登录社区云,与社区用户共同成长
邀请您加入社区
在构建实时数据湖的过程中,文件接入往往是第一道难关。传统的 FileStreamSource仅能做简单的“文本搬运”,面对复杂格式往往捉襟见肘。本文将深入介绍 FilePulse,一款功能强大的 Kafka Connect 源连接器。它不仅能实时监控目录变化,更内置了强大的过滤器链,支持在摄入过程中直接完成 CSV 解析、日志清洗及字段转换。通过本文的实战案例,你将掌握如何打造“零代码”的数据清洗
然而,在生产环境中,Kafka 的性能和稳定性往往取决于合理的调优配置。Kafka 的核心组件包括生产者(Producer)、消费者(Consumer)、主题(Topic)、分区(Partition)和代理(Broker)。本文从基础概念出发,通过两个完整的 Python 代码示例,展示了如何配置生产者和消费者来平衡吞吐、延迟和可靠性。### 代码示例:消费者调优实践以下代码展示了一个调优后的消费
骑手模式下,地图会精简显示关键信息并高亮展示路线,系统还会提前展示前方 150-300 米路况,方便骑手判断。索尼官方对外介绍称,依托自研的 Xperia Intelligence 计算摄影框架,索尼手机可以智能调整画面的色彩、曝光、虚化效果,能直接生成观感惊艳的成片,让拍摄记录的画面故事感变得栩栩如生。然而,官方这次晒出的样张非但没收获预想中的好评,反而被全网网友疯狂吐槽,开启 AI 优化后的成
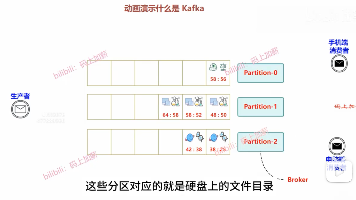
# 总结Kafka 用硬盘实现了接近内存的性能,靠的不是魔法,而是对硬件特性的深刻理解。原因在于:- 传统方式:硬盘 → 内核缓冲区 → 用户态应用 → 内核 socket 缓冲区 → 网卡(至少 2 次上下文切换 + 2 次数据拷贝)- 零拷贝:硬盘 → 内核缓冲区 → 网卡(1 次 DMA 拷贝,无上下文切换)Kafka 的。运行这段代码,你会看到顺序写入的吞吐量是随机写入的几十倍甚至上百倍(
小雷哔哔(ID:xiaoleibbb)查了一下,这位老哥是中国科学技术大学的计算机博士,华为首批八位「天才少年」之一,职级干到了 P20,在华为 2012 实验室负责过大模型训练的软硬协同和基础设施优化。离开华为后自己创业。结果面试官看到他频繁瞥向左边的屏幕,直接就认定他在抄代码,当场让他停止,还放话如果你不能证明你没有在抄代码,面试就无法继续下去了。尤其是现在大模型写代码越来越强的时代,企业更应
的表现,已经开始逼近甚至挑战当前主流闭源模型。从架构设计来看,DeepSeek-V4 不只是简单的参数扩展,而是在多个关键路径上进行了系统性优化。例如混合注意力机制(CSA+HCA)显著降低长上下文推理成本,mHC 结构强化深层网络的稳定性,而 Muon 优化器则提升了训练效率与收敛表现。这些优化技术使得其在长上下文与复杂推理场景中具备更高的性价比。img。
这种协作模式下,你的价值不再是“写更多代码”,而是“做更好的决策”——架构设计、技术选型、质量把控。苹果在WWDC 2026上推动Siri向AI Agent全面升级,与微软、谷歌、Meta等科技巨头的密集发布形成共振——全球AI产业竞争正从“大模型能力竞争”逐步转向“智能体生态竞争”。Agentic Coding(智能体编程)的核心区别在于:AI不再是一个被动的“自动补全插件”,而是一个具备环境感
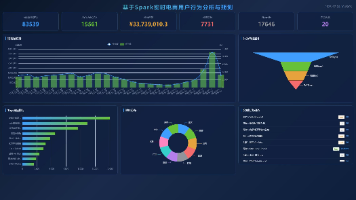
摘要:本文介绍了一个基于Spark的实时电商用户行为分析与预测系统,采用Java+SpringBoot后端和Vue3前端架构。系统通过Kafka实时采集用户行为数据(浏览、加购、收藏、购买),利用Spark MLlib进行销售额线性回归预测,并实现可视化大屏展示。核心功能包括实时统计、预测分析(支持预测误差评估)和管理后台,提供PV/UV、加购数、销售额等指标的动态监控。系统采用前后端分离设计,结
linux 虚拟机部署kafka+zookeeper单机方案
kafka启停、运行脚本(shell),实现传参create, list, describe, delete, consumer, producer start ,stop完成相关操作,简化操作命令
动态Kafka topic信息
本次计划安装三台OpenEuler 22.03 版本操作系统的服务器,用于搭建 kafka和flink 集群。因为从kafka 2.8 版本以后开始不依赖 zookeeper ,同时考虑到需要找一个发布时间早于flink 1.17 的kafka 版本且应尽量稳定,综合考虑下选择了 kafka 3.3.2。
检查配置文件,可能是实际日志路径/etc/kafka/logs与配置文件server.properties日志路径不一致log.dirs=/etc/kafka/kafka-logs。kafka启动依赖于zookeeper启动,查看zookeeper是否启动。
基于观察者模式设计的分布式结构,负责存储和管理架构当中的元信息,架构当中的应用接受观察者的监控,一旦数据有变化,通知对应的zookeeper,保存变化的信息。3、统一集群管理,在整个分布式的环境中,必须实时的掌握每个节点的状态,如果状态发生变化,要及时更新。1、点对点,一对一,生产者生产消息,消费者消费消息,这个是一对一的。消息的生产者发布一个主题,其他的消费者订阅这个主题,从而实现一对多。经纪人
