




- @yorkhunter
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
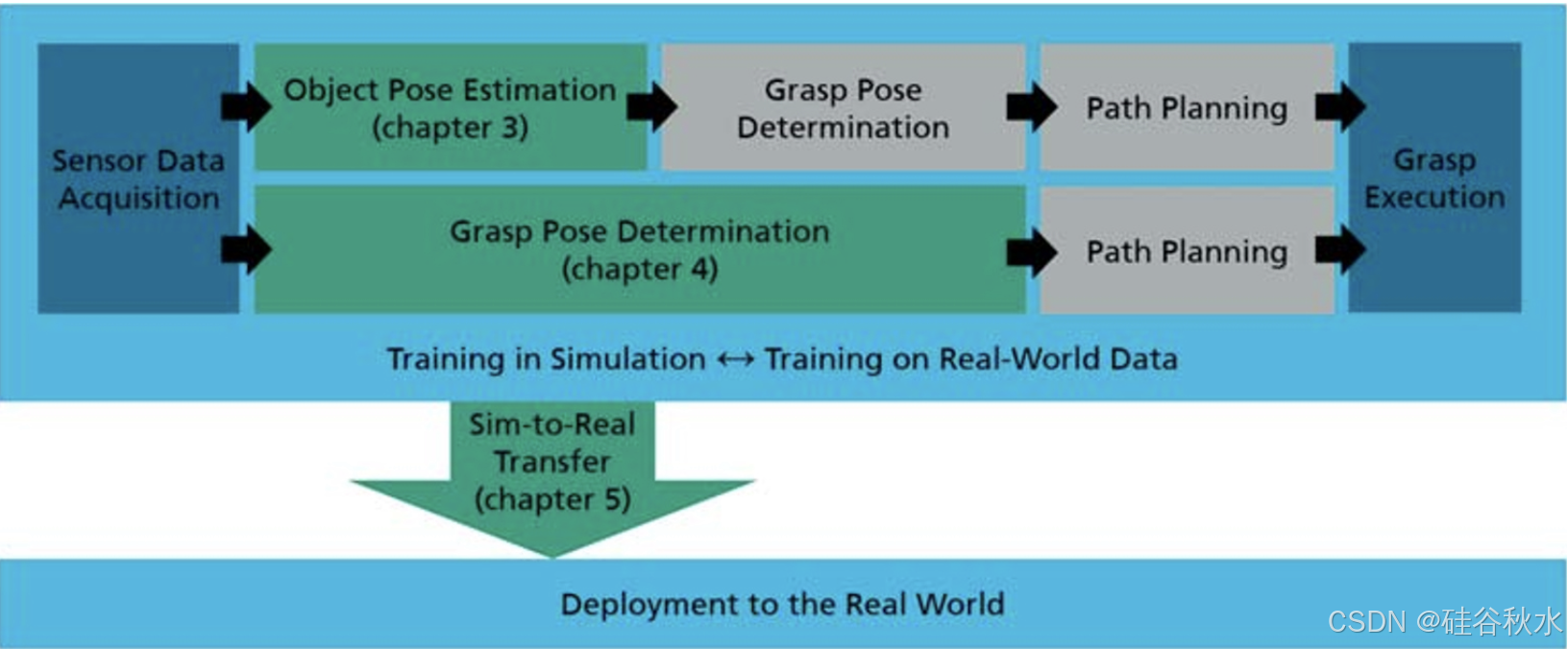
20年9月来自德国斯图加特大学和Fraunhofer IPA的论文“A Survey on Learning-Based Robotic Grasping”。本综述全面概述基于视觉的机器人抓取和操作的机器学习方法。提供当前的趋势和发展以及方法分类的各种标准。“无模型”方法因其对新目标的泛化能力而具有吸引力,但大多局限于自上而下的抓取,并且不允许精确的目标放置,这会限制其适用性。相反,“基于模型”的
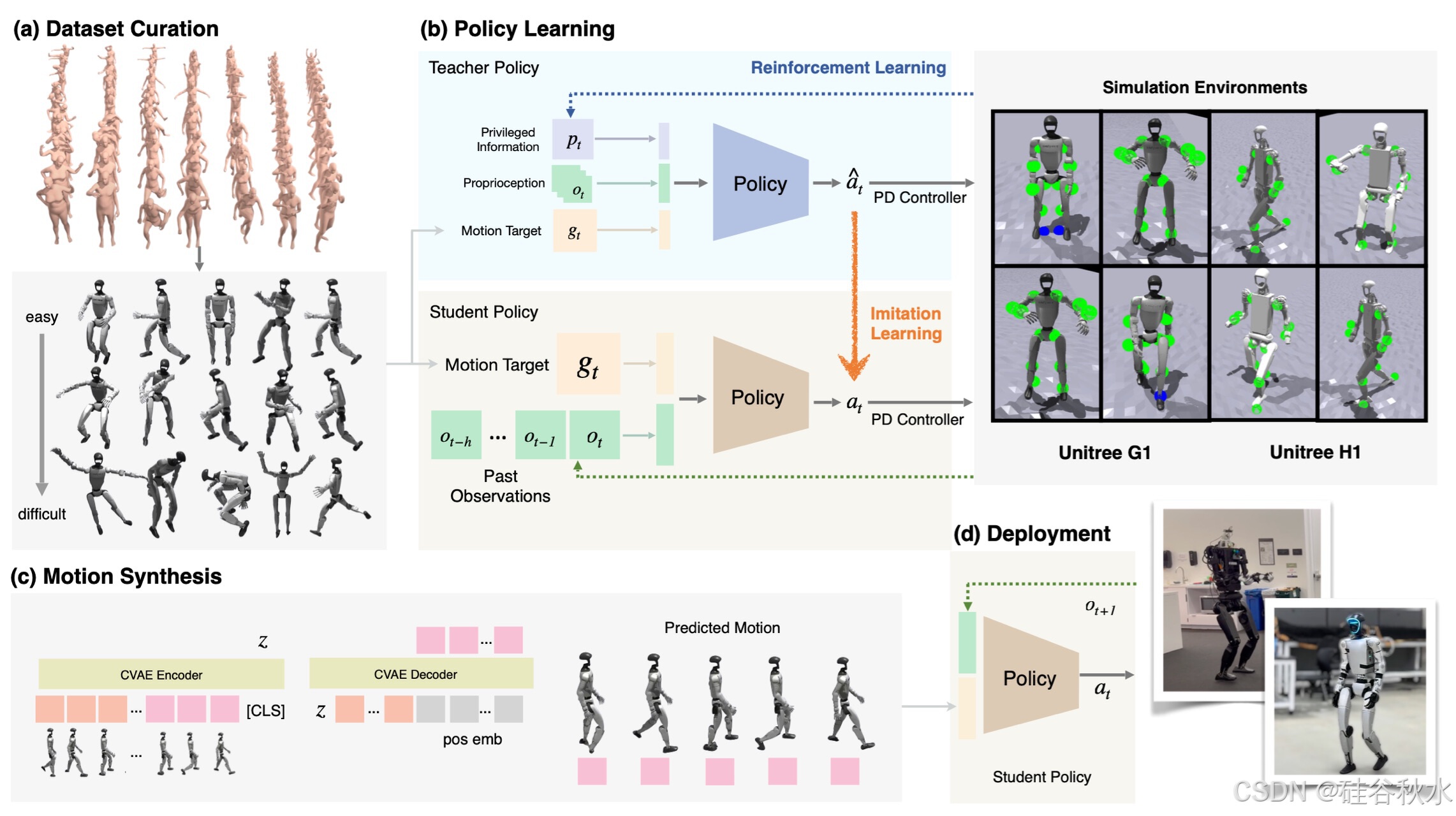
24年12月来自 UCSD、UCB、MIT 和 Nvidia的论文“ExBody2: Advanced Expressive Humanoid Whole-Body Control”。本文使现实世界的人形机器人能够在像人类一样做出富有表现的动作同时保持稳定性。提出高级富有表现的全身控制 (ExBody2),一个泛化的全身跟踪框架,可以接受任何参考动作输入并控制人形机器人模仿动作。该模型在模拟中使用
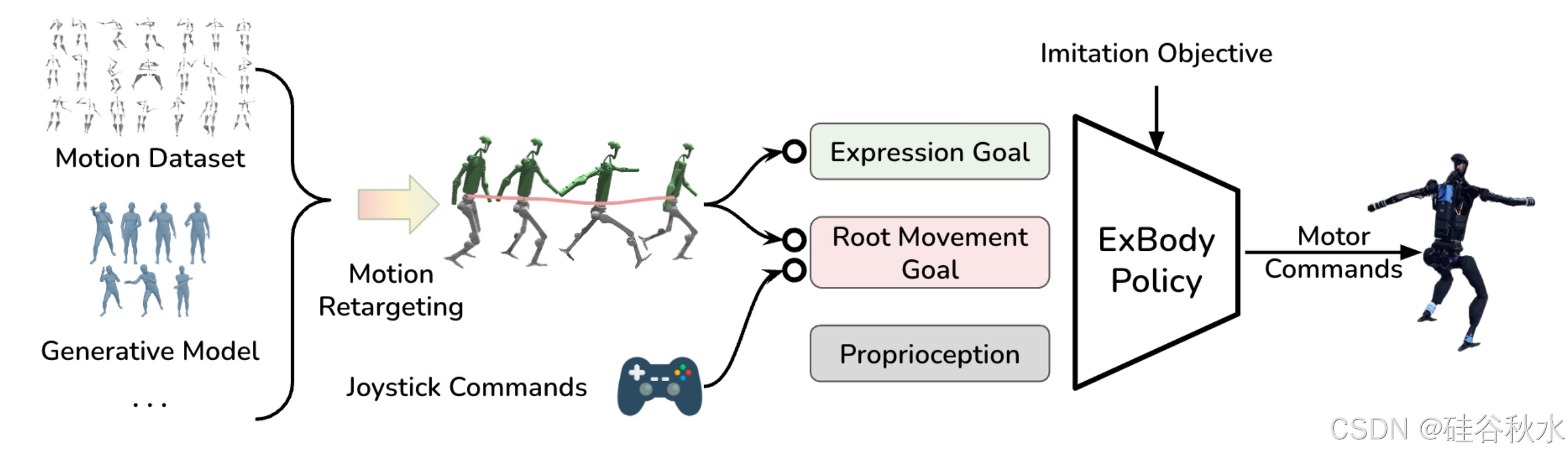
