登录社区云,与社区用户共同成长
邀请您加入社区
PXE(Preboot eXecution Environment,预启动执行环境)是由 Intel 公司开发的一种网络引导技术。它允许计算机通过网络从远程服务器下载并启动操作系统镜像,而无需依赖本地存储设备(如硬盘、U盘或光驱)。核心思想:将启动过程分为两个阶段。第一阶段由网卡上的 ROM 芯片(或 UEFI 固件)中的 PXE 客户端完成,它通过 DHCP/TFTP 协议获取初始引导文件;第二
本文介绍了Linux系统的起源与发展、学习价值、开源精神及主要发行版。Linux由Linus Torvalds于1991年基于Minix开发,继承了Unix的稳定性与开源特性,广泛应用于服务器和超级计算机领域。学习Linux主要因其高性能、低风险、低成本等优势,而非单纯因为开源。常见的Linux发行版包括企业级的Red Hat、免费的CentOS、面向开发者的Fedora、稳定的Debian、用户
GRUB2是Linux系统最常用的引导加载程序(Boot Loader)。它的核心职责:允许用户选择启动哪个操作系统或内核版本向内核传递启动参数(如调整运行级别、启用调试模式)提供救援模式入口单用户模式是一种维护模式,用于:重置root密码(忘记root密码时)修复文件系统错误排查启动故障移除损坏的软件包Systemd 是 Linux 系统的初始化系统(init system)和服务管理器,PID
实现一个情绪追踪日记应用,用户每天可以选择心情 emoji 并记录文字内容,支持历史查看、按心情筛选、心情统计和删除操作。
ubuntu 强制关闭卡死的pycharm
本来想在闲鱼买个二手显示器的,但是租的房子桌子太小放不下,就想试试用笔记本电脑远程到tx2上来控制,过程中踩了大部分坑,花了半天时间,现在晚上来复盘一下,加深一下记忆。**1.使用ssh工具远程tx2**这里将tx2网口连到路由器上,在路由器管理界面能看到当前分配的IP地址,使用工具Putty进行连接上试了一下,1个epoch需要6个小时,跑完100 epoch大约100*6/24=25天。瞬间放弃单机多卡,将目光放在了多机多卡训练,特撰文记录这段时间的工作,方便以后查询。一、准备工作因为之前配置单机的深度
使用Livox Viewer标定三个雷达外参,使用Opencalib标定雷达和相机的外参
显示类似 WiFi名称.nmconnection 的文件。这样就可以保存配置好的wifi,下次开机就会自动连接。好我们设置的WIFI后。
本文是一篇操作系统入门指南,用通俗易懂的方式讲解了操作系统的核心概念。文章首先解释了操作系统的本质是管理计算机硬件资源(CPU、内存、硬盘等),为程序提供安全稳定的运行环境。然后系统性地介绍了进程与线程、CPU调度、内存管理、文件系统等关键知识点,包括:进程状态转换、并发与并行的区别、上下文切换、虚拟内存原理、文件存储机制等。最后强调了操作系统各模块的协同工作关系,并总结了操作系统的四大核心任务:
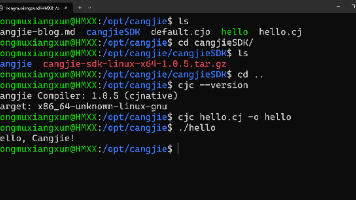
本文记录了在Linux系统上从零安装仓颉(Cangjie)编程语言SDK的完整过程。首先通过Git仓库获取SDK文件,解决了Git LFS下载超时问题,采用curl断点续传方式完成大文件下载。解压后配置环境变量,确保编译器路径和运行时库生效。最后编写并运行了第一个"hello.cj"程序验证安装成功。文章详细记录了安装过程中遇到的网络问题和权限问题,并提供了相应的解决方案,为开发者尝试仓颉语言提供
/isaaclab.sh -p scripts/demos/h1_locomotion.py第一次启动需要等待较长时间,后续再启动速度很快。cd /path/to/IsaacLab# 应已 git clone --branch v2.1.0。
本文在学习期间所著,如有侵权,小编会直接删除。
本文记录了将Qwen2.5-VL视觉语言模型接入ROS2机器人系统的实践过程。作者在WSL2 Ubuntu 24.04环境下,基于Unitree Go2四足机器人平台,整合ROS2 Jazzy、Gazebo Harmonic仿真环境和Qwen2.5-VL-3B模型,构建了完整的视觉感知系统。文章详细介绍了Unitree ROS2环境的配置步骤(包括解决WSL2时钟同步问题和网卡设置),以及创建VL
本文介绍了ROS1与ROS2的核心区别、Ubuntu系统安装步骤及ROS2环境配置方法。首先对比了ROS1(基于Master节点)和ROS2(采用DDS通信机制)在架构、API和编译系统上的差异。接着详细图解了Ubuntu 22.04在VMware中的离线安装流程,重点解决了网络安装报错问题。最后通过fishros一键脚本完成ROS2(Humble版本)的安装,并展示了小海龟示例程序的运行验证。整
可能写的有点粗糙,但是我搞通了,有不懂的可以问我,懒得再更新了
YOLOv5 一键安装器,多系统下快速部署 CPU/GPU 训练环境
首次运行时,模型会自动从HuggingFace下载,需要稳定的网络连接。确保服务器能够访问外网,特别是HuggingFace模型仓库。命令向容器的 8000 端口发送一个聊天补全请求。字段包含了模型生成的文本内容。:你将收到一个 JSON 格式的响应,其中。安装完成后需要重启系统以加载新的驱动。编辑Docker配置文件。安装完成后,可以使用。
使用b站up主 @人工大黑 给的链接。2.购买deepseek-v4(主要是因为便宜。1.安装claude code。买完后复制好给的api。
重启电脑,在启动过程中不断点回车(不同电脑不一样),进入BIOS,在BIOS中启用“Boot Menu”或在Security栏中关闭Secure Boot,而后在Boot栏中的启动顺序设置中,把USB启动的优先级设为最高。进入ubuntu安装程序。
1️⃣ 克隆仓库2️⃣ 创建 Conda 环境3️⃣安装 PyTorch3D已经安装过Pytorch的跳过此步骤(此行代码是安装Pytorch)go to 直接从这下面开始看:方式 A:在线安装(可能超时)(我因为网络问题连接失败,采用了方式B)方式B:使用离线 ZIP 安装(推荐国内网络)1.从 GitHub 下载4️⃣ 安装其他依赖5️⃣ 编译 FoundationPose C++ 扩展6️⃣
**摘要:本文详细介绍了在Ubuntu 22.04系统上安装PyTorch GPU版本的两种方法(pip全局安装和Conda环境安装),包括准备工作、安装步骤、国内镜像源配置以及验证方法。重点对比了两种方案的优缺点,推荐视觉开发者优先选择pip全局安装方案,同时为需要多环境管理的用户提供Conda备选方案。文中还包含完整的安装命令和验证代码,帮助用户快速完成PyTorch GPU环境的搭建与测试。
ubuntu
——ubuntu
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区




 人工智能6S服务平台
人工智能6S服务平台

 深开鸿 技术专区
深开鸿 技术专区










 EazyDevelop社区
EazyDevelop社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 2048 AI社区
2048 AI社区

 DAMO开发者矩阵
DAMO开发者矩阵



 AI编程社区
AI编程社区





 AI Agent技术社区
AI Agent技术社区
