




- @qq_17246605
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
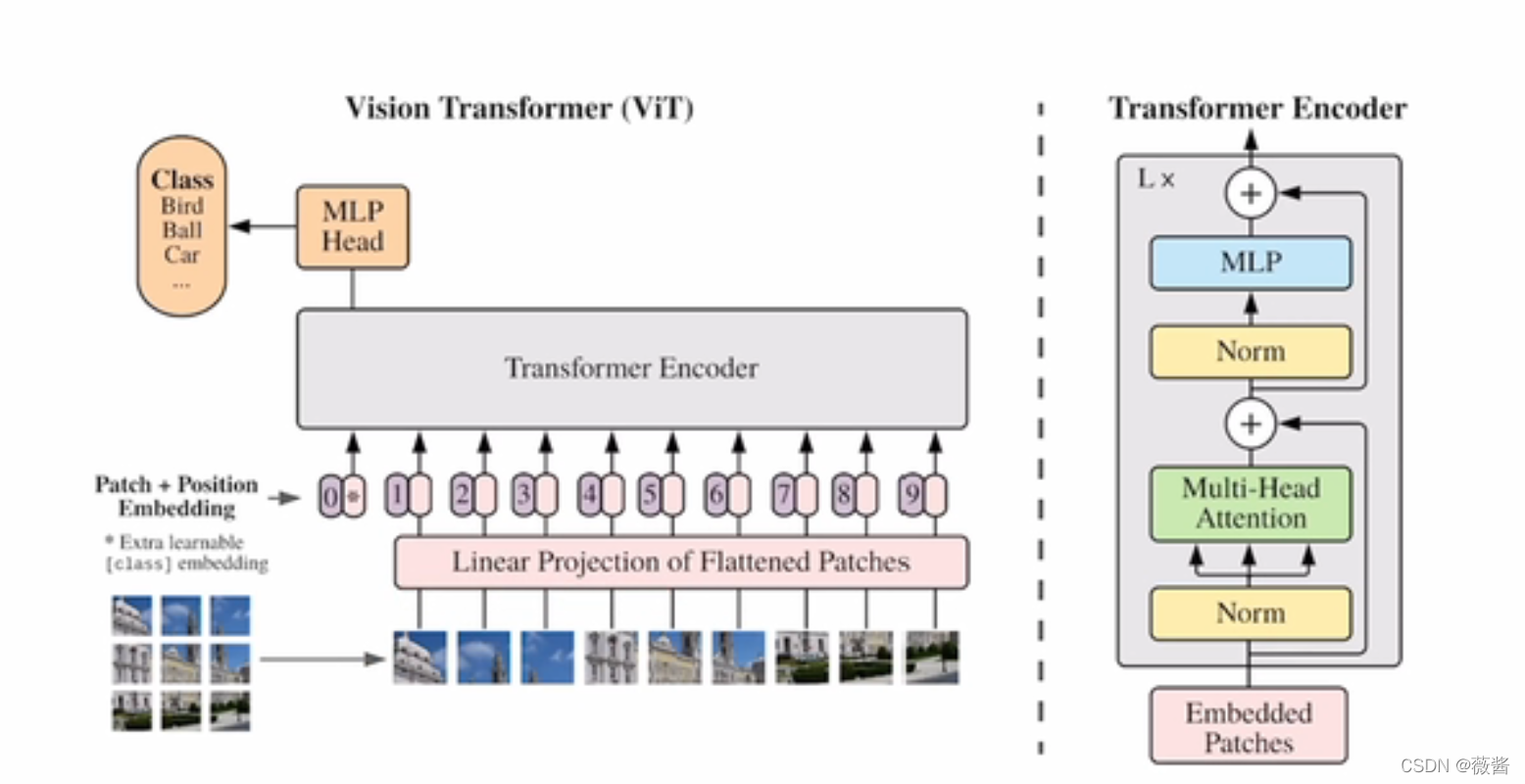
VIT就是Vision Transformer。目录1.Transformer在视觉领域上使用的难点:2.输入序列长度的改进3.VIT对输入的改进1.Transformer在视觉领域上使用的难点在nlp中,输入transformer中的是一个序列,而在视觉领域,需要考虑如何将一个2d图片转化为一个1d的序列,最直观的想法就是将图片中的像素点输入到transformer中,但是这样会有一个问题,因为
1.析取使用括号,匹配括号里的任意字符[abc]dee],即匹配 adee,bdee,cdee[Ww]ood,即匹配 Wood和wood使用范围:[a-z] 表示匹配小写字母[A-Z] 表示匹配大写字母2.非析取[^Ss][^A-Z]非大写字母,即匹配小写字母或其他字符。3.更多析取more|less,匹配more或者是lessa|b|c,即[a...
多模态表示学习是指从多种不同类型的数据源(如图像、文本、音频、视频等)中学习统一的、有意义的特征表示的过程。

本篇将会带大家尝试下,使用clickhouse客户端工具(clienthouse-client)以及python代码的方式,来进行数据的导入和查询。

那么如何使用chatgpt做思维导图呢?
那么如何使用chatgpt做思维导图呢?
VIT就是Vision Transformer。目录1.Transformer在视觉领域上使用的难点:2.输入序列长度的改进3.VIT对输入的改进1.Transformer在视觉领域上使用的难点在nlp中,输入transformer中的是一个序列,而在视觉领域,需要考虑如何将一个2d图片转化为一个1d的序列,最直观的想法就是将图片中的像素点输入到transformer中,但是这样会有一个问题,因为
本文简单介绍了下图像生成相关的一些模型。本来想从吴恩达的deepai课程开始写的,但是感觉还是不够简单,推荐跟着李沐学AI里的DALL·E 2,我个人觉得讲的蛮清楚的。,从28分开始讲解。
