登录社区云,与社区用户共同成长
邀请您加入社区
中文分词是自然语言处理的基础技术,其核心任务是将连续的中文字符序列切分为有意义的词语组合。传统基于规则和统计的方法在歧义消解、未登录词识别等方面存在局限,而深度学习通过BiLSTM、Transformer等架构能够自动学习字符级别的上下文表征,显著提升分词准确率。在工程实践中,BiLSTM-CRF模型结合序列标注技术已成为主流方案,通过BMEOS标签体系将分词转化为字符分类问题。针对医疗、法律等专
中文分词是自然语言处理(NLP)的基础技术,其核心是将连续汉字序列切分为有意义的词语单元。传统基于词典的方法面临未登录词(OOV)和歧义切分等挑战,而BiLSTM-CRF等深度学习模型通过捕捉上下文特征显著提升了性能。该架构结合双向LSTM的序列建模能力和CRF的标签转移约束,在MSRA等基准数据集上F1值可达97%以上。工程实践中需重点关注数据预处理(如BIOES标注)、领域适应(医疗/法律文本
文章摘要: 《SinoMem:全本地中文记忆系统,让AI对话告别重复介绍》针对LLM对话无状态的问题,提出轻量级解决方案。通过SQLite+FTS5+jieba分词(支持bigram扩展)实现10ms级中文搜索,可选ONNX本地语义模型(24MB)。相比云API/向量数据库方案,具备零费用、部署简单(pip安装)、分词精准(优化中文召回率)三大优势,支持Claude Code/Hermes等Age
摘要: SinoMem 是一款专为 AI Agent 设计的开源本地记忆系统,主打中文优化与隐私保护。核心特点包括: 本地化存储:使用 SQLite 数据库,无需API调用,零费用且保障数据隐私; 中文搜索优化:集成 jieba 分词+FTS5,支持关键词/语义/混合搜索,解决中文分词难题; 无缝集成:兼容 Claude Code 自动记忆同步和 Hermes 插件,支持多Agent共享记忆。 相
cfg模块是Python自带的一个标准库,其中包含了用于读取和写入INI文件的函数和类。INI文件是一种简单的文本文件格式,通常用于存储配置信息。cfg模块可以轻松读取、修改、创建INI文件,以便在程序中动态地配置参数。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式
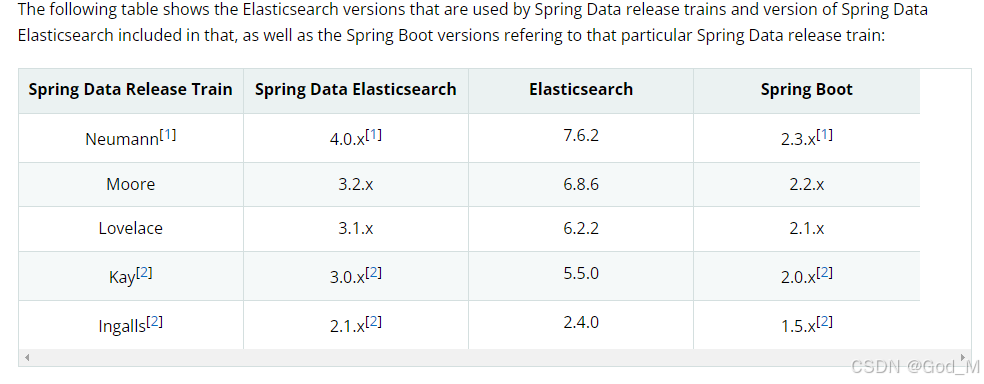
spring-boot版本2.3.7.RELEASEspring-boot-starter-data-elasticsearch版本2.3.7.RELEASEelasticsearch-analysis-ik-7.6.2 中文分词器harbor k8s镜像管理中心ceph 共享存储下图为各软件间的版本对应关系,一定要按照对应关系使用,否则无法成功或出现各种错误。
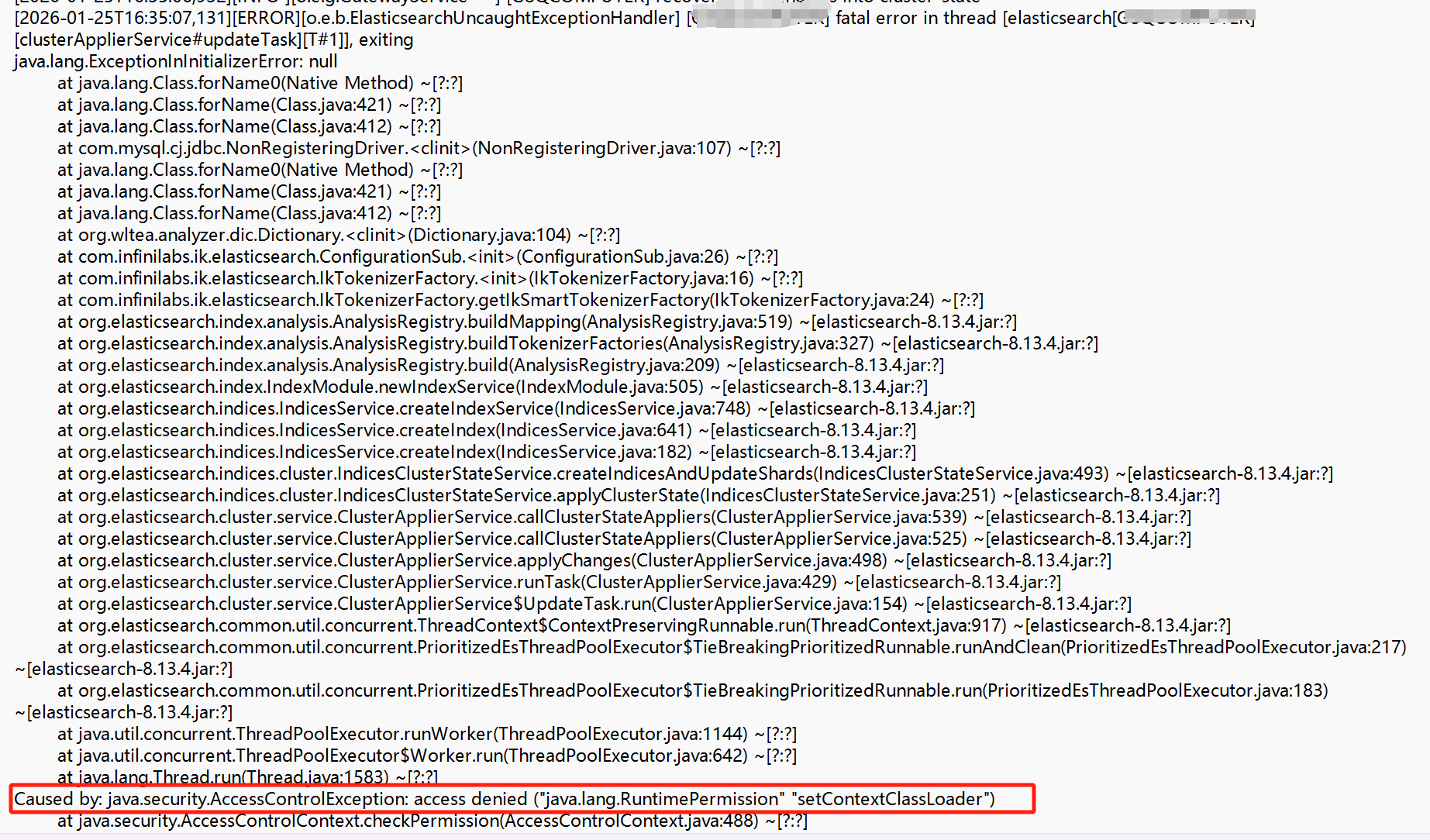
