登录社区云,与社区用户共同成长
邀请您加入社区
DeepSeek Resources: Unearthing the Potential of Deep Learning in Resource ManagementIn the rapidly evolving landscape of technology, DeepSeek Resources stands as a beacon of innovation, harnessing the
能源行业国产化应用:DeepSeek在国产服务器上的实时数据处理实践 摘要:随着能源行业数字化转型加速,实时数据处理成为智能化升级的关键环节。本文介绍了国产人工智能平台DeepSeek在鲲鹏服务器上的部署应用,详细阐述了其在能源实时数据处理中的架构设计、算法优化和性能突破。通过实际案例验证,该方案实现了毫秒级延迟的TB级数据处理能力,在设备预警、负荷预测等核心业务场景中取得显著成效,同时降低综合成
摘要: 本文探讨了将大型语言模型DeepSeek-7B部署到资源受限的边缘设备和嵌入式系统的挑战与解决方案。通过模型剪枝、量化(如INT8/FP16)、硬件适配及推理引擎优化(如ONNXRuntime、TensorRT),显著降低了模型的内存占用和计算需求。结合ARM NEON指令集优化和内存管理策略,实现了在嵌入式平台(如NVIDIA Jetson、ARM Cortex-A72)上的高效推理,延
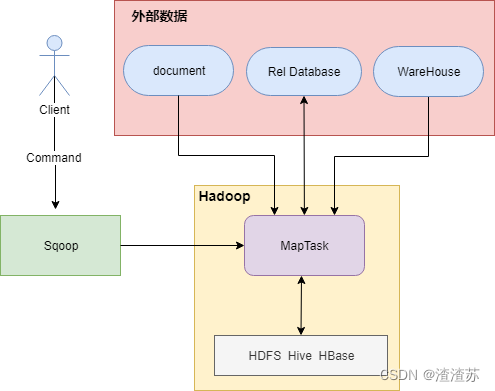
本文介绍了Sqoop的安装过程。Sqoop是用于关系型数据库与Hadoop生态间数据导入导出的工具,属于客户端组件,无需常驻服务进程。安装时需注意:1)建议在Hive之后安装;2)只需分配Client角色到目标主机;3)确保Hadoop/Hive环境及JDBC驱动配置正确。安装完成后通过sqoop version验证,状态显示"已安装"即为成功。Sqoop安装是后续HBase等组件的基础准备步骤。
