登录社区云,与社区用户共同成长
邀请您加入社区
enabled: 表示启用HyStart算法,这是一个用于改进TCP连接启动阶段的算法,可以更快地达到网络的最佳吞吐量。enabled: 表示接收段合并功能被激活,这可以减少传送到上层应用程序的中断次数,提高网络处理效率。enabled: 表示TCP快速打开功能被激活,这可以在某些情况下减少TCP连接建立的延迟。enabled: 表示在遇到网络拥塞时,TCP拥塞窗口会按照一定比例减少,而不是固定减
这样,原本的第二次挥手(ACK)和第三次挥手(FIN)就合并在了一个TCP报文中,因此抓包工具只会抓取到这个合并后的FIN+ACK报文以及后续的客户端ACK报文,总共是三个包。此时就可以进行数据传输了。[Protocols in frame: eth:ethertype:ip:tcp:data](帧内封装层次协议结构,eth:ethertype:ip:tcp,以太网,以太网协议,ip,tcp)De
摘要: Wireshark和Fatbeans是两款网络数据分析工具,各有侧重。Wireshark擅长协议分析和流量监控,适合网络管理员和协议学习;而Fatbeans更注重数据包拦截、修改和自动化测试,适合开发者、安全测试人员。Wireshark跨平台支持更广,协议解析更专业;Fatbeans操作更友好,功能更聚焦实战需求。建议根据实际需求选择:网络排错用Wireshark,开发调试用Fatbean
本文深度解析NNG通信框架在现代分布式系统中的应用价值与适用场景。文章从技术架构、性能特性、安全机制等维度系统剖析NNG的核心优势,重点分析其在金融交易、物联网、实时分析等领域的实际应用案例。通过与传统消息队列、gRPC等技术对比,为架构师在不同业务场景下的技术选型提供权威参考依据,帮助企业构建高效可靠的分布式通信基础设施。
海外代理IP这件事,其实早就过了比“谁IP多、谁价格低”的阶段,真正拉开差距的,往往是你在连续跑一段时间、并发慢慢拉上来、目标站开始上策略之后,这个代理还能不能稳定顶住,以及一旦成功率开始下滑、超时变多、状态码开始异常时,你有没有足够快的路径把问题排干净,能不能解决问题,才是真的实在。还为高并发、高突发预留的带宽策略,当你的请求量突然拉上来时,你不用一边盯着任务,一边担心是不是下一秒就被限速、被掐
在电脑上打开QQ,选择你想要得到IP地址的好友,拨通QQ电话(这里不管接不接通你都可以在wireshark中抓到他(她)的IP地址)在字符串左边的框里输入020048(因为020048就是QQ UDP72字节的报文头)通过字段判断所需对象的IP地址 :123.138.132.202。你需要抓那个机器的就选择那张网卡,我这里选的是WLAN。再通过创建表达式-data.len == 72。1.打开wi
简单说,动态IP就是会变动的IP地址。当你连接网络、拨号或切换代理时,获取的IP地址不是固定的,而是从一个IP池中动态分配来的。即使换了IP,也不能少了 User-Agent、Referer,否则照样被识别成“机器人”。比如429(Too Many Requests )就是提示你该切换IP或放慢速度了。比如你访问某个网站,系统看到的IP今天是A,明天可能就是B,后天又变成了C。你可以把它理解为:每
例如在大型金融领域(如上交所、国融证券、东吴证券、富国基金等)、国企央企(如中国能建、中国电建、中国华电、中国烟草、中国移动、中国电信、中国商飞等)以及行业巨头(如比亚迪、小米、理想汽车、美团、中粮集团、海尔等),该设备均已成为核心业务系统平稳运行不可或缺的基础设施。● 驱动重定向:客户端或虚拟化服务器上运行的虚拟驱动程序,将接收到的网络数据流还原为本地USB总线信号,操作系统会识别出一个“虚拟直