本文介绍了在Elasticsearch 8.13.4中实现IK分词器MySQL词库热更新的方法。通过修改IK源码,添加从MySQL数据库加载扩展词库的功能,解决了文件读取方式性能低的问题。主要步骤包括:1)下载IK源码并添加MySQL词库加载方法;2)配置数据库连接信息;3)实现热更新线程;4)打包部署插件。实施过程中遇到两个主要问题:权限不足和数据库连接异常,通过修改plugin-securit
本文详细对比了Elasticsearch 8.x IK分词器的三种安装方式:在线安装、离线安装和Docker集成,提供了全面的部署指南和性能评测。针对中文分词需求,IK分词器提供ik_smart和ik_max_word两种智能分析模式,有效提升搜索准确率。文章包含版本兼容性检查、安装步骤、配置优化及生产环境最佳实践,帮助开发者快速实现高效的中文文本分析。
IK 自带主词典,业务里那些专有名词、黑话、新词基本覆盖不到。配置文件 IKAnalyzer.cfg.xml 放在 conf/analysis-ik 目录下,里面能挂本地扩展词典、扩展停用词词典,也能挂远程词典。远程那块是热更新入口。配一个 HTTP URL,IK 周期去拉,只要响应里 Last-Modified 或 ETag 有变化,就重新加载词库,不用重启 ES。HTTP 响应得满足两条要求。
本文详细介绍了如何将Jieba分词工具与Elasticsearch 8.x深度集成,构建高性能的中文全文检索系统。通过两种生产级方案(插件化部署和预处理管道)的对比分析,提供了技术选型建议和优化技巧,帮助开发者解决中文分词的核心挑战,提升搜索效果和系统性能。
Elasticsearch(简称 ES)是一个基于构建的分布式搜索与分析引擎。能力说明近实时搜索数据写入后在 1 秒内即可被搜索到(默认刷新间隔)全文检索对文本进行分词、倒排索引、相关性打分,支持模糊、高亮等聚合分析类似 SQL 的 GROUP BY,能在海量数据上做实时统计ES 天然支持分布式部署,一个集群可以横跨数十台服务器,承载 PB 级别的数据,同时保持毫秒级的查询响应。IK 分词器内置了
提示被分词后,"基础 LLM"(或称基础模型)的主要功能就是预测序列中的下一个 token。由于 LLM 在海量文本数据集上训练,对 token 之间的统计关系有很好的把握,因此能较有信心地做出预测。,不同模型(或同一模型的不同版本)对同一提示的分词方式可能不同。由于 LLM 是基于 token(而非原始文本)训练的,提示的分词方式会直接影响生成回复的质量。指令微调 LLM 是在基础模型的基础上,
开发者可以编写自定义分配器,并将其用于标准库容器(如std::list自定义分配器可以针对特定类型或特定使用模式进行优化,例如,固定大小的分配器可以完全避免碎片,或使用线程本地存储(TLS)来创建每线程内存池,从而避免多线程环境下的锁竞争,极大提升并发性能。此外,放置new运算符允许在已分配的内存地址上构造对象,这在实现内存池或需要精确控制对象内存布局时非常有用。
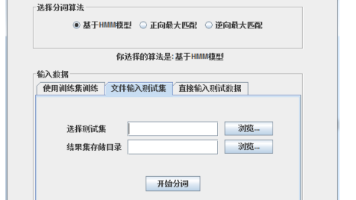