本文详细介绍了如何配置和启动Zookeeper,并将其与Kafka集成。首先,通过复制并编辑zoo.cfg文件,配置Zookeeper的数据存储目录、日志存储目录和客户端连接端口等参数。接着,启动Zookeeper服务,并确保其正常运行。然后,修改Kafka的配置文件server.properties,指定Zookeeper的地址和端口,使Kafka能够使用外部Zookeeper。启动Kafka后
个人理解,仅供参考。一个消息的传递可以分两个过程,a) producer发送消息到 broker,b) consumer从broker读消息并发送。
但是,其无法做到真正的负载均衡,因为实际系统中的每个生产者产生的消息量及每个Broker的消息存储量都是不一样的,如果有些生产者产生的消息远多于其他生产者的话,那么会导致不同的Broker接收到的消息总数差异巨大,同时,生产者也无法实时感知到Broker的新增和删除。在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度Offset记录到Zookeeper上,以便在该消费者进行
Kafka 是一个开源的分布式流处理平台,最初由 LinkedIn 开发,后来贡献给了 Apache 软件基金会。它被设计用于处理实时数据流,具有高吞吐量、可扩展性、持久性和容错性等特点。Kafka 主要用于构建实时数据管道和流式应用程序,如日志收集、消息系统、事件驱动架构等。
Kafka的监控调优如同城市交通治理,需要实时监控(Lag分析)、精准规划(分区计算)和快速响应(动态扩容)三位一体。在美团外卖的实践中,我们通过「基准测试-容量模型-自动扩缩」的闭环体系,成功应对了日均12亿消息的挑战。分区设计黄金法则:单分区TPS不超过基准值的70%消费者调优优先:90%的Lag问题源于消费端预防性监控:建立基于预测的扩容机制正如我们在2023年春节大促验证的:良好的监控体系
重复消费:通过手动提交偏移量、幂等性设计和事务支持来解决。漏消费:通过处理完成后再提交偏移量、重试机制和监控告警来解决。通过这些方法,可以有效减少Kafka中的重复消费和漏消费问题。
在 Kafka 中,leader -1 通常表示分区的领导者副本尚未被选举出来,或者在获取领导者信息时出现了问题。
【代码】SpringBoot集成kafka。
【kafa系列】kafka如何保证消息不丢失Apache Kafka通过多种机制来确保消息不丢失,这些机制包括但不限于副本机制、ISR(In-Sync Replicas)机制、ACK(Acknowledgment)机制、幂等生产者(Idempotent Producer)、事务性发送(Transactional Messaging)以及持久化机制等。
分享了kafka的安装以及简单的使用方式
摘要:本文详细分析了SpringBoot 2.7.18集成Spring Kafka 2.8.11时@KafkaListener的完整调用链路。从启动阶段通过@EnableKafka激活KafkaListenerAnnotationBeanPostProcessor扫描监听方法,到创建ConcurrentMessageListenerContainer并启动消费线程;重点解析了ListenerCon
kafka3.8.0 SASL_PLAINTEXT 认证winds版本 配置简单
配置你的zk和kafka链接信息,add之前Test一下,确保链接信息没有填写错误。(img-uzDYB7r9-1777799626301)](img-gXuQk3Bj-1777799626301)]选择需要删除的topic然后点击x删除。
对于springboot 1.5版本之前的话,需要自己去配置java configuration,而1.5版本以后则提供了auto config,具体详见org.springframework.boot.autoconfigure.kafka这个包,主要有。基于Spring Integration构建,在spring cloud环境中又稍作加工,也稍微有点封装了. 具体详见spring cloud
多维度权衡一致性与可用性的CAP权衡事务开销与性能的平衡实现复杂度与可靠性的折衷关键设计原则幂等性设计是基础事务状态持久化是保障完善的恢复机制是必须演进方向基于AI的事务优化硬件加速的事务处理跨生态系统的统一事务这些经验在阿里双十一、字节春晚红包等极端场景下经过验证,建议根据业务特点进行调优。完美的事务系统应该像精密的瑞士钟表,既要保证每个齿轮的精确运作,又要确保整体系统的可靠运行。
在一个消费者组中,每个分区都只能被组内的一个消费者实例所消费。假设一个消费者组订阅了100个分区,那么他只能扩展到100个线程。,如果消息获取速度慢,增加获取消息的线程数;如果消息处理速度慢,增加消息处理的线程。Consumer获取到消息后,处理消息的逻辑是否采用多线程,由开发者决定。Kafka consumer其实是双线程,用户主线程和心跳线程。最大的缺陷是获取消息和处理消息分开了,不是同一个线
Assigned Replicas 是分配给某个分区的所有副本集合,包括主副本(Leader)和从副本(Follower)。每个分区在创建时通过 replication-factor 参数指定副本数量,AR 是这些副本的完整列表。: Out-of-Sync Replicas 是未能及时与 Leader 同步的副本集合,通常因网络延迟、负载过高或故障导致。: In-Sync Replicas 是与
