登录社区云,与社区用户共同成长
邀请您加入社区
本文分析了Flink多表JOIN导致状态爆炸的问题及解决方案。作者在处理10张MySQL CDC表关联的实时任务时,发现状态从几百MB暴涨至12GB。问题根源在于Regular JOIN会永久保存中间状态,TTL设置面临两难:太小会导致数据丢失,太大则内存爆炸。 Flink 2.1提出的MultiJoin方案通过"零中间状态"设计(用计算换存储)从根本上解决问题,但当前生产环境(Flink 1.1
前言一、Flutter Hive 数据库简介1、什么是 Hive2、Hive 的核心优势3、Flutter 常见本地数据库对比4、Flutter 各数据库适用场景二、Flutter Hive 完整开发流程1、配置依赖2、初始化 Hive 数据库3、Hive 基础数据操作4、自定义对象存储 TypeAdapter5、监听数据变化三、生产环境示例 : 封装与工程化1、数据库管理单例2、业务层数据仓库封
【代码】Filter快速入门 Java web。
基于智慧校园的的大数据平台的开发是基于django框架的基础上,采用Python语言进行开发,采取MySQL作为后台数据的主要存储单元实现了本系统的全部功能。基于智慧校园的的大数据平台,具有校园公告、天气预报、学生信息、教师信息、学校设施、活动中心、图书信息、课程信息等功能。
系统分为参赛用户、评委用户和管理员三个角色,每个角色有不同的功能权限。参赛用户可以浏览赛事信息、提交参赛信息、对赛事进行评价等;评委用户在此基础上具有对参赛作品进行评价和打分的权限;管理员则能够管理系统用户、赛事信息、赛事评价和结果等。系统的核心功能包括首页展示、通知公告、比赛信息、个人账户和个人中心。用户可以在首页查看最新的赛事信息和通知公告,同时通过比赛信息模块了解赛事的详细信息。个人中心包含
小区车辆监控系统分管理员功能模块、用户功能模块。(1)角色:管理员的功能分析管理员是小区车辆监控系统当中的最高权限拥有者,主要功能有登录、后台首页、车位信息管理、停车入场管理、车辆离场管理、区域名称管理、系统管理、留言管理、通知公告管理等。(2)角色:普通用户的功能分析普通用户的账号是首先需要进行注册,注册通过后通过账号密码可以登录到系统中,进行相关操作,注册登录、首页、通知公告、留言区、车位信息
原因:原因是ORC 为了处理混合历法/闰秒等边界情况,使用了 ThreeTen-Extra 的 HybridChronology,进而需要 org.threeten.extra.chrono.AbstractDate。解决:加上jar依赖 add jar hdfs://xxx/xxx/threeten-extra-1.7.0.jar;背景:Hive3.1.3升级orc版本为了支持zstd,orc版
计算机毕业设计Django+Vue.js中华古诗词知识图谱可视化 古诗词智能问答系统 古诗词数据分析 古诗词情感分析模型 自然语言处理NLP 机器学习 深度学习
【代码】C#实现Snowflake建表语句转Hive建表语句。
计算机毕业设计Django+Vue.js电影推荐系统 电影可视化 大数据毕业设计(源码+文档+PPT+讲解)
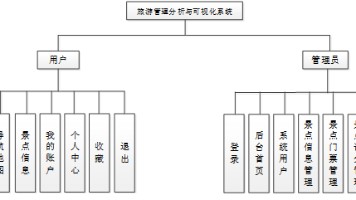
旅游管理分析与可视化系统的功能主要分为前台和后台两部分。在前台,用户可以根据自己的需求进行注册和登录,然后浏览旅游景点信息。他们可以根据不同的条件和偏好进行景点推荐,并查看其他用户对选中景点的评论和评价。用户还可以对他们喜欢的景点进行收藏和分享,以便日后参考和分享给其他用户。在后台,系统管理员扮演着不同的角色,分为管理员和普通用户。管理员主要负责对整个系统的管理和维护。他们可以管理用户信息,包括添