关键点:两个 IP!!不需要虚拟网卡、不需要 USB 网卡、不需要 VLAN。
IP五元组(IP源地址、IP目的地址、协议号、源端口、目的端口)IP十元组OpenFlow1.0规范定义了包括:输入端口、MAC源地址、MAC目的地址、以太网类型、VLANID、IP源地址、IP目的地址、IP端口、TCP源端口、TCP目的端口
摘要: 本实验基于eNSP模拟企业双ISP出口场景,通过USG防火墙实现多业务流量精准管控。核心方案包括: 多区域划分:内网(财务/研发/WebServer)与双ISP(电信/联通)通过VLAN和子接口隔离。 智能选路: 公网入向:NAT Server将电信/联通公网IP映射到内网Web,结合DNS解析实现运营商分流。 内网出向:策略路由强制财务走电信、研发走联通访问FTP,IP-Link检测链路
本实验基于企业级网络架构,通过华为eNSP模拟器实现防火墙安全策略与智能路由的综合配置。实验采用单臂路由+多VLAN设计,内网划分为财务部、研发部和Web服务器三个区域,外网配置电信/联通双ISP出口。核心实现内容包括:1)基于地址组的精细化ACL域间安全策略,实现财务部免认证与研发部匿名认证的差异化访问控制;2)策略路由(PBR)结合IP-Link链路检测实现业务流量分流与故障自动切换;3)智能
同一个公网 IP,在普通网页访问中可能完全正常,但在账号登录、跨境电商、社媒运营、支付验证或云服务使用时,却可能触发额外验证甚至访问限制。
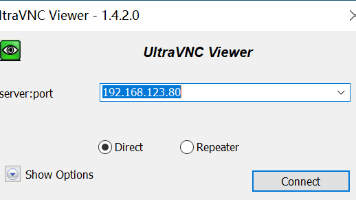
UltraVNC viewer 1.8.2.2及之前版本在RFB协议failure-response解析路径存在整数溢出,导致堆缓冲区溢出。攻击者通过恶意VNC服务器或中间人攻击可触发该漏洞,无需认证,远程代码执行风险高
TCP/IP协议族并非单一的两个协议,而是一套由上百个分层协作的协议共同组成的互联网核心通信体系,它是实现不同厂商、不同操作系统、不同物理网络设备之间互联互通的通用标准,从诞生之初就被设计用来解决异构网络的互联问题,是现代互联网运行的技术基石。
跨境电商代理IP应用指南:核心场景与正确使用方法 随着跨境电商平台风控升级,代理IP成为卖家管理多账号、优化市场调研及本地化运营的关键工具。本文解析代理IP在跨境业务中的六大核心场景: 账号注册与防关联:匹配目标市场IP,降低验证风险; 多店铺运营:提供独立IP环境,避免账号关联; 社媒本地化营销:获取真实地区内容趋势; 竞品数据抓取:模拟目标用户访问,精准分析市场; 广告投放测试:验证地区展示效
跨境电商精细化运营时代,代理IP成为多店铺管理、市场分析的关键工具。本文解析代理IP在账号注册防关联、本地化营销、竞品监控等6大核心场景的应用价值,指导卖家根据业务需求选择动态/静态住宅或ISP代理类型,强调需搭配稳定设备环境使用,避免共享IP、频繁切换等误区,推荐使用纯净独享IP资源以提升运营安全性与数据准确性,助力跨境业务合规高效发展。(148字)
跨境电商精细化运营时代,代理IP成为多平台、多账号管理的关键工具。本文解析代理IP在跨境电商中的六大核心应用场景:新账号注册、多店铺防关联、社媒本地化运营、竞品数据抓取、广告测试验证及AI自动化工具支持。同时指出选择代理IP的三大要点:按业务类型匹配代理方案、构建完整运营环境、规避常见使用误区。文章特别强调静态住宅代理适合长期账号管理,动态代理适用于市场调研,并提醒免费代理存在稳定性风险,建议选择