本文介绍了一个基于Java+Swing的中文分词系统设计与实现,结合词频统计、HMM模型和最大匹配算法解决中文分词问题。系统采用三种核心算法:正向/逆向最大匹配和HMM模型,通过构建基础词典和特殊词典提升分词效果。实验对比显示不同算法各有优劣,HMM在未登录词识别上表现较好。文章详细拆解了系统架构、算法实现和优化方向,并提供了毕业设计实践建议,包括技术选型、实现顺序和答辩重点,为学生开发中文分词系
通过分析传统并发模型在大数据场景中的不足,结合函数式编程的不可变性和惰性求值特性,以及结构化并发对任务生命周期的管理优势,设计了一种新型框架。| 数据加载阶段| 42s| 35s| 28s| +50%|| 指标| 传统 (秒) | ComFut (秒) | 本文方案 (秒) | 性能提升(%) |- 惰性求值:通过延迟执行(如`flatMap()`后接`limit()`)减少无效计算。
C++实现NLP中文分词(附带源码)
本文介绍了使用Python的jieba库进行中文分词统计的方法。jieba提供三种分词模式:精确模式、全模式和搜索引擎模式,适用于不同场景。文章详细说明了安装步骤、基本分词操作和词频统计方法,包括引入Counter类进行词频统计。同时介绍了如何通过加载自定义词典提高特定领域的分词准确性,并列举了文本分析、搜索引擎优化和词云生成等应用场景。最后提到可以结合其他工具(如THULAC)进一步提升分词效果
本文系统介绍了Java平台主流中文分词工具的选择与使用。从准确性、性能、易用性等维度对比了IKAnalyzer、HanLP、结巴分词等工具的特点和适用场景,并给出具体选型建议。通过三个实战案例详细演示了IKAnalyzer(搜索引擎场景)、HanLP(企业级NLP)和结巴分词(轻量应用)的代码实现与使用方法,包括基础分词、词性标注、NER识别等核心功能。最后总结了分词工具接入的最佳实践,如统一封装
Langchain-Chatchat凭借对中文语义的深度优化和开箱即用的设计,成为企业本地化RAG应用的理想选择。它支持多种文档格式解析、采用中文专用embedding模型,并提供完整前后端系统,兼顾数据安全与易用性。相比其他主流框架,更贴合中文场景下的部署需求。
在企业级知识库中,中文分词与文本分块方式直接影响大模型的理解效果。通过增强jieba词典、调整分隔符优先级、使用BGE嵌入模型,可显著减少语义割裂,将问答准确率从62%提升至89%。实际优化需协同分词与分块策略,并持续迭代领域术语库。
途虫Ai获客截流使用教程
本文介绍了如何在星图GPU平台上自动化部署百川2-13B-对话模型-4bits量化版 WebUI v1.0镜像,优化中文分词功能以提升OpenClaw文件处理准确率。该镜像特别适用于法律合同等专业文档的自动化处理,通过调整tokenizer配置,可显著改善专有名词拆分和中英文混排等常见问题,使条款识别准确率提升27%以上。
本文详细介绍了中文分词的核心算法FMM/RMM的Python实现方法,包括正向最大匹配(FMM)和逆向最大匹配(RMM)的原理与代码实战。通过实例演示和性能对比,帮助开发者深入理解分词工具背后的技术细节,并提供了词典优化和性能提升的实用建议。
