登录社区云,与社区用户共同成长
邀请您加入社区
1996年,牛津大学的 Gavin Lowe 用模型检测工具 FDR 发现了一个惊人的事实:著名的 Needham-Schroeder 公钥认证协议——这个被密码学界信赖了整整17年的协议——存在严重的中间人攻击漏洞。相比传统的穷举搜索,RL 方法的最大优势是智能剪枝——Agent 学会优先探索"有希望"的攻击分支,而不是在无攻击的良性路径上浪费算力。我们距离"把 RFC 扔进去,自动吐出安全证明
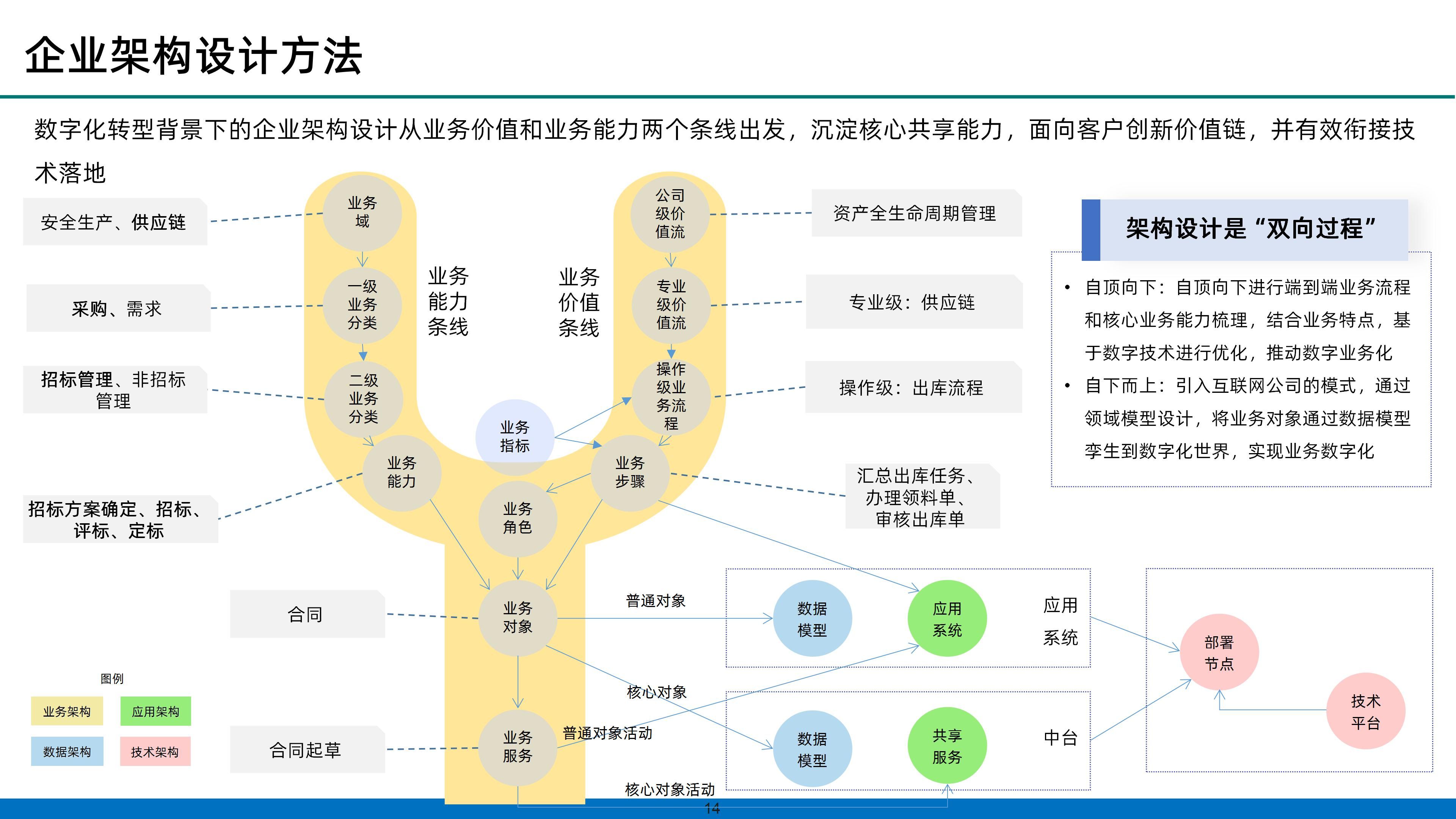
企业架构设计作为数字化转型的核心环节,旨在构建一个能够支撑企业战略目标、业务需求和技术创新的灵活、高效、可扩展的IT架构体系。本《数字化转型企业架构设计手册》旨在为企业提供一套系统性的架构设计方法论和实践指南,帮助企业顺利推进数字化转型进程。《数字化转型企业架构设计手册》是企业数字化转型过程中的宝贵资源,它不仅为企业提供了一套科学的架构设计方法论,还为企业架构师和决策者提供了实用的操作指南。1.提
Flink 第1章 Flink资源与内存模型资源配置调优开发了一些程序,那么怎么评估这些程序所需要的资源配比这些呢?比如使用标准的Flink任务提交脚本 Generic CLI模式(通用客户端模型)从1.11开始,增加了通用的客户端模型 使用-D指定kv变量(这里演示以1.13.2为准)。bin/flink run \-t yarn-per-job \-d \-p 5\# 执行并行度-Dyarn.
