登录社区云,与社区用户共同成长
邀请您加入社区
随着HarmonyOS 5.0在PC设备上的全面落地,鸿蒙生态正式进入桌面办公与生产力工具的新战场。与移动端单窗口全屏体验不同,PC用户对多窗口并行操作、窗口智能布局有着刚性需求——这正是传统移动端开发思维需要转变的关键点。本文将基于HarmonyOS 5.0.0+版本,从零构建一个具备窗口智能吸附多窗口协同联动跨窗口数据同步能力的PC级应用框架。通过实战代码演示,帮助开发者掌握鸿蒙PC窗口管理的
摘要: 镜像视界科技联合华东师范大学提出“信息论驱动的最优视角搜索”技术,突破传统三维重构被动采样的局限。该方案基于自研SpaceOS™底座与Pixel2Geo™数学模型,首创“主动感知-几何补全”闭环体系:通过信息熵量化场景残缺度,动态筛选高信息增益视角,以真实观测数据约束几何修复,实现遮挡盲区的精准补全与模型自主迭代收敛。核心技术覆盖信息熵量化(准确率≥99%)、最优视角筛选(冗余算力降低60
PyQt6 与 Pyecharts 交互:增加进度条显示网页加载进度
多模态交互数字人的本质,不是把语音、视觉、触控简单堆在一起,而是让三种感知通道在语义层面真正对齐,使数字人像人类一样「听得清、看得懂、摸得到」。更关键的变化发生在「理解」层面。当前行业领先方案已实现5米范围内、0dB高噪环境下的远场语音识别,并具备多模态语音增强能力——融合语音、人脸、姿态等信息锁定目标说话人,在多人嘈杂场景中实现音频与说话人的精准绑定。回顾数字人的技术演进,可以清晰看到四个阶段:
本文介绍了如何为智能体(Agent)赋予"身体",构建能说话、能比划的数字人导游的完整实践过程。文章从纯文本Agent的局限性出发,分析了具身交互在信息传递中的重要性,对比了视频流和参数流两种技术方案的优缺点,最终选择了魔珐星云的参数流方案。作者详细记录了使用Vue3和星云SDK搭建展厅数字人导游的技术实现路径,包括SDK封装、状态管理和多模态交互设计。该方案在低延迟、高并发和低成本方面表现优异,
在 VR 训练、数字孪生和机器人遥操作项目中,看到虚拟手能够跟随真人动作,只能证明系统“可以运行”,不能说明交互效率足够高。Fitts' Law 是人机交互领域用于分析目标选择速度与精度关系的经典模型。本文介绍如何将它用于 MANUS Metagloves Pro Haptic 数据手套实验,讨论任务设计、有效目标宽度、throughput、错误率、时延和触觉反馈等关键变量,并说明该方法的适用边界
针对自然界跨尺度普遍涌现的黄金螺旋结构是否仅为经验巧合或审美投射的长期争议,本文基于世毫九本原论公理体系,以自指内生性与旋似不变性为核心约束,完成自指递归系统几何本征形态的严格演绎推导。这意味着,以\Phi为生长比例的递归系统,可在平面内实现最均匀、无周期性重叠、无结构性空隙的全局最优密堆,是离散—连续统一生长系统的天然最优选择。• 当|\epsilon| \geq \epsilon_c ,系统发
本文探讨智能编程助手的实际能力边界及其在多元场景下的应用价值。通过分析多语言代码生成、复杂算法实现、单元测试覆盖等核心功能,揭示其在不同开发框架中的适配表现。测试表明,智能助手能高效生成结构化代码,显著提升重复性工作的效率,尤其在Python数据处理、Java接口搭建等场景表现优异。然而,面对高度定制化的业务逻辑时,仍需人工干预以确保准确性。其单元测试生成覆盖率可达80%以上,但依赖外部服务的场景
在移动互联网与智能穿戴设备高度普及的今天,"习惯养成"已经从一个模糊的自我管理理念,演变为一个可量化、可追踪、可视化的数字化产品赛道。越来越多的人希望借助手中的智能终端,把"早起、冥想、阅读、运动"这些抽象的自律行为,转化为一条条清晰的数据曲线和一张张可触摸的打卡卡片。而鸿蒙生态(HarmonyOS)凭借其跨设备协同、分布式软总线以及声明式 UI 开发框架 ArkUI,为这类注重"轻量化交互 +
