




- @Joker_Q
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Python数据分析与应用大作业使用学习过的知识(Numpy数值分析基础、Matplotlib数据可视化基础、Pandas统计分析基础),对data.csv用户用户用电量数据进行相关处理,其中数据中有编号为1-200的200位电力用户,DATA_DATE表示时间,如2015/1/1表示2015年1月1日,KWH为用电量。请完成以下工作:一、将数据进行转置,转置后行为用户编号、列为日期、值...

操作题:利用鸢尾花数据实现数据加载、标准化处理、构建聚类模型并训练、聚类效果可视化展示及对模型进行评价一、数据加载from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitdata = load_iris()train_data, test_data, trai...
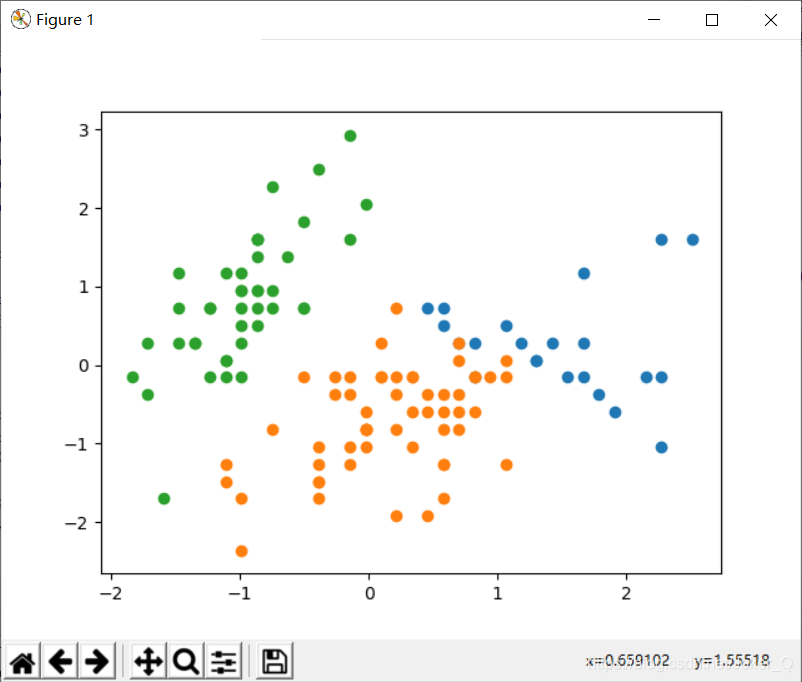
操作题:利用鸢尾花数据实现数据加载、标准化处理、构建聚类模型并训练、聚类效果可视化展示及对模型进行评价一、数据加载from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitdata = load_iris()train_data, test_data, trai...
本文介绍了一种新的文本到图像生成模型(Text-Image Generative Models)的评估方法,其采用了VQA来衡量生成图像与其文本输入之间的忠实度,可以从更细粒度的层面评估文本图像生成模型的性能,例如颜色、数量以及组合关系。

使用背景:需要保存通过包括但不限于torch及numpy创建的数据(在这里主要测试的是通过网络训练,提取到的图片的特征向量)数据格式及大小:在这里使用torch创建数据,没用使用GPU(已经是该配置下能运行的最大数据量了,否则会爆内存)运行环境:具体参数参考R9000P 2021 3070版本;数据存储在新加的固态上型号是三星1tb 980测试内容:测试python主要的几种存储数据方式包括:h5
本文介绍了一种新的文本到图像生成模型(Text-Image Generative Models)的评估方法,其采用了VQA来衡量生成图像与其文本输入之间的忠实度,可以从更细粒度的层面评估文本图像生成模型的性能,例如颜色、数量以及组合关系。
使用背景:需要保存通过包括但不限于torch及numpy创建的数据(在这里主要测试的是通过网络训练,提取到的图片的特征向量)数据格式及大小:在这里使用torch创建数据,没用使用GPU(已经是该配置下能运行的最大数据量了,否则会爆内存)运行环境:具体参数参考R9000P 2021 3070版本;数据存储在新加的固态上型号是三星1tb 980测试内容:测试python主要的几种存储数据方式包括:h5
操作题:利用鸢尾花数据实现数据加载、标准化处理、构建聚类模型并训练、聚类效果可视化展示及对模型进行评价一、数据加载from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitdata = load_iris()train_data, test_data, trai...