Raycast是一款为macOS设计的效率启动器,它不仅能快速启动应用和执行系统命令,还提供了一个功能强大的扩展API,允许开发者创建自定义脚本和小型应用(称为扩展)来极大提升工作流效率。与传统应用开发不同,Raycast扩展轻量、聚焦,旨在无缝集成到用户的瞬间操作中,为macOS生态增添无限可能。
提醒:关键在于datax.core.statistics.communication.LocalTGCommunicationManager类的修改,其中各个方法中入参jobId对应在调用类里面修改,尽量用super.getJobId()获取jobId,修改起来容易。2、修改方案,将jobid作为taskGroupCommunicationMap的key,在注册和update和获取Communic
本文深入解析了跨平台开发中的核心问题——指令集架构(ISA)与操作系统差异,详细介绍了AMD64、ARM64和Mac-Intel三种主流架构的特点。通过Python代码示例展示了如何检测系统环境,并提供了Docker跨平台构建、错误排查等实用技巧。文章还剖析了Windows-ARM64的转译机制和Linux服务器的多样性,最后通过一个跨平台系统监控工具实战,演示了统一API调用的实现方法。针对不同
人工智能大数据时代下的工程伦理问题探讨一、引言人工智能技术以及大数据建设作为二十一世纪新兴技术,给人们带来更便捷的生活,社会中涌现出许多新技术,人与人工智能也越来越密不可分。伦理的本意是人伦道德之理,具体指人与人相处的相应道德准则。而现代科技的发展,使得伦理不仅只限于人与人的交往,当前出现了网络伦理,医学伦理,生物伦理等新的概念,当然了还有人工智能伦理学的研究。人工智能道德风险即人工智能技术带来的
本文介绍了在Amazon Glue中使用私有Python包仓库的解决方案。由于网络限制或公共镜像源不稳定,提出了通过创建私有仓库的方法:使用Docker容器构建与Glue版本匹配的wheel包,上传至S3并生成索引文件,配置桶策略限制VPC访问。在Glue Job中通过--additional-python-modules和--python-modules-installer-option参数指定
智能指针的选择应基于所有权语义:优先用unique_ptr表达独占所有权,用shared_ptr表达共享所有权,并用weak_ptr解决循环引用。实战中,始终使用make_unique和make_shared创建指针,以提高异常安全性和性能。避免将裸指针与智能指针混用,并定期使用工具(如Valgrind)检测内存问题。通过合理应用这些准则,可构建出既安全又高效的C++应用程序。
在特定领域(如游戏开发、高频交易等)对性能有极致要求的场景下,专家级程序员可能会超越标准库提供的内存管理机制。C++的内存管理是一个从基础规则到高级艺术循序渐进的过程。新手应从理解栈和堆的基本概念开始,并迅速拥抱RAII和智能指针,以构建安全可靠的程序。随着经验的积累,需要深入理解拷贝控制、移动语义等更复杂的概念。最终,在特定高性能领域,可以探索自定义内存管理策略。掌握这门“艺术”的核心在于平衡:
p: 相较于传统类,记录类自动生成`getter`、`equals()`、`hashCode()`和`toString()`方法,减少了模板代码,同时保证了数据的不可变性,是领域模型设计的理想选择。p: 这一特性减少了类型歧义,尤其在复杂继承结构中,可大幅降低`instanceof`滥用的风险,并与模式匹配结合,为`switch`提供更强的静态类型检查。p: 通过`yield`自动返回值,简化了条
摘要:C++智能港口码头作业系统面临多码头异构接口、实时性要求高、复杂作业场景等测试挑战。采用分层自动化测试策略,结合GoogleTest等框架实现单元测试到端到端测试全覆盖。通过数据驱动、CI/CD持续集成及故障注入测试,系统延迟降低25%,作业效率提升30%,自动化测试覆盖率提升至90%。结果表明,该测试方法有效保障了C++港口系统在高并发、复杂环境下的稳定性和性能表现。
本文探讨了C++在智慧水务调度系统中的核心应用,重点分析了系统架构及测试挑战。系统包含数据采集、调度优化、异常检测和数据可视化四大模块,面临高实时性、多设备接口和安全性的测试难点。研究提出分层测试策略,通过单元测试、集成测试和仿真场景测试确保系统可靠性。采用数据驱动的算法验证方法,结合并行计算和缓存优化提升性能。系统实施冗余控制和异常自愈机制,最终实现调度延迟降低30%、异常响应缩短35%等显著成
摘要:C++凭借高性能优势成为WebSocket协议实现的核心技术,构建了包含连接管理、协议解析、消息收发等模块的高性能通信系统。针对低延迟、高并发等测试挑战,采用分层测试策略,包括单元测试、模块集成测试及压力测试。通过异步IO、零拷贝等技术实现性能优化,并建立容错与安全机制。测试成果显示系统延迟降低28%,支持20000+并发连接,消息投递成功率99.6%。C++的高效底层控制能力为实时通信系统