24年3月来自UCSD的论文“Expressive Whole-Body Control for Humanoid Robots”。能否使人形机器人在现实世界中做出丰富多样、富有表现的动作?在人形机器人上学习全身控制策略,尽可能真实地模仿人类动作。为了训练这样的策略,在强化学习框架中利用图形学社区的大规模人体动作捕捉数据。然而,由于自由度和人体能力的差距很大,直接使用动作捕捉数据集进行模仿学习,对
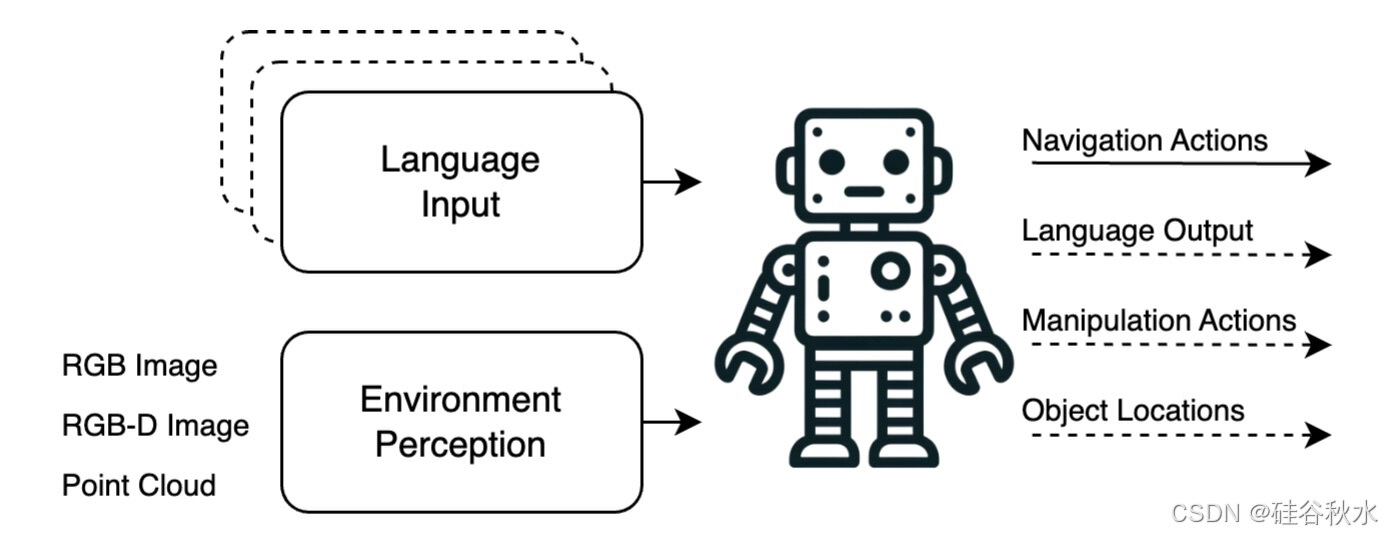
24年2月来自曲阜师范、华东师大和哈工大的论文“Vision-Language Navigation with Embodied Intelligence: A Survey”。作为人工智能领域的长期愿景,具身智能的核心目标是提升智体与环境的感知、理解和交互能力。视觉-语言导航(VLN)作为实现具身智能的重要研究路径,致力于探索智体如何利用自然语言与人进行有效沟通,接收并理解指令,并最终依靠视觉信
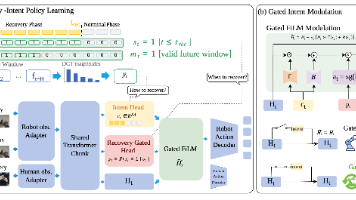
26年7月来自复旦、上海多模态具身智能重点实验室和深朴智能的论文“EgoRecovery: Acquiring Failure Recovery Ability Through Human Recovery Demonstration”。稳健的具身机器人若要在非结构化且充满噪声的现实环境中可靠运行,必须具备从故障中恢复并重试任务的能力。实现这一能力需要利用包含恢复行为的数据来训练策略。然而,通