配置JAVA_HOME,jdk8+
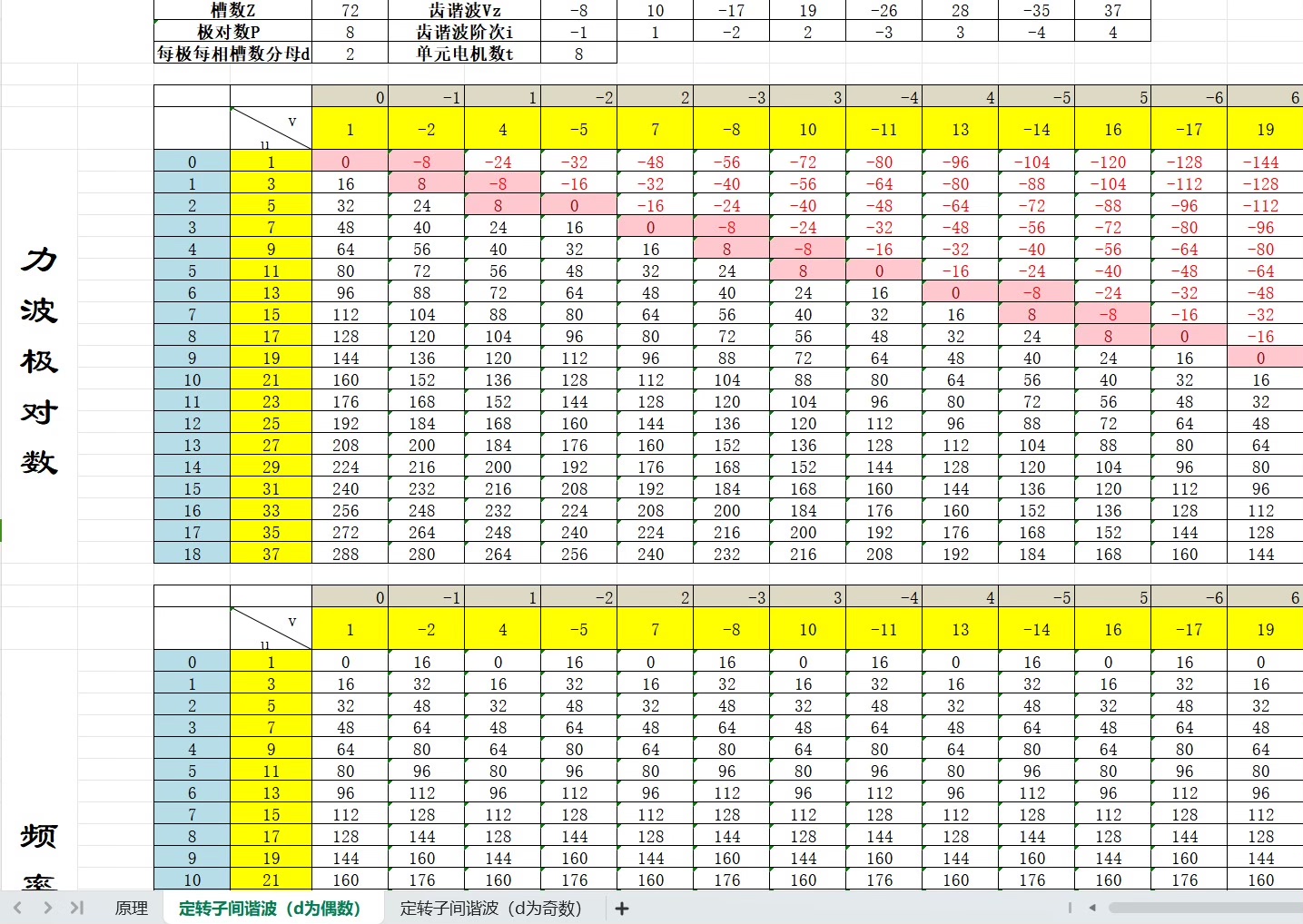
电磁力波阶次计算表,永磁同步电机径向电磁力波阶次数计算表。#永磁同步电机噪声分析。在永磁同步电机的研究与应用中,噪声问题一直备受关注。而径向电磁力波是导致永磁同步电机产生噪声的重要因素之一,对其阶次进行准确计算,是深入分析电机噪声来源和特性的关键步骤。今天咱们就来聊聊永磁同步电机径向电磁力波阶次数计算表以及背后的门道。
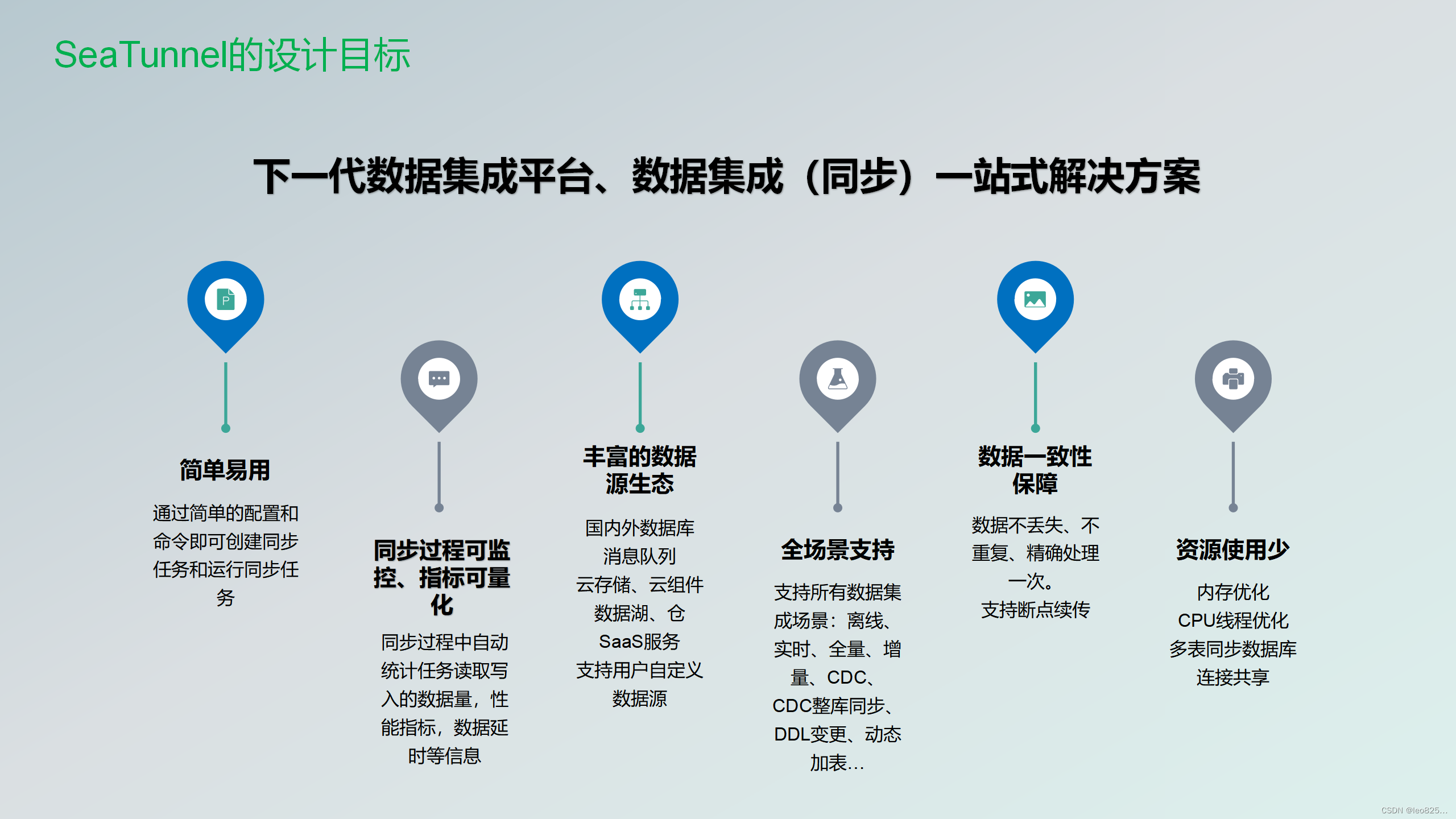
Apache SeaTunnel作为下一代数据集成平台。同时也是数据集成一站式的解决方案,有下面这么几个特点。丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。基于该API开发的Connector(Source、Transform、Sink)可以运行在很多不同的引擎上,例如目前支持的SeaTunnel Engine、Flink、Spark等
大家好,我是你们的老朋友。例如,在动力电池包外观检测工位上,系统可以实时监控每个电池包的外观检测流程,自动识别操作是否规范、产品是否放入正确区域。比如,在一次发动机装配过程中,工人漏涂了螺纹紧固剂,系统立刻发出警报,并显示错误细节,引导工人进行修正。总之,艾视维ROBOT的SOP防错AI智能体是一款非常值得推荐的软件,它能够帮助企业实现从“人管人”到“系统管人”的转变,大幅提升生产质量与效率。:许
无论是在哪个场景,它都能有效解决操作不规范、监控不到位、数据不结构、溯源不高效等问题。咱们都知道,制造业的痛点可不少。最后啊,我想说,技术改变生活,也改变着我们的工作方式。这就意味着,任何工艺偏差都能被第一时间捕捉,真正实现了从“人管人”到“系统管人”的转变。还有,这个系统能够提供简单且即时的视频数据,使生产管理者可以方便地获取任何异常时段的数据。其次,当系统检测到操作人员出现漏装、错序、动作错误
