




- @kanhao100
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在使用 Overleaf 撰写论文、报告或书籍时,你可能会注意到在菜单中有一个 “Compiler” (编译器) 的选项,里面罗列着 、、 等选项。这些名字看起来很相似,但它们的功能和适用场景却大有不同。选择合适的编译器可以让你的排版工作事半功倍,特别是处理多语言、特殊字体和复杂图形时。本文将深入探讨这几个主流 LaTeX 编译器的区别与联系,并提供一个清晰的总结,帮助你做出最佳选择。首先,我们需
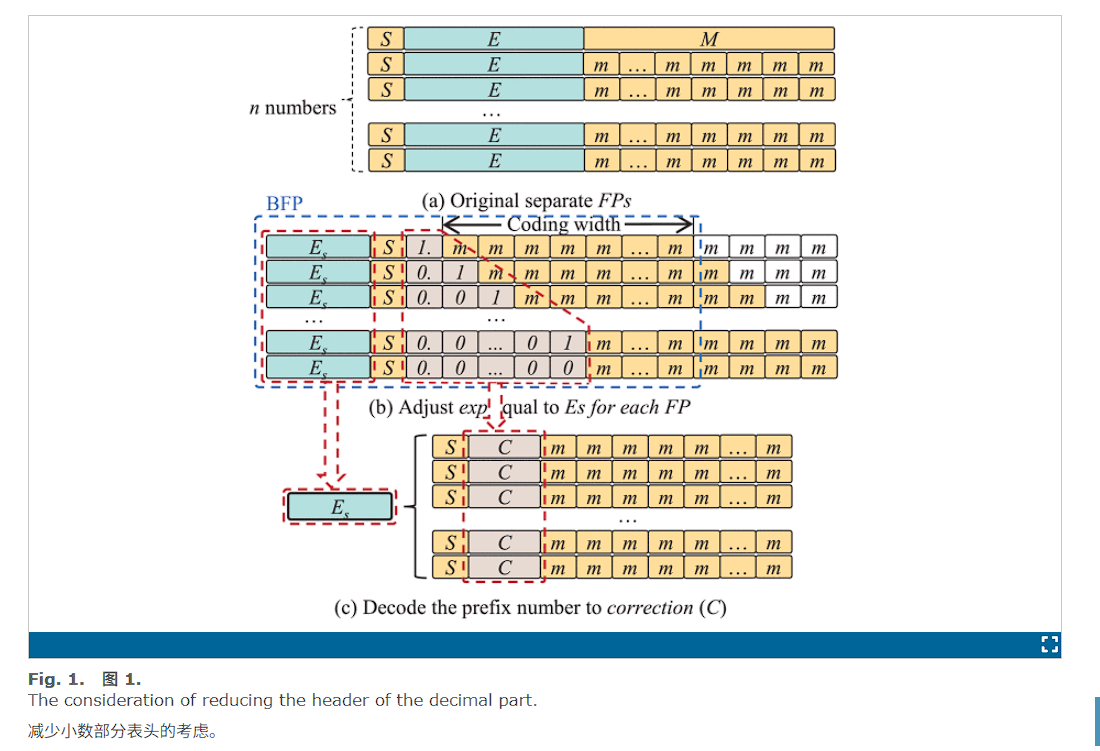
然而,对于浮点精度,所有乘积结果都必须在加法之前进行移位,这使得无法利用 DSP 的级联电路进行优化。本文提出了一种新的浮点格式 , 称为共享指数浮点 (SFP),旨在结合低精度和共享指数方案的优势。此外,我们对多种神经网络进行了测试,结果表明,该格式可用于直接量化全精度模型,并且无需微调即可实现非常低的精度损失(±1%)。块中的每个数据由 E ,年代 和 M ,分别表示指数、符号、尾数部分,其中
这个脚本是Vitis AI应用部署流程的重要组成部分,它在边缘设备上安装必要的运行时环境,使设备能够执行使用Vitis AI开发的应用。这些库使边缘设备能够运行使用Vitis AI开发和优化的深度学习应用程序,充分利用Xilinx硬件加速器(如DPU)的性能。通过这种方式,开发者可以充分利用PC的强大计算能力进行开发,同时确保应用能在边缘设备上高效运行,实现高性能的边缘AI计算。这种分离的方式允许

super_init()是确保 PyTorch 神经网络模块正确初始化的关键步骤。它调用父类nn.Module的初始化方法,设置必要的内部状态,并启用 PyTorch 的核心功能。在 Python 3 中,推荐使用更简洁的语法。无论使用哪种形式,确保在每个继承自nn.Module的类的__init__方法中调用它,这是构建正确功能的 PyTorch 模型的基础。简单来说,这行代码就像告诉您的类:“

随着项目的不断发展和社区的积极参与,torch-mlir有望成为连接PyTorch和各种硬件平台的关键桥梁,为深度学习应用带来更高的性能和更广泛的部署选择。torch-mlir代表了深度学习编译领域的一个重要进步,它将PyTorch的易用性与MLIR的强大编译能力结合起来,为模型部署提供了一个高效的路径。通过将PyTorch的灵活性与MLIR的编译能力相结合,torch-mlir正在为深度学习的未
当GDB显示段错误发生在main()函数的第一行时,通常表明问题出在程序初始化阶段。对于ResNet18这样的深度学习模型实现,最可能的原因是栈溢出或复杂的静态初始化问题。通过增加栈大小、修改内存分配方式、使用内存调试工具,以及仔细检查初始化代码,您应该能够找到并解决这个问题。如果问题依然存在,建议使用backtrace命令获取更详细的错误信息,这将帮助您更准确地定位问题所在。
在本深度学习 (DL) 教程中,您将使用一个公共领域的卷积神经网络 (CNN),如ResNet18,并通过堆栈在 FPGA 设备上运行 DL 推理;该应用程序对图像中“汽车对象”的不同颜色进行分类。尽管 ResNet18 已经在PyTorch框架中的ImageNet数据集上进行了训练,但您将使用数据集(简称VCoR)重新训练它。

电平交叉采样 (LC Sampling)是一种“按需分配”的采样技术。在可穿戴设备和物联网 (AIoT)领域,它解决了“电池焦虑”和“数据冗余”的核心矛盾。它不再盲目地记录数据,而是只记录有意义的变化,并以最精简的脉冲形式直接喂给类脑芯片 (SNN) 进行处理,是实现Always-on(全时在线)监测的关键前端技术。
从计量学上说,OPS是最宽泛的母集合,表示“operations per second”;FLOPS是其中的浮点子集,强调 operation 的数据类型是 floating-point;GOPS和TOPS只是 OPS 的数量级前缀,分别对应 (10^9) 和 (10^{12}) operations per second。Google TPU 论文用描述 8-bit MAC 阵列的峰值吞吐,而
在高层次综合(HLS)设计中,选择合适的数据通信和存储机制对于实现高性能硬件加速器至关重要。不同的通信机制在性能、资源使用和编程复杂度上各有优劣,理解它们的特点可以帮助开发者根据具体应用需求做出最佳选择。本文将详细介绍HLS中常用的几种数据通信机制,帮助您在设计中做出明智的选择。
