登录社区云,与社区用户共同成长
邀请您加入社区
创源AIGC更适合被理解为一个内容生产入口,而不是单纯的模型列表。AI图像负责完成角色和视觉设定。Midjourney二次操作负责继续筛选和优化。MiniMax Hailuo 2.3可以用来完成短时长视频样片。AI漫剧、音频、PPT与无限画布则可以继续承接后续内容。是否适合自己的工作流,最直接的方法不是看模型数量,而是选择一个真实项目,在平台里完整跑一遍。
摘要: 《小木的心屋》是一款专为深夜疲惫打工人设计的治愈系H5微应用,通过AI陪伴与情绪调节功能帮助用户缓解焦虑。应用结合LLM Prompt工程、JSON结构化数据输出和ECharts动态雷达图,提供沉浸式交互体验,包括多场景随机切换、六维心情地图可视化和呼吸调节引导。技术亮点包括共情型AI角色设计、自然语言转结构化数据及轻量化前端渲染。免费开放体验,支持全端适配,旨在为用户提供一个温暖、低负担
AI Agent商用元年开启:从"聊天工具"到"数字员工"的质变 2026年标志着AI Agent从理论走向大规模商用,实现了从被动响应到主动执行的范式转变。与需分步指导的传统AI不同,AI Agent具备自主拆解任务、规划流程、联动工具和纠错优化的能力,只需给定目标即可全自动完成复杂工作。这一变革源于三大突破:自主推理能力成熟、跨工具调用实现、动态场景适应
基于腾讯云视觉大模型ai快速生图
你知道是哪个平台吗?
Seedream 3.0 Technical Report:一篇读懂字节 Seedream 3.0 的图像生成系统升级
Seedream 2.0:一篇读懂中文图像生成模型的真正主线
DALL·E 2 的真正转折:一篇读懂 CLIP Latents 如何重写文本生成图像
而成本低的模型又无法满足复杂任务的需求。随着模型能力的提升和成本的降低,越来越多的企业将能够将 AI 技术集成到自己的业务流程中,实现数字化转型。其次,混合架构模型的部署和优化需要专业的工程知识,包括模型量化、推理加速、分布式部署等多个环节,这对于缺乏专业 AI 工程团队的企业来说是一个巨大的障碍。更重要的是,英伟达采取了完全开放的策略,不仅公开了模型权重,还公开了完整的训练数据和训练脚本。未来,
而深耕建筑垂直领域的渲境AI、ADAI(同属Tyrell AI),依托专属建筑渲染大模型,贴合行业真实工作流程,在专业精度、画面质感、实操效率等维度全面领先,成为2026年建筑从业者首选的专业AI渲染工具。同时其光影模板固化单一,仅有基础明暗对比,无法模拟清晨、黄昏、阴雨天、室内灯光、夜景亮化等复杂场景,配景人物、绿植、水景生成生硬违和,画面层次单薄,缺乏空间氛围,很难满足甲方汇报与投标展示需求。
随着国产大模型(如DeepSeek、火山引擎Seed、智谱GLM等)广泛应用,多模型接入面临APIKey管理复杂、计费不统一、故障切换难等问题。主流解决方案包括: 直接对接厂商SDK:简单但耦合度高,缺乏统一监控和容灾能力。 自建API聚合层:统一接口、自动故障转移、集中统计,但需额外运维成本。 第三方聚合平台:适合中小团队,省去运维,但需警惕计费透明度和数据安全。 核心功能需包括统一接口、负载均
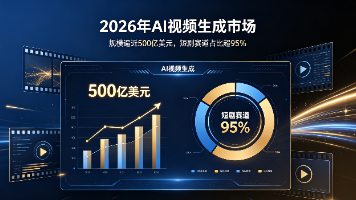
2026年上半年,AI视频生成领域融资密集:AniShort完成近亿元融资,LibTV母公司完成近3亿美元B+轮融资,估值超20亿美元。集成了文生图、参考生图、风格转换及文生/图生视频功能,覆盖从灵感记录、文案生成、素材制作到多平台分发的全流程,适合自媒体创作者在AI视频时代的全链路内容生产需求。,真人短剧的上线量已不足AI短剧的二十分之一。成本的大幅降低,正让AI视频从“专业玩家的玩具”变成“普
网文创作方面,FeelFish更适合长篇小说、剧本创作者,蛙蛙写作聚焦个体网文作者全链路创作需求。是目前能力覆盖最广的工具,支持文本生成、图像创建、语音对话、代码执行和实时网页浏览。在2026年主流AI大模型深度横评中表现亮眼,凭借均衡的中文能力与超高性价比成为国产模型中的实用黑马。通用大模型的好处是覆盖面广,几乎任何类型的文本都能生成。被多家评测机构称为中文写作的“扛把子”,能精准拿捏中文的韵味
覆盖从文案生成、素材制作到多平台分发的完整流程,为自媒体创作者在AI视频时代提供了一套完整的内容生产方案,可灵、Seedance等模型的视频生成能力,与爱峰游的文案创作和多平台分发能力形成互补。可灵从快手内部功能“升级为和电商、商业化并列的一级业务,最终独立分拆冲刺IPO”,这条路对AI创业者极具参考价值。进入2026年,一季度营收6.5亿元,同比增幅超300%,当前年化收入运行率接近5亿美元。快
本文探讨了视频生成模型选型中被忽视的关键因素——延迟问题,通过实测五家主流模型的性能数据,揭示了并发场景下的实际表现差异。研究发现:1)模型冷启动与预热状态延迟差距显著;2)并发处理能力比单条速度更重要,部分模型高并发时出现排队超时;3)分辨率提升会非线性增加延迟。作者建议采用分层策略:分镜预览使用快速模型(360p),成片采用稳定模型(720p),最终交付再跑高分辨率,并推荐通过API聚合实现模