在信息爆炸的时代,快速从文本中抓取核心信息的能力非常重要。TF-IDF 是 NLP 领域最经典、也最容易上手的关键词提取算法之一。本文将带你从零开始,完成从文本读取、分词、去停用词,到使用 TF-IDF 提取每一回关键词的全过程,代码清晰易懂,有需要可直接运行。TF-IDF(词频 - 逆文档频率)是一种统计方法,用来评估一个词在文本中的重要程度:TF(词频):这个词在当前文本中出现的次数。出现越多
本文详细介绍了如何使用Python实现基于隐马尔可夫模型(HMM)的中文分词器,包括核心概念、数据准备、概率统计、Viterbi算法实现及优化技巧。通过实战代码演示,帮助开发者快速掌握HMM在中文分词中的应用,提升自然语言处理能力。
本文通过Python实战演示了HMM(隐马尔可夫模型)在中文分词中的应用,从概率计算到Viterbi解码的全过程。文章提供了完整的代码实现和语料示例,帮助读者理解如何利用HMM自动学习分词规律,有效处理未登录词问题,适用于自然语言处理任务。
本文详细介绍了如何使用Python的pyltp 3.4.0模型,通过5个步骤实现高效的中文分词与词性标注。从环境配置到文本预处理、词性标注、命名实体识别,再到构建完整的文本处理流水线,帮助开发者快速掌握中文文本分析技术,提升数据处理效率。
直接运行就能跑通的中文新闻分类项目,用Python实现从原始文本到最终预测的完整链路。先用jieba做中文分词,再结合自定义停用词表(stopwords.txt)清洗干扰词;接着用TF-IDF把新闻转换成数值特征向量,支持词频与文档频率联合加权;用LDA主题模型探索新闻语料中的潜在类别分布,辅助理解数据结构;最后训练朴素贝叶斯分类器完成多类新闻(如体育、财经、科技等)自动判别。配套真实新闻语料(d
本文详细介绍了如何使用Python从零构建基于隐马尔可夫模型(HMM)的中文分词器,包括HMM核心原理、Viterbi算法实现及PKU语料库的应用。通过完整的代码示例和实战技巧,帮助开发者掌握统计分词技术,提升中文文本处理能力。
本文详细介绍了中文分词中的两种经典算法——正向最大匹配(FMM)和逆向最大匹配(RMM),并通过Python代码实现展示了它们的核心原理和应用场景。文章不仅提供了完整的代码示例,还对比了两种算法的优缺点,帮助开发者深入理解中文分词技术,提升NLP处理能力。
本文通过Python实战演示了维特比算法在中文分词中的应用,从动态规划基础到完整代码实现,帮助读者理解如何利用Viterbi Algorithm解决最优路径问题。文章包含详细的分词实战案例和算法优化技巧,适合机器学习爱好者和自然语言处理开发者学习参考。
直接上手就能用的垃圾邮件分类代码包,用朴素贝叶斯算法实现,专为中文环境优化。内置结巴分词支持,自动处理中英文混合邮件内容;附带清洗好的400封实测邮件(正常和垃圾各200封),分别放在spam/、normal/、test/目录下;提供ttss.py主脚本,一键完成训练、预测和准确率统计;含中文停用词表和requirements.txt依赖清单,Python 3.4及以上即可运行。整个流程不依赖复杂