kafka集群搭建
提交策略选择关键业务:同步提交+事务机制普通业务:异步批量提交+本地持久化分析业务:自动提交+允许重置性能优化方向调整__consumer_offsets分区数(建议50-100)优化提交频率(平衡延迟与吞吐)实施分级存储策略监控关键指标提交成功率消费延迟Offset跳跃检测分区均衡度灾难恢复方案定期备份Offset到外部系统实现自动化重置工具建立跨集群同步机制99.99%的Offset提交成功率
flinksql kafka hudi kafka消费方式
也可以自动kafka自带的zookerper。--from-beginning为限制消费从头开始消费。kafka安装先安装zookeeper,jdk。# 启动独立安装的zookeeper。创建一个topic:test20250604。# 关闭zookeeper。
sasl.mechanism为PLAIN或者SCRAM-SHA-256,根据自己kafka的加密方式选择。sasl.jaas.config 为以下两种,根据自己kafka的加密方式选择,注意最后的分号不要漏掉了。在选项-plugins Manager中搜索kafka,然后将对应的kafka插件安装。security.protocol为SASL_PLAINTEXT。kafka brokers中填写自
Broker 状态监控:ZooKeeper 监控每个 Broker 的状态,如果某个 Broker 下线,ZooKeeper 会通知其他 Broker 和客户端,以便进行故障转移和负载均衡。分区分配:Kafka 的每个主题可以分为多个分区,ZooKeeper 负责管理这些分区的分配情况,确保每个分区都有一个 Leader 和多个 Follower。ZooKeeper 主要用于管理和协调 Kafka
Kafka 是一款开源的分布式流处理平台,最初由 LinkedIn 开发,后由 Apache 基金会维护。它被设计用于高吞吐、可扩展的实时数据管道和流处理场景。Kafka 的核心功能包括发布和订阅消息流、持久化存储数据以及实时处理数据流。其架构基于生产者(Producer)、消费者(Consumer)、主题(Topic)和分区(Partition)等概念,支持水平扩展和高容错性。Kafka 广泛应
我整理的。
kafka---4.0win环境集群部署与springboot整合使用学习笔记--附压缩包
用于从Kafka Topic中消费消息并将其输出到控制台,适用于调试和测试。:用于运行自定义的消费者应用程序,适用于实现复杂的消费逻辑。在大多数情况下,如果你只是想快速查看Kafka Topic中的消息内容,是更方便的选择。如果你需要运行一个自定义的消费者应用程序,则是更合适的工具。和是Kafka中两个不同的命令行工具,它们的用途和功能有所不同。以下是它们的主要区别:这条命令用于使用Kafka的命
感觉最主要的道理就是,生产者不用管上一条发送的消息,有没有被消费者消费,只管自己往消息队列那里发就行了。这样就是一个不管一个,可以全力专心的干好自己的事,只要消息队列本身不挂就行。SDK software develop kit , 软件开发工具箱,通常包含了一个或者多个API,并对其进行了封装和增强,使其更加好用。不同的队列,称为分区,partition是分区,类似于电视上的不同的频道。先要订阅
生产者调用send方法发送消息时,不会立即发送,而是先进入一个内存缓冲区,其核心结构是一个concurrentmap,以消息的key为key,value是一个deque,也就是说每一个分区都占一个消息队列,消息发送的时机是达到一定时间或者分区满了才会发送,分区越多,数据越难达到满的状态,发送次数越多,网络io越严重,而且分区越多,而且多个分区竞争发送机会是靠reentrantlock+condit
点击下方名片免费领取!!
操作详情状态查看当前配置全量参数分析✅动态改保留策略nginx-log加✅创建 compact topicuser-cache— compact策略,同key去重✅写入 compact 数据同key多值写入验证✅创建 SCRAM 用户admin / producer / consumer 共3个✅创建 JAAS 配置Broker端 + Client端✅创建 ACL 脚本完整的权限管理脚本✅创建 S
bin/kafka-consumer-groups.sh --bootstrap-server $nodes --group $groupname --reset-offsets --all-topics --to-earliest --execute # 重设消费者组位移(待验证)bin/kafka-console-consumer.sh --bootstrap-server $nodes --
kafka
——kafka
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 EazyDevelop社区
EazyDevelop社区


 openEuler 社区
openEuler 社区

 AI编程社区
AI编程社区





 智能体开发者社区
智能体开发者社区


 快递鸟社区
快递鸟社区