跨境电商代理IP应用指南:核心场景与正确使用方法 随着跨境电商精细化运营需求增长,代理IP成为解决多账号管理、市场调研和本地化运营的关键工具。本文解析六大核心应用场景: 账号注册与防关联:匹配目标市场IP降低风控风险; 多店铺运营:独立IP环境避免账号关联; 社媒本地化营销:获取真实地区内容数据; 竞品监控与数据分析:模拟本地用户访问精准抓取信息; 广告投放测试:验证地区展示效果; AI自动化工具
这种“创作者主导、AI辅助迭代”的众创新范式,不仅能够最大程度提升IP的生命力,更让百度智能云成为了“超级IP永续工厂”的共同建设者。2026年,生成式人工智能正在迎来它的“工业化落脚点”——AI不再仅仅是创作者手中零散的提效工具,而是开始深度嵌入到整个内容产业链的毛细血管之中。我们愿与创新者同行,用AI为创意赋能,让好的故事、好的创意落地生花、传播更广、流传更久,做创作者最可靠的技术和生态伙伴。
本文介绍了一个AIAgent安全沙箱项目,旨在为AI智能体提供安全可控的工具调用环境。项目采用分层安全架构,在AI智能体与执行环境之间建立安全网关,通过API密钥认证、策略引擎授权和Docker容器隔离等技术手段,实现了默认拒绝、最小授权、执行隔离和操作审计等安全原则。核心功能包括:基于白名单的HTTP/Shell调用控制、流式输出限制、资源配额管理、结构化日志审计等。项目使用Python/Fas
从单臂路由中理解VLAN!
本文介绍了使用MicroPython进行嵌入式开发的优势及其项目架构。MicroPython通过预置硬件驱动和底层库,降低了开发难度和移植成本,其MIT许可也确保了开放性。项目架构采用"核心+端口"模式,核心包含Python编译器和运行时,端口则针对不同硬件平台适配。目录结构清晰划分功能模块,如交叉编译器、外设驱动和测试工具等,并支持多种主流MCU平台如ESP32、STM32和RP2040等,兼具
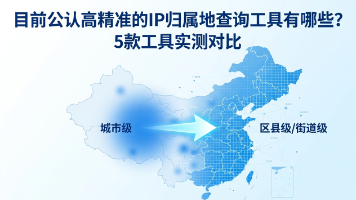
【摘要】实测显示,免费IP库城市级定位准确率仅68%,而商业库可达99%以上。金融风控、广告投放等场景需要区县级甚至街道级精度,传统城市级定位已无法满足需求。对比5款主流工具发现,IP数据云是国内少数支持街道级定位的方案,具备日更机制、20+风险维度和私有化部署能力,特别适合高合规要求的场景。建议通过免费测试验证区县级定位效果,根据实际业务需求选择合适方案。高精度IP定位的核心在于匹配具体业务场景
三星 8nm 量产的 LPDDR5X PHY IP 怎么选?从 9600Mbps 实测到智能汽车与端侧大模型的工艺流片格局指南
硬件负责收音与声音播放;在管理后台,运营者可自由设置角色名称、性格、说话风格,划定知识问答边界,调整音色、语速,匹配对应赛道大模型。创客匠人 AI 智能硬件给出全新解决方案,把知识 IP 的内容、声线、个人特质与服务能力装进实体设备,推动 IP 从屏幕中的线上讲师,转变为随时相伴的交流伙伴。创客匠人 AI 智能硬件的意义,不只是制造一款更智能的硬件产品,而是赋能知识 IP 打造拥有独立声音、人格、
亮数据官方号:新手用户注册就送25刀试用金:
本文介绍了基于TCP协议实现网络计算器的完整方案,重点解决了TCP字节流传输中的粘包/拆包问题。通过设计自定义应用层协议,采用"长度+分隔符"的报文格式,配合JSON序列化/反序列化技术,实现了请求和响应的可靠传输。文章详细阐述了Request/Response类的设计思路,Protocol类的编码解码实现,以及TCPSocket的模板方法封装。服务端采用多进程+守护进程架构确