此外,当产品出现质量异常时,企业往往面临“谁操作的、什么时候操作的、哪里出了问题”等溯源难题,导致排查成本高昂。它通过实时管控、实时干预和实时数据化等功能,有效地解决了操作不规范、监控不到位、数据不结构、溯源不高效等问题。此外,系统的使用也需要一定的技术支持,企业需要配备相应的技术人员进行系统的维护和升级。特别是在高复杂度、高精度要求的工位,如发动机装配、螺纹紧固操作等,系统的应用效果更加显著。最
《Sqoop快速入门指南》Sqoop是Apache开源工具,专用于关系型数据库(如MySQL)与Hadoop(HDFS/Hive)间的数据传输。
是一款专为Hadoop与结构化数据存储(关系型数据库、数据仓库等)之间批量数据传输设计的开源工具。它的名字来源于“SQL to Hadoop”的缩写,顾名思义,它的核心使命就是架起关系型数据库与Hadoop生态之间的桥梁。Apache Sqoop作为大数据协同工具的重要成员,解决了结构化数据与Hadoop存储之间最普遍、最迫切的传输难题。尽管业界涌现出Apache SeaTunnel、DataX等
Sqoop导出是指将Hadoop分布式文件系统(HDFS)中的数据批量传输到关系型数据库(如MySQL、Oracle、PostgreSQL等)的过程。fill:#333;important;important;fill:none;color:#333;color:#333;important;fill:none;fill:#333;height:1em;关系型数据库Sqoop导出过程Hadoop生
-direct模式是Sqoop提供的一种高性能数据传输通道。它绕过JDBC,直接调用数据库自带的原生数据工具(如MySQL的mysqldump和、PostgreSQL的COPY命令)来完成数据的导入和导出。JDBC模式:Sqoop说"数据库的通用语言"Direct模式:Sqoop说"数据库的母语"问题答案什么是–direct?Sqoop的高性能模式,绕过JDBC直接调用数据库原生工具它如何工作?导
