
写文章




- @qq_46454669
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Ubuntu下cuda、cudnn、tensorrt安装及完成推理加速,并使用psmnet和yolov8进行验证
WSL2急速搭建CUDA体验环境_wsl2 cuda-CSDN博客

更改docker镜像下载地址
使用指令查看本机的docker镜像下载地址为由于本机的var文件空间不足,因此,想更改他的存储地址,如下。

windows下基于vscode的ssh服务远程连接ubuntu服务器
首先,安装ssh服务安装后,打开ssh服务如果显示有sshd就说明成功了。判断是否成功打开同时也可以通过如下方式确保ssh服务正在运行。

使用docker配置Swarm-SLAM
swarm-slam在docker下的环境配置
在vscode下将ipynb文件转成pdf的方法
正常情况下,可以在vscode的ipynb界面点击上面的三个点,里面有export,可以选择直接输出html和pdf,但是需要latex,由于按扎u安装麻烦,所以我换了一种方法。

yolov7-3d算法原理
YOLOv 7 -3D算法应用于路边单摄像机三维目标检测。该方法利用二维边界框、投影角点和相对于二维边界框中心的偏移量等信息来辅助检测3D对象边界框,提高了三维物体边界框检测的准确性.此外,引入了5层特征金字塔网络(FPN)结构和多尺度空间注意机制,提高了不同尺度目标的特征显著性,从而提高了网络的检测精度。实验结果表明,该算法在Rope 3D数据集上的检测准确率明显提高,同时计算复杂度降低了60%

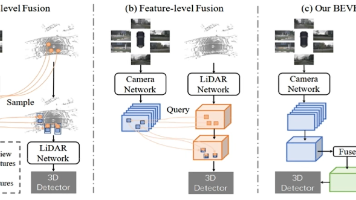
3D感知多模态(图像、雷达感知)
BEV是一个俯视空间,Former做的就是Transformer,这里指的就是使用transformer去做BEV的图像处理,完成后续检测目标。
使用docker配置Swarm-SLAM
swarm-slam在docker下的环境配置