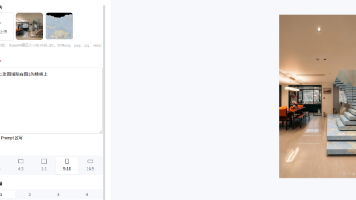
AI短剧制作全流程指南:从剧本到角色设计 本文详细介绍了使用AI工具制作短剧的完整流程:1)剧本生成阶段,需输入详细提示词(身份+任务+关键词)获取故事大纲;2)角色创造环节,建议设计6-8个主配角色并控制描述字数;3)剧情设计要点,强调分集结构和悬念设置;4)人物形象设计,提供标准化的角色设定图模板。文章还提醒注意版权问题,建议通过优化提示词控制AI输出质量,避免过度修饰导致剧情混乱。
从认识ComfyUI到真正动手把它安装好,你经历了从概念到实践的第一次跨越。无论你选择的是轻松的整合包,还是历经波折的手动安装,恭喜你,你已经成功越过了AI绘画学习道路上最大的那个“山丘”。现在,你的工作台已经搭好,核心引擎和第一个灵魂模型也已就位。明天,我们将迎来那个让人心潮澎湃的时刻:加载默认工作流,调整几个参数,然后按下那个神奇的“Queue Prompt”按钮,亲眼看着一张属于你自己的AI
原计划开发无限画布AI流程图网站,结果发现DeepSeek能用矩形工具画画,直接爽玩一下午。欢迎大家一起来试试。
本文对比了5款AI视频生成与分镜脚本工具在2026年的性能与成本表现。重点分析了可灵3.0、阿里万相Flash、字节Seedance等视频API的价格与质量差异,以及通义千问在分镜脚本生成中的成本优势。测试数据显示,采用HappyHorse(¥0.024/s)与Qwen(单次脚本¥0.14)的"屠夫位"组合,可将单集50镜成本控制在¥18-22,比全用高端模型节省60%以上。文章还提供了生产环境中
AI 内容生产的能力边界,正在从“会不会写提示词”转向“能不能建立稳定流程”。一条可用的工作流必须回答:任务是否定义清楚,素材是否可追踪,模型是否按阶段选择,结果是否有验收标准,失败是否能定位,成功配置是否可以复用。当图片、视频、PPT 和漫剧进入同一套任务合同、版本记录和质量验收体系后,多模型平台才不只是工具集合,而会真正成为内容团队的生产基础设施。
【摘要】随着AI工具数量激增,多平台切换成为用户痛点。蝶叙AI(diexuai.com)创新性整合文字创作、图像生成、视频制作等功能,提供一站式AI创作解决方案。相比ChatGPT、Midjourney等单领域强者,其优势在于:1)零门槛网页端操作;2)深度中文优化;3)统一管理多场景需求。特别适合内容创作者、跨境电商(商品套图、多语种适配)、自媒体运营等需要跨模态创作的群体。该平台通过功能聚合显
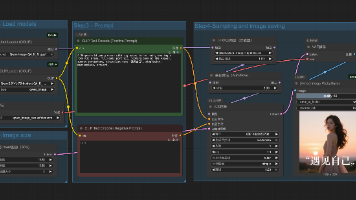
本文分享了两种在ComfyUI中调用阿里通义千问视觉模型Qwen-Image的方案。第一种是原生工作流方案,适合有8GB以上显存的用户,详细介绍了模型加载、工作流搭建等步骤;第二种是使用GGUF量化版本,适合显存有限的用户。文章还提供了提示词技巧、性能优化建议和应用场景分析。最后指出两种方案各有优势,可根据硬件条件和需求选择适合的方案,并强调了ComfyUI模块化工作流的灵活性。
本文对2026年Q3五款主流图生图模型(GPT-Image-2、Gemini 3.1 Flash Image、Qwen-Image 2.0、Doubao Seedream 5.0、Z Image Turbo)进行了角色一致性实测对比。研究显示,GPT-Image-2在角色一致性上表现最优但成本最高,而国产模型如Doubao Seedream 5.0在二次元场景下性价比突出。文章提出了四维度评估体系
摘要: 蒂塔AI是一款集成GPT、Claude、Gemini等主流大模型的多平台AI工具,支持网页、浏览器插件及移动端,无需配置即可使用。核心功能包括智能问答、多场景写作(邮件/论文/脚本等)、代码生成、AI绘画/视频创作及文档处理(翻译/总结/模板生成)。其浏览器插件支持实时网页交互,移动端和网页版操作简便,国内用户友好。通过聚合多模型能力,蒂塔AI覆盖办公、学习、设计全场景,大幅提升效率,注册
AI作画
——AI作画
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 2048 AI社区
2048 AI社区

 智能体开发者社区
智能体开发者社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AI编程社区
AI编程社区





 AI Agent技术社区
AI Agent技术社区

 DeepSeek技术社区
DeepSeek技术社区






 AtomGit AI 社区
AtomGit AI 社区
 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区