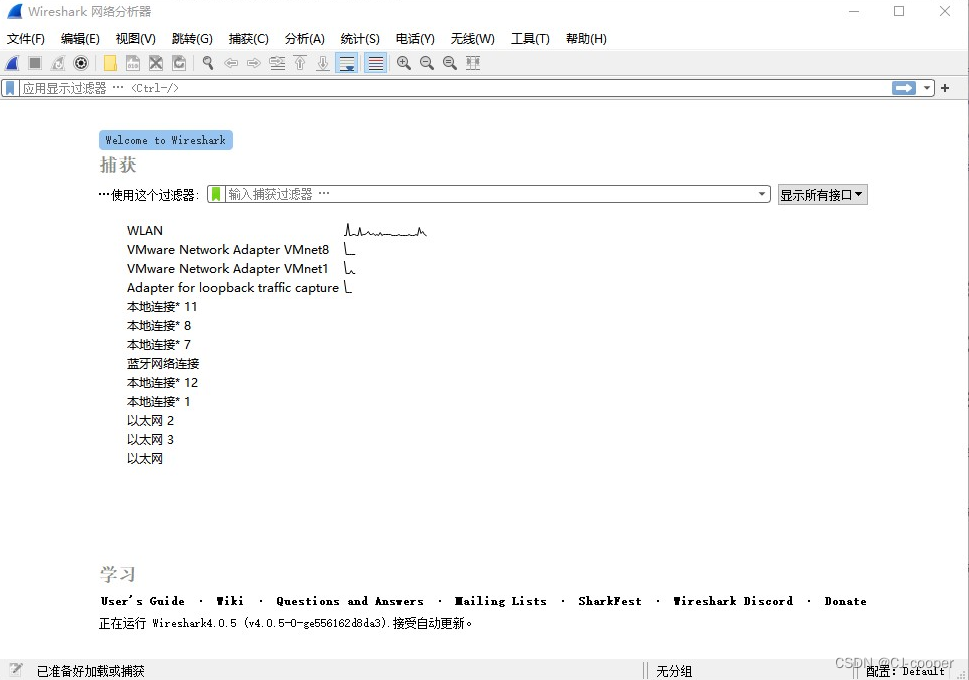
抓包工具WireShark使用及TCP三次握手报文分析
主机方,通过WIFI连接到路由器之后,在网络设置里面,点进去连接到路由器的网络的设置-->IPv4-->手动,配置IP为192.168.11.3(避免与其他IP相同,冲突),子网掩码为255.255.255.0,网关为192.168.11.1(和路由器的IP保持一致)。路由器与AUBO控制柜通过网线连接,主机通过WIFI连接路由器。Aubo示教器方,上电进入设置-->网络,配置IP为192.168
Gmapping通过激光雷达扫描环境并结合机器人的运动信息(里程计),实时生成环境的2D栅格地图(Occupancy Grid Map)。地图数据以格式发布,用于后续的路径规划和定位。Gmapping本身仅负责建图,导航功能需结合其他ROS包(如navigation包中的move_baseamcl等模块)实现。map_server)→ 3.(AMCL)→ 4.(控制器)。
代理IP本质是网络中转工具,用于隐藏真实IP,功能单一且适合短期网络访问需求;VPS则是完整的虚拟专用服务器,拥有独立操作系统和硬件资源,能够运行程序、搭建网站和服务。
本文对2026年Q3五款主流图生图模型(GPT-Image-2、Gemini 3.1 Flash Image、Qwen-Image 2.0、Doubao Seedream 5.0、Z Image Turbo)进行了角色一致性实测对比。研究显示,GPT-Image-2在角色一致性上表现最优但成本最高,而国产模型如Doubao Seedream 5.0在二次元场景下性价比突出。文章提出了四维度评估体系
以 H3C S5570S 和 Comware V7 为例,记录电脑端口已连接但网关不通时,通过正常端口对比定位 Access VLAN 配错,并完成修正、双栈验证和现场排查。
以 H3C S5570S 和 Comware V7 为例,记录在办公 VLAN 中配置 DHCP Snooping 的实际步骤,包括可信聚合上联、终端动态绑定、DHCPv6 配置、验证方法和常见问题。
2026年跨境电商与多账号运营中,IP检测工具的选择至关重要。本文分析了10款主流IP检测工具的核心功能,包括BrowserScan的环境一致性检测、IPQualityScore的AI风控模型等,并强调需结合业务需求选择代理资源。建议采用交叉验证策略,定期检查IP健康度,确保账号安全与业务稳定。
tcp/ip
——tcp/ip
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区








 DAMO开发者矩阵
DAMO开发者矩阵

 openEuler 社区
openEuler 社区




 快递鸟社区
快递鸟社区

 AI硬件创业社区
AI硬件创业社区











 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 智能体开发者社区
智能体开发者社区




 AI编程社区
AI编程社区





 武汉城市开发者社区
武汉城市开发者社区


 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区




 DeepSeek技术社区
DeepSeek技术社区