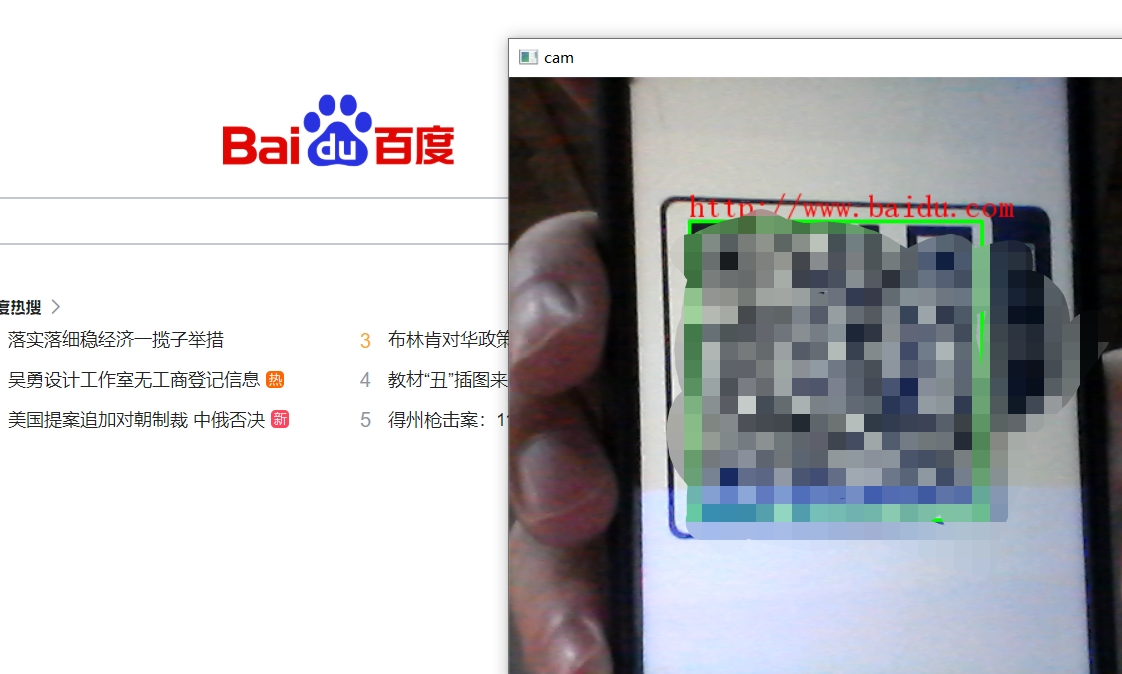
数字图像处理二维码识别python+opencv实现二维码实时识别特点:(1)可以实现普通二维码,条形码;(2)解决了opencv输出中文乱码的问题(3)增加网页自动跳转功能(4)实现二维码实时检测和识别代码保证原创、无错误、能正常运行(如果电脑环境配置没问题)送二维码识别完整说明报告,包括识别原理,识别流程,实验过程中一些细节的问题。在数字图像处理的领域中,二维码识别是一项非常实用且有趣的技术。
当需要从多个表中选择列时,使用--query-P \-m 4注意:在--query中直接指定需要的列,无需再使用--columns。基本语法:使用指定要导入的列列顺序--columns中列的顺序决定输出文件中的列顺序大小写敏感:列名必须与数据库中的定义一致配合过滤:可与--where结合实现条件导入并行支持:选择列的同时仍可通过--split-by实现并行最佳实践始终只选择需要的列,减少I/O和存
是Sqoop提供的一个参数,用于在导入数据之前,如果目标目录已存在,则先删除该目录。简单来说,它的作用就是:“让目标目录回到不存在的状态,然后再执行导入”。**幂等性(Idempotency)**是指:无论执行多少次操作,结果都是一样的。第一次运行:导入10万条数据第二次运行:如果数据没有变化,最终数据还是10万条,不会变成20万条第三次运行:结果依然不变问题答案是什么?在导入前删除已存在的目标目
错误原因如题:报错关键字:sqoop Opening field-encloser expected at position 0报错信息分析:sqoop做merge时期望在位置0时有列分隔符会出现各种位置,跟mysql字段有关,换行符导致数据放入了第二行,merge时报错解决方法:sqoop增加神奇的字段:--hive-drop-import-delims 指定导入时删除hive的...