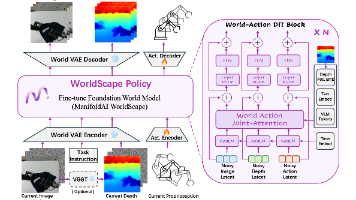
26年2月来自流形空间公司的论文"WorldScape Policy: Generalizable Robotic Learning via a Foundation World Model"。世界模型为机器人学习提供了一条极具前景的途径,它能够直接在高维视觉空间中进行预测和规划。然而,与在语言空间中进行推理但通常难以应对分布外视觉变化的视觉-语言-动作(VLA)策略不同,将强大的生成式世界模型转
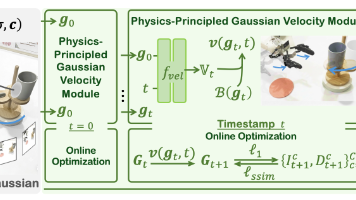
26年7月来自香港理工和星尘智能的论文“PhysMani: Physics-principled 3D World Model for Dynamic Object Manipulation”。在非结构化三维环境中操控快速且动态移动的目标,对于具身智能(Embodied AI)而言仍是一项挑战。现有的视觉-语言-动作(VLA)模型及世界模型,往往难以准确表征三维几何结构或进行符合物理规律的预测。为