计算机毕业设计Django+Vue.js高考推荐系统 高考可视化 大数据毕业设计(源码+LW文档+PPT+详细讲解)
本文介绍了用户行为数据采集平台的设计与实现方案。主要内容包括:1)数据仓库中用户行为数据的分类(页面浏览、动作记录、曝光记录等)和日志格式;2)采用代码埋点、可视化埋点和全埋点三种方式收集数据;3)设计Flume+Kafka+HDFS的数据采集链路,重点说明TailDirSource支持断点续传和KafkaChannel提高传输效率的优势;4)通过拦截器实现数据格式校验。该方案具有高可靠性和实时性
本文介绍了一个基于大数据和AI技术的智能农业分析系统。项目整合Spark、Hadoop和DeepSeek-R1等技术,构建了多模态数据处理平台,实现农作物产量预测和订单分析。系统采用TensorFlow深度学习框架,结合LSTM-GRU混合神经网络模型,并开发了动态可视化模块展示分析结果。创新点包括多模态数据融合和自适应可视化决策引擎,支持千万级数据实时处理。项目提供Web端交互界面,涵盖农产品分
本文详细解析了E-Brufen应用核心数据仓库MoodStorage的实现方案。该系统采用三层架构设计:UI层通过MoodPicker和MoodChart等组件交互,数据层由MoodStorage仓库管理,底层使用Hive键值存储。文章从架构决策(选择Hive而非SQLite)切入,逐步剖析模型层设计(MoodType枚举和MoodEntry数据类)、CRUD操作实现、条件查询与统计聚合功能,以及
本系统前端部分基于MVVM模式进行开发,采用B/S模式,后端部分基于python的Django框架进行开发。前端部分:前端框架采用了比较流行的渐进式JavaScript框架Vue.js。使用Vue-Router和Vuex实现动态路由和全局状态管理,Ajax实现前后端通信,Element UI组件库使页面快速成型。后端部分:采用Django作为开发框架,同时集成Redis等相关技术。
网上花店管理系统的主要使用者分为管理员和注册用户,实现功能包括管理员:系统用户、取消订单管理、退货信息管理、商品分类管理、商品库存管理、商品入库管理、系统管理、商城管理、权限管理等,用户:首页、商城中心、商城管理(我的购物车、我的订单、我的地址)、个人中心(个人首页、取消订单、退货信息、订单配送、收藏)等功能。由于本网站的功能模块设计比较全面,所以使得整个鲜花销售管理系统信息管理的过程得以实现。
基德公司考勤系统在前端设计采用多种技术交互使用达到界面简洁大方,使用Python作为系统的编译语言,对于之前的分析所产生的问题进行解决,功能模块设计后进行编码实现具体功能:登录模块:使用者必须输入正确的账号与密码才能访问系统。部门信息管理模块:相关权限用户可以进行部门信息的添加、查询、修改、删除操作,也可以对部门名称等数据项进行单独操作,设置数据类型等参数。公告管理模块:如果登录当前管理员有公告管
ervlet 是 Java Web 的起源,此前 Java 仅用于桌面应用,它首次让 Java 进入 Web 领域,为后续 JSP、Struts、Spring MVC 等技术奠定基础。在实战中,如 2005 年国企 OA 系统开发,其编译型特性和强类型检查保障系统长期稳定,适配订单、支付等核心业务场景。即便在云原生时代,Spring Boot 等框架仍依赖其底层能力,在容器化、微服务、Server
。该系统将利用现代信息技术,如Django框架,实现校车信息管理、校车预约管理、校车派车管理、物品捎带管理、捎带信息管理、意见反馈管理和通知公告管理等功能,提升校车运营效率和乘车体验。通过对校车调度及乘车管理系统的研究和开发,旨在提高校园交通管理的智能化水平,优化校车服务流程,提升师生出行的便利性和安全性。这将有助于提升学校管理水平,改善校园交通拥堵问题,提高师生的出行效率和舒适度,为教育教学工作