最近在学习sqoop,我以前用过sqoop-1.4.4版本,最近想学习最新版sqoop-1.99.7,在网上找了安装教程,安装完后用#sqoop2-tool verify命令进行验证,结果报caused by java.lang.ClassNotFoundException:org.apache.hadoop.conf.Configuration这个错误,明显是sqoop没有找到
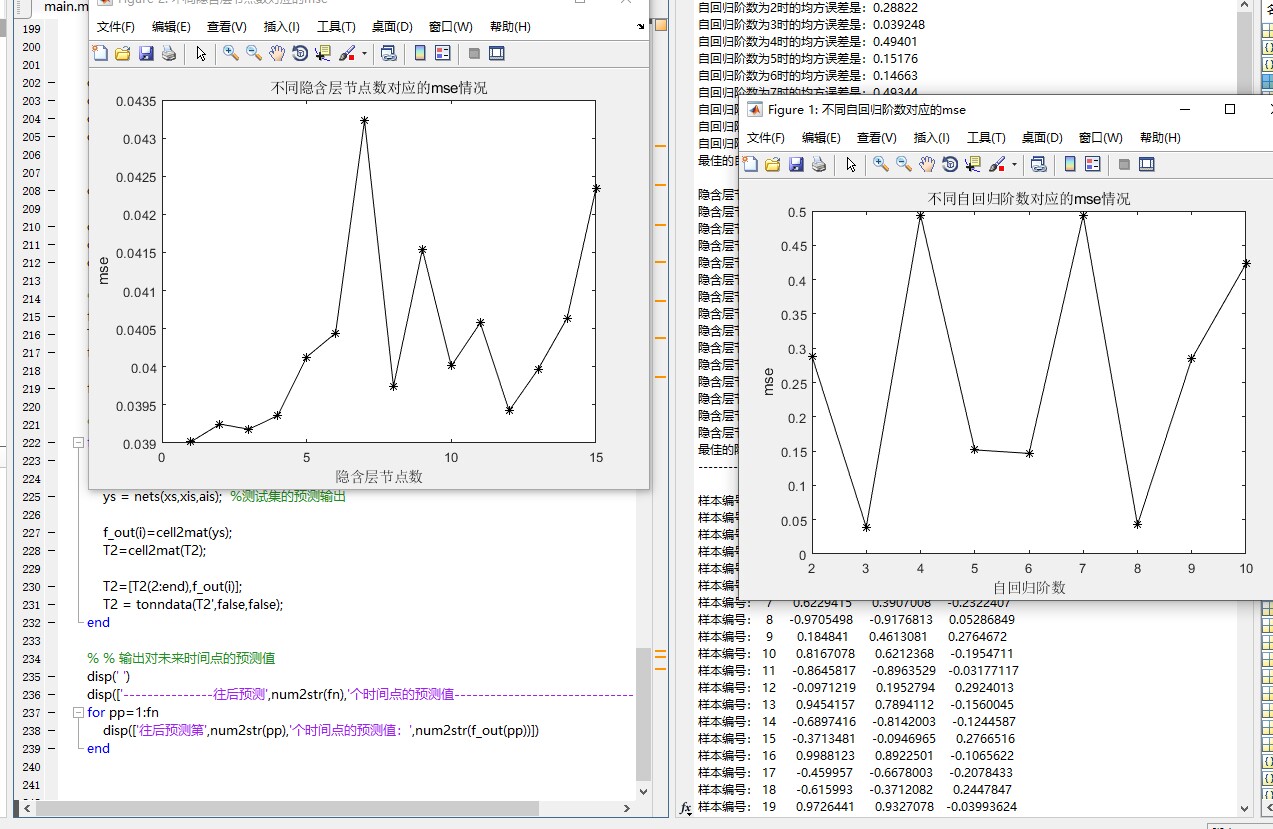
今天给大家分享一套开箱即用的代码,数据格式就用最常见的Excel表格,复制粘贴就能跑通。隐藏层用了10个神经元,这个数不是固定的,数据量大的话可以适当增加,但别贪多否则容易过拟合。实际跑出来的效果,如果数据周期性明显(比如用电负荷的日周期、周周期),预测曲线会和真实值贴合得比较紧。遇到过的一个坑是:当数据有突变点时,预测结果可能会"惯性滞后"。比如原始数据是[1,2,3,4,5],设置滞后阶数为2
万物皆有裂痕,那是光照进来的地方。—— 莱昂纳德・科恩
在企业级数据仓库建设中,增量数据同步是ETL流程中的核心环节。如何利用Sqoop工具实现关系型数据库到Hive的高效增量数据导入,掌握增量同步的各种模式、Sqoop调优技巧以及企业级解决方案,构建可靠的数据管道。
一、项目简介。
准备工作:sqoop安装包:准备各种数据库的驱动包:开始安装:1.将安装包解压到指定的目录下面2.重命名解压后的安装文件3.配置环境变量4.设置配置文件生效5. 配置sqoop的配置文件6.将数据库的驱动包添加到sqoop安装目录下面的lib文件夹中7.测试是否安装成功
这种方法具有高效、灵活的特点,可以替代传统的数据迁移工具如 datax 和 sqoop。同时,我们还可以根据实际需求进行扩展和优化,例如处理大规模数据、进行数据转换和清洗等操作。希望本文对你在大数据处理中的数据迁移工作有所帮助。在大数据处理中,经常需要在不同的数据库之间进行数据的导入导出操作。本文将介绍如何使用 Python 中的 Spark 框架实现将 Hive 数据导入到 MySQL 以及从
项目目标是构建一个大数据分析系统,包含以下核心模块:1、数据爬取:通过request请求获取猎聘网的就业数据。2、数据存储和分析:使用 Hive 进行数据存储和分析。3、数据迁移:使用sqoop将hive数据导入mysql。4、后端服务:使用 Flask 搭建数据接口,将分析结果提供给前端。5、数据可视化:使用 ECharts 制作大屏展示,实现数据的图形化呈现
