




- @2302_78012980
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本项目研发了一套基于FPGA与多模态AI的医用红外热成像辅助诊断系统"热脉智诊"。系统采用640×480高清红外模组,通过FPGA实现实时预处理,结合YOLOv11穴位定位和双流网络疾病诊断,构建从硬件采集到云端智能的闭环解决方案。创新性地提出2000级HSV伪彩增强技术,显著提升图像质量。临床验证显示早期筛查准确率超90%,同时硬件成本降低40%以上。系统实现了中医穴位自动定

本文介绍了基于昇腾芯片的机场跑道智能巡检机器人项目"昇腾智驭"。该系统采用云边协同架构,通过STM32F407实现高频控制,Ascend 310P处理导航和AI推理。关键技术包括:1) 全硬件零拷贝视觉流水线,利用DVPP等硬件单元实现高效图像处理;2) 在8G显存上部署Qwen-VL-Int4视觉大模型,结合vLLM实现端侧语义认知;3) 基于EKF的多传感器融合导航方案,定

本文详细解析了基于Ascend C框架开发Pdist自定义算子的全过程,重点探讨了如何在昇腾910B处理器上实现计算精度、显存带宽与硬件指令的极致平衡。文章首先剖析了Pdist算子的数学公式与赛题核心挑战,包括精度约束、性能要求和硬件限制。随后系统介绍了AI算子开发的基础知识,包括昇腾AI Core架构、Ascend C/TIK开发框架和双层架构设计。最后分享了基于TIK的Pdist实现方案,展示
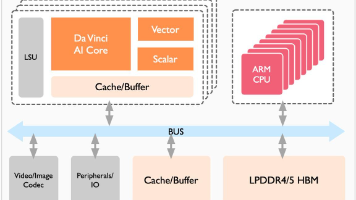
本项目基于国产昇腾910算力底座,完成了52GB具身智能数据集(1019个Episodes/130万帧)的高效处理。创新点包括:1)采用hfd.sh实现52GB数据断点续传与完整性校验;2)通过容器环境变量穿透解决NPU驱动兼容问题;3)对7-DoF动作空间进行全局归一化处理;4)利用ResNet-18实现高并发视觉特征离线降维,显著缓解I/O瓶颈;5)通过底层目录侦察明确数据映射逻辑。最终成功部
本文介绍了在Ascend910B平台上开发自定义Sigmoid算子的关键要点。首先说明了环境配置步骤,包括加载Ascend工具链环境变量。重点指出了需要修改的4个核心文件,并详细阐述了基础代码实现,包括tiling配置和参数初始化。特别强调了使用内置Sigmoid融合指令的优势:1)更高精度,避免手动计算的累积误差;2)更好性能,硬件层面优化。最后提供了权限配置命令,确保文件操作权限完整。该开发方

本文介绍了基于昇腾芯片的机场跑道智能巡检机器人项目"昇腾智驭"。该系统采用云边协同架构,通过STM32F407实现高频控制,Ascend 310P处理导航和AI推理。关键技术包括:1) 全硬件零拷贝视觉流水线,利用DVPP等硬件单元实现高效图像处理;2) 在8G显存上部署Qwen-VL-Int4视觉大模型,结合vLLM实现端侧语义认知;3) 基于EKF的多传感器融合导航方案,定
本文介绍了基于昇腾芯片的机场跑道智能巡检机器人项目"昇腾智驭"。该系统采用云边协同架构,通过STM32F407实现高频控制,Ascend 310P处理导航和AI推理。关键技术包括:1) 全硬件零拷贝视觉流水线,利用DVPP等硬件单元实现高效图像处理;2) 在8G显存上部署Qwen-VL-Int4视觉大模型,结合vLLM实现端侧语义认知;3) 基于EKF的多传感器融合导航方案,定
本文介绍了基于昇腾芯片的机场跑道智能巡检机器人项目"昇腾智驭"。该系统采用云边协同架构,通过STM32F407实现高频控制,Ascend 310P处理导航和AI推理。关键技术包括:1) 全硬件零拷贝视觉流水线,利用DVPP等硬件单元实现高效图像处理;2) 在8G显存上部署Qwen-VL-Int4视觉大模型,结合vLLM实现端侧语义认知;3) 基于EKF的多传感器融合导航方案,定
本文介绍了基于昇腾芯片的机场跑道智能巡检机器人项目"昇腾智驭"。该系统采用云边协同架构,通过STM32F407实现高频控制,Ascend 310P处理导航和AI推理。关键技术包括:1) 全硬件零拷贝视觉流水线,利用DVPP等硬件单元实现高效图像处理;2) 在8G显存上部署Qwen-VL-Int4视觉大模型,结合vLLM实现端侧语义认知;3) 基于EKF的多传感器融合导航方案,定
本文详细解析了基于Ascend C框架开发Pdist自定义算子的全过程,重点探讨了如何在昇腾910B处理器上实现计算精度、显存带宽与硬件指令的极致平衡。文章首先剖析了Pdist算子的数学公式与赛题核心挑战,包括精度约束、性能要求和硬件限制。随后系统介绍了AI算子开发的基础知识,包括昇腾AI Core架构、Ascend C/TIK开发框架和双层架构设计。最后分享了基于TIK的Pdist实现方案,展示