




- @2401_84205765
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
微软开源 GraphRAG 后,热度越来越高,目前 GraphRAG 只支持 OpenAI 的闭源大模型,导致部署后使用范围大大受限,本文通过 GraphRAG 源码的修改,来支持更广泛的 Embedding 模型和开源大模型,从而使得 GraphRAG 的更容易上手使用。需要 Python 3.10-3.12 环境。安装完整后,需要创建一个文件夹,用来存储你的知识数据,目前 GraphRAG 只
开发人员转行网络安全具有独特优势,尤其在PHP代码审计领域。本文介绍了开发背景带来的三大优势:熟悉代码逻辑、掌握语法特性和了解开发习惯。重点讲解了PHP代码审计的核心方法——"找入口→看处理→判风险"三步法,并详细分析了SQL注入漏洞的审计流程。通过实战案例演示了如何从$_GET参数入手,发现未过滤用户输入导致的SQL注入漏洞。文章为开发者转型安全领域提供了实用指导,强调将开发

计算机专业学习规划与就业指南 摘要:本文为计算机专业学生提供大学四年系统学习规划和就业指导。学习方面,强调掌握数据结构、计算机网络、操作系统、数据库等核心课程,并按年级分阶段学习编程语言、开发工具及框架。就业准备部分,详细解析春招秋招区别、企业分类及招聘网站,提供简历撰写技巧和面试自我介绍模板。建议根据个人情况选择考研或就业,并保持日常刷题习惯。最后指出网络安全行业作为新兴领域的发展前景和薪资优势

人工智能(AI)作为科技领域的一颗璀璨明珠,正以惊人的速度改变着我们的生活。对于许多初学者而言,如何踏入这个充满未知的领域呢。但其实,只要你拥有一颗探索的心,一切都将变得轻而易举。下面,我将为大家分享一些关于如何学习人工智能的有效建议,助你轻松驾驭这项技术。

这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同

CTF竞赛已成为大学生进入网络安全行业的重要敲门砖。数据显示,头部企业安全岗录用率对有CTF获奖经历的候选人高出47%,985院校网安专业对其认可度甚至超过普通实习经历。CTF比赛不仅能培养实战技术能力,如漏洞挖掘、逆向分析等企业所需的核心技能,还提供行业背书和人脉资源。参赛者需掌握计算机网络、操作系统等基础知识,并选择适合的技术方向进行专项训练。通过系统准备,零基础学生可在6-12个月内具备参赛

本文可以学习到以下内容:使用 pandas 中的 read_sql 读取 sqlite 中的数据获取指定的日期的周一和周日使用 groupby+agg 方法统计每周的商品总销量和总退单量使用 value_counts 方法统计商品的退单数据使用 merge 方法合并数据。
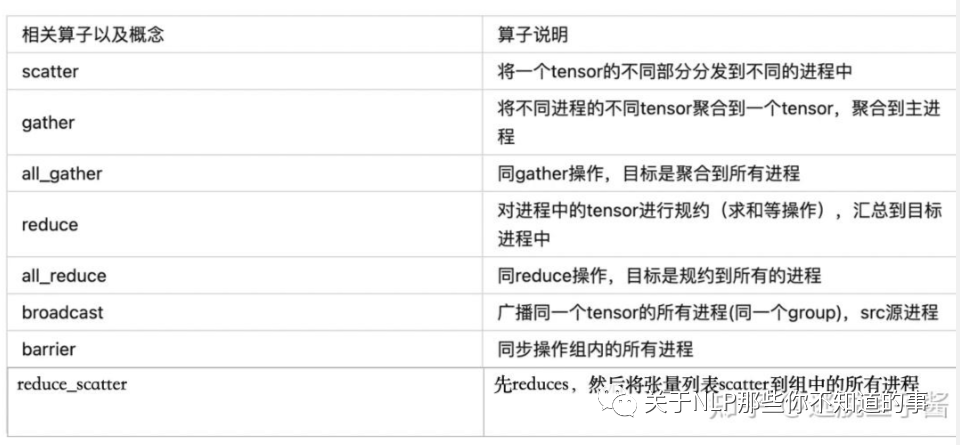
优化器存储一个float32的模型副本,则会消耗4X的显存,同时存储两个状态参数,分别消耗4X和4X的显存,则总共需要16X的显存。但是随着模型的训练,梯度值太小小,超出float16表示的精度,导致权重都不再更新,模型难以收敛。因此,任意给定的GPU都会有两部分的通信,一个是与包含所有相同层的GPU(数据并行),另一个与不同层的GPU(流水线并行)。对于模型计算的中间结果(activation,
本研究成果推出了 RepoAgent 开源框架,为项目级别的代码库生成细粒度的代码文档,并实现了代码文档构建和更新维护的自动化。RepoAgent 有望大幅减轻软件开发人员的文档维护负担,提高代码库的可维护性和可理解性,带来新的软件开发流程范式。。

2012年以后的深度学习热潮:2012年,AlexNet横空出世,以卷积神经网络(CNN)为代表的深度学习模型在计算机视觉任务中取得了巨大突破,吸引了越来越多的计算机科学家和工程师投入深度学习研究和应用。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。建议普通人掌握到L4级别即可。作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能