sqoop:错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster(已解决)
INSERT INTO TABLE top_cities_high_windSELECTcity,COUNT(*) AS high_wind_days_countFROMetl_weather_dataWHERECAST(wind_speed AS INT) >= 3GROUP BYcityORDER BYhigh_wind_days_count DESCLIMIT 10;sqoop export
总之,设计与实现公有云等保合规安全解决方案需要充分理解组织的合规要求,建立安全基础设施,制定安全策略,并与合规云服务提供商紧密合作。只有这样,企业才能在使用公有云的同时,确保数据的安全和合规性。未来,我们可以期待更强大的云安全技术和工具的出现,以满足组织对数据安全和合规性的不断提高的需求。在公有云上构建安全基础设施,包括身份认证与访问控制、网络隔离、数据加密、防火墙和入侵检测系统等,以确保数据的安
1-1.用$hadoop job -list查看进程,当时本人遇到已经是011了,初始是001.1.如果之前可以运行,大概率排除配置问题,先考虑是否进程过多一直在排队,($代表是命令)1-2.用$hadoop job -kill杀掉进程,再运行试一下。1-3.如果还不行就再重启一次,大概率就解决了。
sqoop从mysql5.7导出到hbase2.2
sqoon安装教程
java.net.ConnectException: 拒绝连接; For more details see:http://wiki.apache.org/hadoop/ConnectionRefu
Sqoop是一个用于Hadoop和结构化数据存储(如关系型数据库)之间进行高效传输大批量数据的工具。它包括以下两个方面:常见数据库开源工具:Sqoop的核心设计思想是利用MapReduce加快数据传输速度。也就是说Sqoop的导入和导出功能是通过基于Map Task(只有map)的MapReduce作业实现的。...