直接跑通豆瓣短评情感判断的完整Python工程,含数据清洗、中文分词(已集成影视领域自定义词典userdict.txt)、停用词过滤(stopwords.txt)、TF-IDF特征构建、朴素贝叶斯模型训练(native_bayes_train.py)与预测(native_bayes_test.py),以及封装好的可导入分析模块(native_bayes_sentiment_analyzer.py)
自然语言处理(NLP)是让机器理解人类语言的基础技术,其核心在于将非结构化文本转化为模型可学习的结构化特征。原理上需跨越原始数据规整、语义标准化、上下文表征三层抽象,技术价值体现在鲁棒性、低延迟与可解释性三大生产指标。典型应用场景包括电商评论情感分析、医疗命名实体识别和工业日志异常检测——这些任务共同面临中文分词不准、数字单位歧义、emoji语义漂移等挑战。本文聚焦Python生态下的可调试、可干
jieba是Python中最受欢迎的中文分词工具,GitHub星标近3.5万。它提供精确模式、全模式、搜索引擎模式和深度学习模式四种分词方式,满足不同场景需求。核心算法采用前缀词典加动态规划的组合,兼顾准确性和效率。除基础分词外,还支持关键词提取、词性标注等扩展功能,并具有跨语言生态优势。其API设计简洁,支持自定义词典和并行处理,在文本分析和搜索引擎等领域广泛应用。jieba凭借稳定性和灵活性成
本文详细介绍了如何使用Python从零构建基于隐马尔可夫模型(HMM)的中文分词器,涵盖BMES标注体系、HMM三要素计算、Viterbi算法解码等核心内容。通过实战代码演示,帮助读者掌握统计分词技术,实现高效的中文文本处理。
本文提供了一份详细的Python教程,教你如何从零开始构建一个基于隐马尔可夫模型(HMM)的中文分词器。教程包含完整的代码实现、pku_training.utf8数据集的使用方法,以及HMM模型的核心设计、训练过程和Viterbi算法的优化技巧,帮助开发者掌握统计分词技术。
清华大学NLP实验室开源的THULAC-Java工具包,专为Java环境设计,提供开箱即用的中文分词和词性标注能力。基于5800万字人工标注语料训练,在CTB5标准测试集上分词F1值达97.3%,词性标注F1值达92.9%。资源包包含全部源代码(src/main/java)、单元测试(test)、技术文档(doc)、使用说明(README.md)、模型文件(cws_model.bin、model.
自然语言处理(NLP)是人工智能的核心分支,其本质是让机器具备理解、生成和推理人类语言的能力。在工程实践中,NLP并非始于Transformer架构或词向量推导,而是始于真实文本的脏乱差——如乱码、emoji混排、中英文夹杂与业务噪声。关键技术瓶颈往往不在模型本身,而在数据诊断、中文清洗、分词适配与特征表达等基础环节。例如,jieba分词需结合自定义词典应对专业术语,TF-IDF需配合业务规则规避
中文分词
——中文分词
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区






 AI Agent技术社区
AI Agent技术社区







 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区