本文探讨了前端性能优化的关键挑战与解决方案。针对资源加载慢、渲染阻塞、高并发压力等问题,提出了包括代码拆分、资源压缩、DOM优化等性能提升策略。同时介绍了性能监控工具如Performance API、Sentry等,用于实时跟踪加载时间、JS错误等指标。实践证明,优化后首屏加载时间可降低40%,FPS提升至60+。文章强调,通过资源优化、执行效率提升和闭环监控,能构建高效可观测的前端应用,显著改善
摘要:云原生与边缘计算融合为Java系统运维带来新的挑战,包括多节点管理、资源限制、网络延迟等问题。通过容器编排、性能监控、日志聚合等工具构建运维体系,结合动态资源调度和智能告警策略优化性能。实践表明,该方案可降低响应延迟30%、提升并发能力25%,并通过自动化运维减少人工干预50%。关键经验包括轻量化资源优化、全链路监控和智能调度,最终实现高效稳定的云边协同Java系统部署。
Python 3.10引入了多项重要更新:结构模式匹配功能(PEP 634)提供了类似switch-case的语法,支持复杂数据结构匹配;性能优化提升了字节码执行效率和内存管理;新增了更严格的类型检查(PEP 563)和parenthesized上下文管理器。这些改进使代码更简洁高效,同时优化了执行速度和内存占用。迁移时需检查依赖兼容性并重构条件语句。Python 3.10通过这些特性增强了开发体
摘要: C++和Java是两种广泛使用的编程语言,各具特点。C++性能高,适合底层开发和计算密集型任务,但内存管理和跨平台性较差。Java开发效率高,具备跨平台优势,适合企业级应用和Web开发,但性能略逊于C++。选择应根据项目需求:C++适用于高性能、嵌入式系统等领域;Java更适合跨平台和企业应用开发。开发者需权衡性能、开发效率和适用场景做出选择。
本文介绍了如何利用Python结合DeepSeek模型实现CSV数据的批量处理与分析。通过pandas进行数据清洗、特征工程,使用DeepSeek时序预测模型对未来销量进行预测,并借助matplotlib/seaborn生成可视化图表,最后用reportlab创建PDF分析报告。文章提供了完整代码示例,涵盖数据加载、预处理、建模预测到报告生成的完整流程,适合数据分析师、算法工程师等需要处理大量CS
摘要: DeepSeek作为先进AI模型,通过自然语言理解与代码生成能力,为编程教育提供高效解决方案。它能自动生成个性化教学案例(如Python字典应用)和课后习题解析(含多角度解题思路),帮助教师减轻备课负担,为学生提供即时反馈与针对性练习。其优势包括内容快速生成、精准匹配知识点、多场景应用适配,同时需注意内容审核、避免过度依赖。未来,结合交互式学习与项目支持,DeepSeek有望推动编程教育个
摘要:本文介绍了达梦数据库(DMDB)与DeepSeek AI平台在国产化环境下的协同应用,重点阐述了数据结构化提取的完整解决方案。内容包括技术背景、环境搭建、核心实战流程、高级应用场景和性能优化策略,涵盖从文本预处理、实体识别到结果存储的全流程实现。通过金融报告分析、多模态数据处理等案例,展示了该方案在实际业务中的应用价值,并提供了安全合规实践和典型问题解决方法。测试数据显示,该组合方案能高效处
文章目录一、数据科学家 与 数据工程师 与 统计学家 之间的区别1.1、数据科学家的发展领域1.2、数据工程师及其演变1.2.1、数据工程师的主要职责1.2.2、成为成功的数据科学家所需的技能1.2.2.1、数据科学家需要具备基本工具方面的知识1.2.2.2、数据科学家需要对基本统计有正确的理解1.2.2.1、一个好的数据科学家必须了解机器学习的各个方面一、数据科学家 与 数据工程师 与 统计学家
做数据分析除了需要良好的数学统计基础,对数据的敏感性,有一个熟练使用的“家伙什儿”是很重要的,那么常用的数据分析挖掘工具都有哪些呢?有哪些又是适合自己工作场景的呢?1 E...
导语 | 随着业务的发展,系统日益复杂,功能愈发强大,用户数量级不断增多,设备cpu、io、带宽、成本逐渐增加,当发展到某个量级时,这些因素会导致系统变得臃肿不堪,服务质量难以保障,系统稳定性变差,耗费相当的人力成本和服务器资源。这就要求我们:要有勇气和自信重构服务,提供更先进更优秀的系统。文章作者:刘敏,腾讯基础架构研发工程师。前言自今年三月份以来天机阁用户数快速上涨,业务总体接入数达到100
一、NoSQL简介1、简介NoSQL最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。NoSQL有如下优点:
big data
——big data
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI Agent技术社区
AI Agent技术社区











 DAMO开发者矩阵
DAMO开发者矩阵