解决了个别数据并非分隔符引起的错位问题,简单介绍了sqoop的三种用法。
kettle 脚本批量替换数据库连接配置
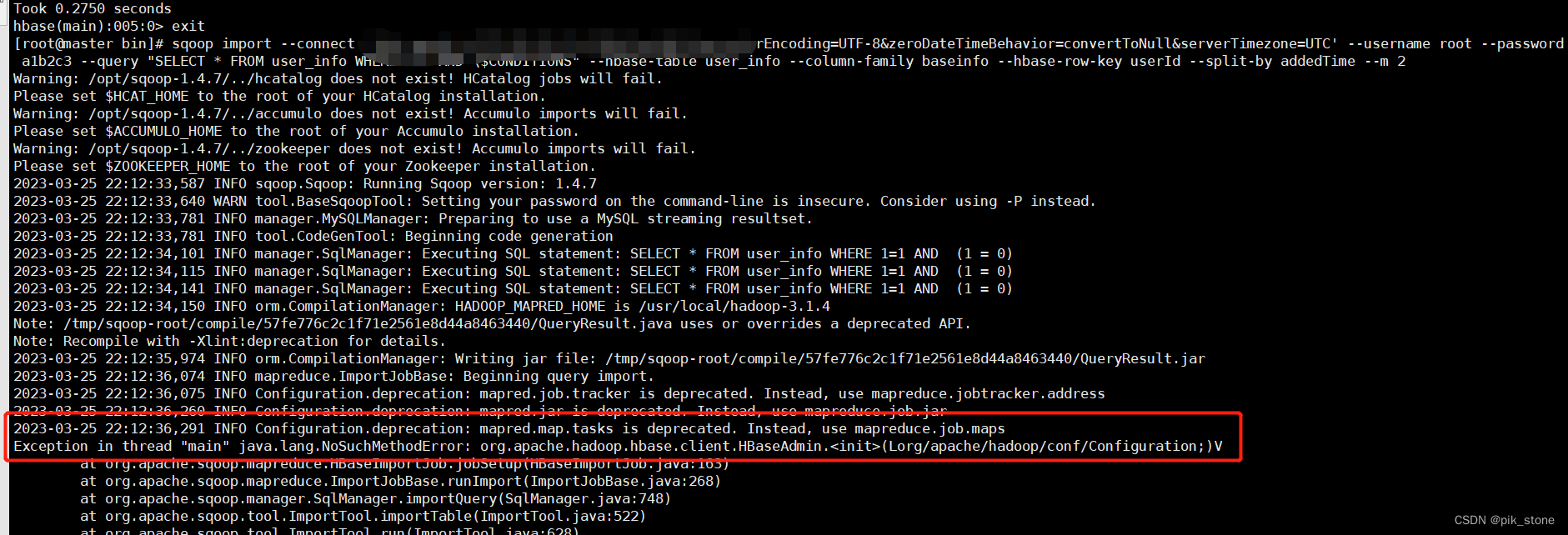
项目场景:sqoop从mysql到hive的问题hadoop解决集群总资源为0的情况问题描述在使用sqoop将数据从mysql导入到hive当中的时候,出现了一个问题bin/sqoop import --connect jdbc:mysql://master01:3306/demo_test?useSSL=false--username root --password xxxx --target-
1.从Oracle抽数到impala#!/bin/shsource /etc/profilesource ~/.bash_profilesqoop import --connect jdbc:mysql://ip:3306/数据库名称 \--username 用户名称 --password 密码 --table '表名'\--columns 'columns1,colums2,colums3' \
遇到的问题:21/08/20 16:29:40 INFO hive.HiveImport: Loading uploaded data into HiveException in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hive/shims/ShimLoaderat org.apache.hadoop.hive
kettle8.2百度网盘资源:链接:https://pan.baidu.com/s/1ibCPt8XLpaCGIiyiizpLWA提取码:4466欢迎使用Markdown编辑器你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。新的改变我们对Markdown编辑器进行了一些功
Sqoop安装好之后运行报错NoClassDefFoundError: org/apache/hadoop/mapreduce/InputFormat如下:21/01/27 08:25:49 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/002e434d1bd3a0780e4d1748ed2511bd/
sqoop
——sqoop
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵


 CSDN-OPC开发者社区
CSDN-OPC开发者社区


 AtomGit开源社区
AtomGit开源社区


 腾讯云开发者社区
腾讯云开发者社区