- @qq_33440910
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提供OpenClaw(小龙虾)软件的彻底卸载教程,覆盖Windows、Mac和Linux三大平台。针对该软件卸载后易残留后台服务、配置文件和API密钥等安全隐患,教程详细指导用户完成:1)卸载前准备(停止服务/备份数据);2)分平台卸载步骤(官方一键卸载和手动方案);3)关键残留清理(删除历史目录/轮换API密钥);4)常见问题排查。特别强调安全收尾操作,包括撤销第三方授权和重启电脑,确保无隐
摘要:OpenClaw是一款开源本地部署的AI智能体框架,专为科研人员设计。它能自动化处理文献检索、数据整理、代码运行等科研任务,支持Windows/Mac/Linux系统。部署只需三步:1)准备Python/Git环境;2)分系统安装;3)配置API密钥。核心优势包括数据本地存储安全、全自动化流程、丰富科研技能库和开源免费特性。安装时需注意系统权限和API密钥有效性,成功部署后可通过控制面板调用
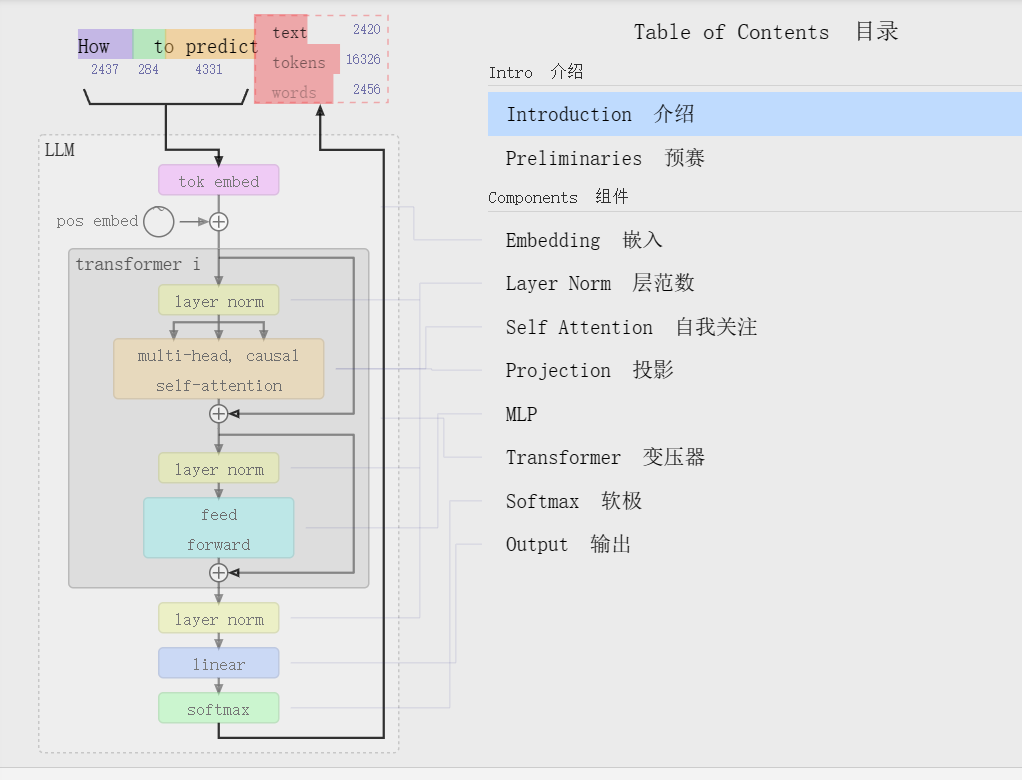
摘要: FFN层(前馈神经网络)是Transformer的核心模块,采用“升维→激活→降维”结构(如512→2048→512),通过GELU等激活函数引入非线性。其逐位置独立处理特性与注意力层互补:注意力层负责全局关联,FFN层负责局部精修。典型实现包含两层全连接和Dropout,现代变体包括SwiGLU激活和MoE稀疏化。代码示例展示了标准FFN层及在Transformer块中的调用流程,遵循“
最后申请,等待大概一到两周,正常情况下,你的邮箱就会收到认证通过的邮件。如果失败,请检查一下是不是填写有问题。再试一试,或者去学院开一份英文的在读证明(这个网上找模板),盖上学院公章。按照要求填写,但是如果遇到这个提示,恭喜你,你的学校获得了美国商务部认证。按照要求填写,上传学生证照片,以及学信网在线报告验证码。遇到这个不要慌,我们点官方文件,进入pycharm官网。

*BERT(Bidirectional Encoder Representations from Transformers)**是一种预训练的自然语言处理模型,由Google于2018年提出。BERT通过在大规模文本语料上进行预训练,学习了深层次的语言表示,然后可以通过微调用于各种下游任务,包括文本分类。文本分类是一个常见的自然语言处理任务,它涉及将文本分为不同的类别或标签。

不同的损失函数适用于不同的任务,回归任务中通常使用均方误差(MSE)和绝对误差(MAE),分类任务中使用交叉熵损失,物体检测和分割中使用IoU和Dice损失,而生成模型中使用对抗损失和重构损失。根据具体任务的特点选择合适的损失函数对于模型的性能有很大影响。

nano-gpt欢迎来到 GPT 大型语言模型的演练!在这里,我们将探索只有 85,000 个参数的 nano-gpt 模型。它的目标很简单:取六个字母的序列:CBABBC并按字母顺序排序,即“ABBBCC”。tokenvocabulary我们将这些字母中的每一个称为标记,模型的不同标记集构成了它的词汇表:token 令牌ABCindex 索引012在此表中,每个令牌都分配了一个数字,即其令牌索引
联想 机器学习算法面经
mpu.broadcast_data(keys, data, datatype) 是一个函数调用,它来自于 SwissArmyTransformer 库中的 mpu 模块。模型需要的是一种数值表示,通常是词向量,这样才能进行数学运算。因此,原始的字符串数据需要被转换为词向量。中的数据是字符串,因为这是原始的输入数据。然后,这些数据被转换为词向量,以便可以被模型处理。模型接收的输入是词向量,而不是原
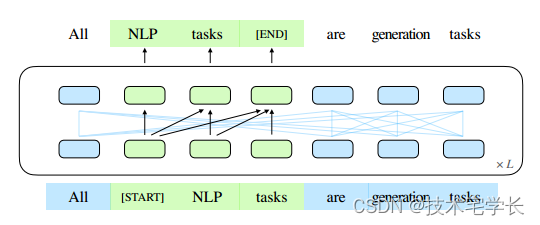
CHATGML 。通过改变空格的数量和长度,可以对不同类型的任务进行GLM的预训练。在NLU、条件生成和无条件生成的广泛任务中,在相同模型大小和数据的情况下,GLM优于BERT、T5和GPT,并在单个BERTLarge参数为1.25倍的预训练模型上取得了最佳性能,证明了其对不同下游任务的泛化能力1。2 .T5 (Raffel等人,2020年)通过编码器-解码器模型统一了NLU和条件生成,但需要更多