摘要:Cookie是Web开发中保持HTTP状态的关键技术,通过客户端存储少量数据实现身份识别。文章总结了Cookie的核心机制、安全配置和常见陷阱:1. 会话Cookie和持久Cookie的创建与读取;2. 必须设置HttpOnly、Secure、SameSite等安全属性;3. 典型问题包括路径/域名配置错误、跨域限制和数据超限;4. 最佳实践建议数据最小化、敏感加密和合理过期。文章指出,即使
本研究旨在探讨运用Python编程语言,采取django开源模型,结合MySQL数据库作为后台数据的主要存储单元进行开发,基于MVC 架构提供使用界面,通过网络结构模式 B/S,借助WEB浏览器,通过分析旅游景点信息和特征,部署和实施一个友好、便捷、安全、高效的旅游人流量可视化系统,帮助用户了解旅游景点信息和人流量情况,以便更好地选择出行地。
这篇文章以学做菜为比喻,生动讲述了作者第一次编写Servlet的经历。从配置环境(备料)、编写代码(按菜谱操作)到调试运行(上菜),详细描述了开发过程中遇到的典型问题和解决方法。文章特别强调了Servlet的基本工作原理(点单流程)、线程安全注意事项,以及环境配置的关键点。通过PropertiesServlet实例,展示了Servlet开发的核心步骤和常见错误处理方式,最后指出Servlet作为J
类/接口角色核心职责请求处理器继承它来创建 Servlet,重写doGetdoPost等方法以定义业务逻辑。请求的抽象从中获取所有来自客户端的信息:参数、头、URL、Session 等。响应的抽象通过它构建返回给客户端的一切:状态、头、内容(HTML/JSON)。简单流程用户发起一个 HTTP 请求(例如,提交一个表单)。服务器(如 Tomcat)接收到请求,创建和对象。服务器调用对应的的serv
Hadoop 3.4.2和Hive 4.0.1环境下运行MapReduce任务时出现java.lang.VerifyError错误,原因是log4j组件冲突。错误显示LogEventAdapter类重写了final方法导致验证失败。解决方案是移除Hive安装目录下的冲突jar包:将log4j-1.2-api-*.jar和log4j-slf4j-impl-*.jar移动到备份目录,使系统回退到使用l
Hive UDF(User-Defined Function)允许用户扩展 HiveQL 功能。:开发后先用小数据集验证,再部署到生产环境。
本研究基于Python编程语言,利用数据分析和可视化技术,开发了一个淘宝订单数据分析及可视化系统。通过收集和清洗淘宝订单数据,我们运用Python中的数据分析库和可视化工具,对订单数据进行统计分析和图表化展示。通过这些工作,我们得到了对淘宝订单的深入洞察,发现了销售趋势、价格变动、用户购买行为等重要信息。
Rust 的内存安全特性通过所有权模型和借用检查器,可在编译时避免数据竞争、空指针和缓冲区溢出等常见问题。其零成本抽象设计确保高性能,适合网络编程中对低延迟和高吞吐的需求。操作符可简化错误传播,确保资源(如套接字)在作用域结束时自动释放,避免泄漏。启用 LTO(链接时优化)和调整代码生成参数提升性能。工具可观察系统调用行为,验证网络交互是否符合预期。,后者提供异步 I/O 支持以提升并发性能。共享
异步编程通过事件循环和协程机制,让单线程程序获得了接近多线程的并发能力。3 对于需要处理大量网络请求或实时数据流的应用,掌握asyncio已成为现代 Python 开发者的必备技能。从简单的爬虫到微服务架构,异步范式正重新定义高性能程序的实现方式。
