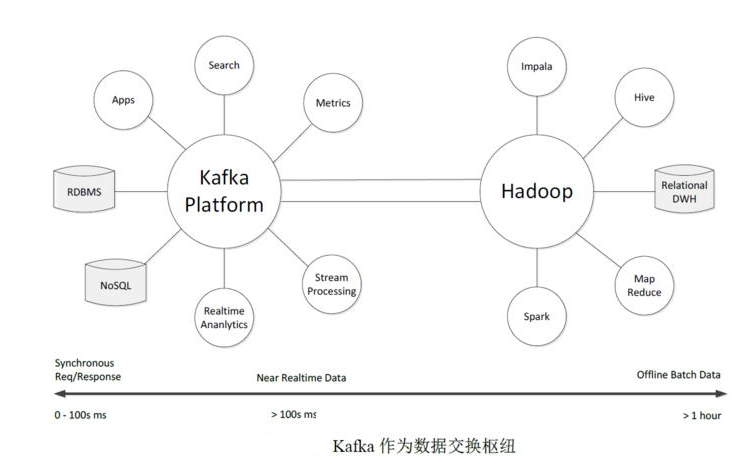
主要分为结构化通道和日志通道;结构化:包含一些常用的关心型数据库,例如:MySQL,Oracle;还有k-v的MongoDB 等等。日志:一些业务上产生的锚点产生的数据等等。
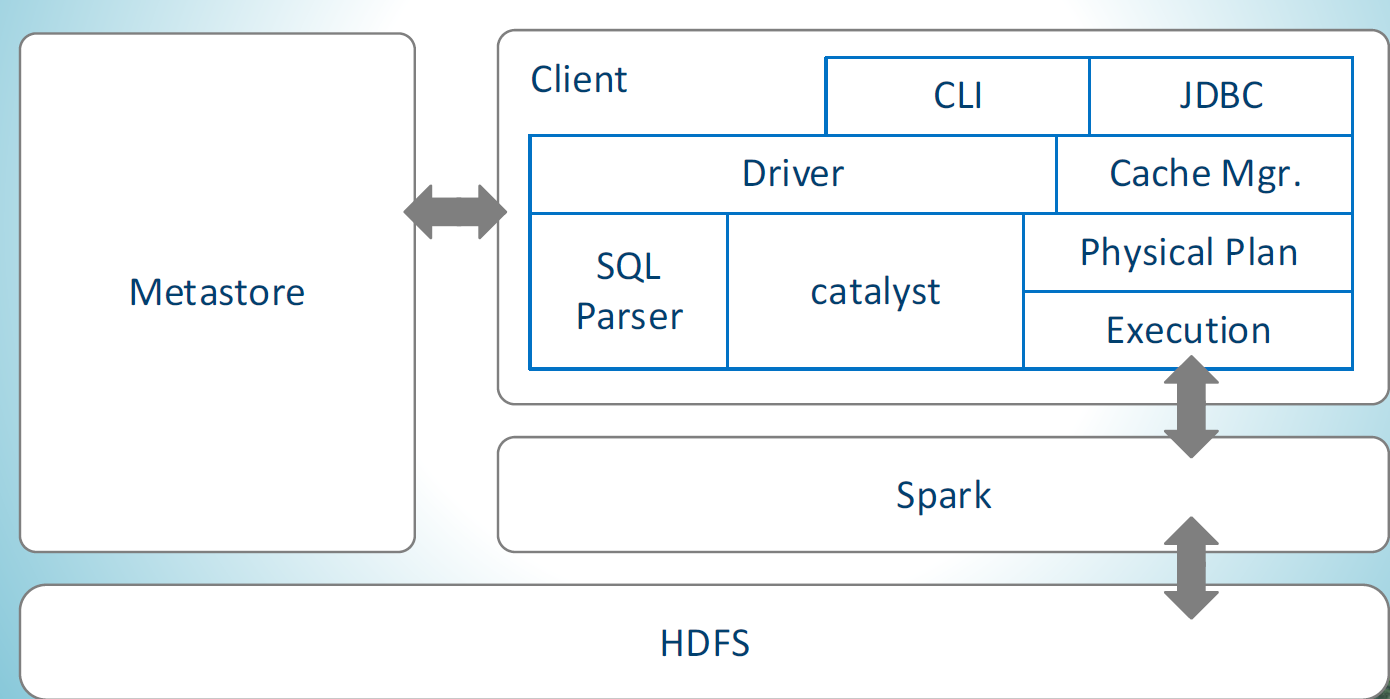
表示树形依赖数的节点,包含节点的id、parentId、子节点列表和是否有子节点的标志。IDE提供模拟器供开发者使用,所以我们首先要下载并安装本地模拟器,然后进行运行工程。树形依赖数通常用于描述复杂的层次结构或组织关系,例如文件系统、组织结构等。表示树形依赖数的节点,包含节点的id、name和子节点列表。**(8)****等待1min,虚拟机就会自动开机,****.gitignore:**代码版本

RDD的和actions。
-- /*+ OPTIONS(‘scan.mode’=‘from-snapshot’,‘scan.snapshot-id’ = ‘1’) */ – 通过动态表选项来指定数据读取(扫描)模式,以及从哪里开始读取。|-- /*+ OPTIONS(‘scan.mode’=‘from-snapshot’,‘scan.snapshot-id’ = ‘1’) */ – 通过动态表选项来指定数据读取(扫描)模式
从文件中读取每一行的UTF-8编码数据。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合 集合类型。文件中的每行内容的集合List。文件中的每行内容的集合List。文件中的每行内容的集合L

【代码】最新讯飞AIUI智能机器人6-----人脸识别技术_科大讯飞人脸识别,大数据开发开发面试2024。
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。:把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。:提供的是一种行列混合存储方式,该方式会把相近的行和列数据放在一块儿,存储比较耗时,查询效率高,也天生压缩。:函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生a