26年7月来自阿里高德视觉实验室的论文“ABot-AgentOS: A General Robotic Agent OS with Lifelong Multi-modal Memory”。尽管近期的视觉-语言模型(VLM)和视觉-语言-动作模型(VLA)提升了机器人的感知与动作预测能力,但长程具身智体仍需一个通用的运行时层,以支持推理、记忆、工具使用、验证及跨形态执行等功能。提出 ABot-Ag
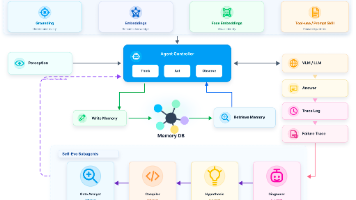
26年7月来自阿里高德视觉实验室的论文“ABot-AgentOS: A General Robotic Agent OS with Lifelong Multi-modal Memory”。尽管近期的视觉-语言模型(VLM)和视觉-语言-动作模型(VLA)提升了机器人的感知与动作预测能力,但长程具身智体仍需一个通用的运行时层,以支持推理、记忆、工具使用、验证及跨形态执行等功能。提出 ABot-Ag
26年7月来自阿里达摩院和湖畔实验室的论文“RynnBrain 1.1: Towards More Capable and Generalizable Embodied Foundation Model”。RynnBrain 1.1,是一系列涵盖 2B、9B 及 122B-A10B 规模的具身基础模型。RynnBrain 1.1 采用统一的时空与物理基础(physically grounded)框