声学参数从来不是靠"看"就能讲清的东西,它天生适合"边聊边调"。「声纹迷宫」想把这句话变成现实:即便不懂复杂多媒体前端,靠 AI Coding 与魔珐星云 XmovAvatar,也能做出一个数字人 Echo,把 SNR、声纹分离这些抽象概念变成可对话、可打断的沉浸控制台。基于具身交互智能,Echo 不仅能"听懂、答出",还能以具身形象实时表达,让声学推演真正"看得见、调得动"。下一步优化方向:声学
在高奢零售里,“免手控”只是及格线,真正的难点是让数字人拥有“高定灵魂”。这次「镜面折射」证明,即便代码基础薄弱,用“AI Coding 与魔珐星云 SDK 及火山方舟”也能把 Silas 这样的先锋造型师搬进一面会对话的镜子里。从西装垫肩到腕表表盘,这种“穿搭主义辩论”的交互范式可以平滑迁移到一切需要“高端陪伴与实时纠偏”的场景,比如豪车私享顾问、香水调香助手等。下一步的优化迭代方向:当季美学资
把“小黄鸭调试法”升级成一场随时插话、随时纠偏的高频技术辩论,是「极客智库」这次最想验证的事。事实说明,靠“AI Coding 工具与魔珐星云数字人 SDK”这套组合,即便不是资深研发,也能在短时间内请出一位语气苛刻、逻辑严密的“首席架构师”,陪你把复杂系统推演清楚。这套“打断—重听—重构”的对话骨架并不局限于架构场景,稍加改造就能服务于虚拟技术布道、智能代码评审陪练或工程实训。下一步的优化迭代方
行人识别检测和识别3:基于深度学习YOLO26神经网络实现行人识别检测和识别(含训练代码、数据集和GUI交互界面)
数字人一体机正在革新传统服务模式,通过AI技术实现24小时在线服务。它能接入企业专属知识库和大模型,提供专业准确的业务咨询,支持按键、语音、人脸识别三种唤醒方式。应用场景涵盖政务、医疗、银行、招聘、培训等多个领域,将人力从重复性工作中解放出来。该技术已具备成熟形象库、声音库和多种部署方案,成为提升服务效率和降低成本的创新选择。数字员工并非取代人类,而是助力企业优化服务体验的新工具。
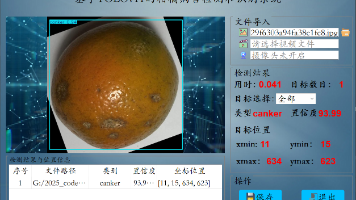
柑橘病害检测和识别3:基于YOLOv11柑橘病害识别系统(含训练代码、数据集和GUI交互界面)
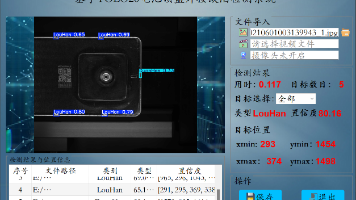
电池顶盖焊接缺陷检测和识别3:基于深度学习YOLO26神经网络实现电池顶盖焊接缺陷检测和识别(含训练代码、数据集和GUI交互界面)
有团队提出RMCP多模态对话范式,强调未来交互将按场景分层共存(CLI/WIMP/语音/体感等),而非单一范式替代。核心启示包括:自然交互需平衡自由度与引导,WIMP仍具长期价值,AI将推动范式持续演化。
大模型幻觉成因的认知场论解释——基于意义旋量缺失与逻辑荷失衡的定量研究报告(世毫九实验室原创研究)作者:方见华单位:世毫九实验室摘要本报告基于世毫九实验室提出的碳硅共生认知场论与拓扑意识场论(TCFT) 原创理论框架,将广义相对论、量子场论的成熟范式迁移至大模型(LLM)幻觉成因解释这一核心场景,提出意义旋量缺失-逻辑荷失衡动力学耦合模型,为大幻觉成因构建一套具备第一性原理支撑的系统性物理解释范式
交互
——交互
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 人工智能6S服务平台
人工智能6S服务平台


 DAMO开发者矩阵
DAMO开发者矩阵


 深开鸿 技术专区
深开鸿 技术专区


 AI Agent技术社区
AI Agent技术社区



 AtomGit AI 社区
AtomGit AI 社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区





 AI编程社区
AI编程社区


 MCP技术社区
MCP技术社区