本系统以实际运用为开发背景,通过系统管理员可以对所有的学生相关联的一些考试、课程等数据信息进行统一的管理,方便资料的保留。学生可以通过注册,然后登录到系统当中,对课程、考试以及学校通知这些信息进行查询管理。总的来说,系统使用flask这个框架,数据库采用目前流行的开源关系型数据库mysql,使用了目前流行的Python技术,让页面展现得更加的整齐漂亮。
本研究旨在基于Django框架开发一个《数据结构》课程网站,旨在为学生提供一个便捷的在线学习平台。该网站将包括课程内容展示、视频教学、习题练习、在线测验等功能模块,旨在帮助学生深入理解数据结构知识,提高学习效率。通过系统设计和开发,用户可以方便地浏览课程资料、观看教学视频,进行在线练习和测试。本研究将通过需求分析、系统设计和开发实践,确保网站的稳定性和用户体验。该《数据结构》课程网站的建立将为学生
对于敏感数据,建议使用。配合加密密钥增强安全性。
sql语句中使用row_number分析函数,分组(partition by)字段中有几十万空字符串,导致数据严重倾斜,报错。
个性化旅游推荐系统通过利用Hadoop、HTML、CSS等技术实现前端页面的美观和动态效果,符合用户审美观。后台主要采用Java编程语言、MySQL数据库和Ajax异步交互等技术,解决传统旅游推荐方式中的数据分析问题,提高推荐的准确性和效率。系统实现了基本功能,包括系统用户管理、景点信息展示与分类、通知公告发布等。本系统研究的背景、作用和意义在于提供一个能够根据用户兴趣和需求进行个性化推荐的旅游信
乡村爱心儿童帮扶平台的设计是基于Python技术、Mysql数据库、Apache服务器的方式设计,以ZendStudio和Dreamweaver为开发工具,在ZendStudio集成环境下调试并允许,并运用Photoshop技术美化网页,辅之以CSS技术。该系统实现了乡村爱心儿童帮扶平台的各种工作流程计算机管理化,其中包括首页、通知公告、新闻资讯、贫困地区等功能。
在探索DeepSeek这一强大的数据分析工具时,遵循一些最佳实践可以确保您获得最准确、最有价值的洞察。以下是一些关键的步骤和建议,帮助您充分利用DeepSeek的功能。根据您的具体需求和数据特性,选择最合适的模型。2. 数据质量:确保输入DeepSeek的数据是准确和完整的。通过实验不同的参数设置,您可以找到最适合您数据的配置,从而提高分析的准确性。定期监控您的模型性能,并根据需要进行调整。遵循这
想起第一次去公司就让我们手写分布式master和slave,刚开始是一个master对应多个slave,到后面多个master对应多个slave带数据备份,数据分段处理,任务下发各种功能,如果分布式理念用到安全,渗透等开发我们可以做什么,另一个大数据demo中我再说。大数据开发,在线%图书分析%系统开发,基于html,css,jquery,echart,python,django,hadoop,m
摘要:本文探讨了C++智能工厂生产调度系统的自动化测试策略,针对多生产线异构接口、实时性要求、复杂作业场景等挑战,提出了分层测试方案。通过单元测试、接口测试、仿真测试等方法验证系统功能,结合CI/CD实现持续集成,有效提升缺陷发现率和系统性能。实践表明,该策略使关键模块缺陷发现率提升35%,生产效率提升30%,为智能工厂的稳定运行提供了有力保障。
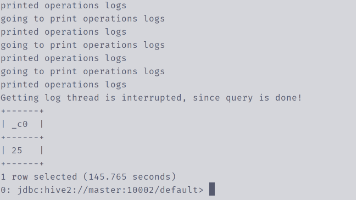
hive
——hive
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AMD开发者中国社区
AMD开发者中国社区


 MCP技术社区
MCP技术社区


 AI Agent技术社区
AI Agent技术社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 快递鸟社区
快递鸟社区
 人工智能6S服务平台
人工智能6S服务平台