登录社区云,与社区用户共同成长
邀请您加入社区
Claude Code 是一款基于人工智能的代码生成与辅助工具,旨在帮助开发者提高编码效率。它能够理解自然语言描述的需求,并生成高质量的代码片段,支持多种编程语言,包括 Python、JavaScript、Java、C++ 等。代码生成:根据用户输入的自然语言描述生成代码,例如“写一个 Python 函数计算斐波那契数列”。代码补全:在编写代码时提供智能补全建议,减少重复性输入。错误检测与修复:分
5、完成后检查 ollama 在后台运行后,在浏览器里安装 Page Assist 插件即可正常运行 deepseek 模型,至此你的 deepseek 本地部署完成,开启你的专属 AI 助手吧。4、WIN+R 键,输入 "cmd" 打开命令行窗口,并且输入复制的相关 deepseek 模型命令行。3、打开 ollama 并找到 deepseek 模型,选择想要安装的版本,并且复制相关的命令行。1
二、架构统一:从“串行流水线”到“一体贯通”三、能力演进:从端到端到VLA再到世界模型。一、范式革命:从“写规则”到“学驾驶”五、挑战与前路:范式已定,工程决胜。四、产业落地:从概念到量产加速跑。端到端成趋势,决策范式革新。
这意味着,如果外界没有强引用指向这个 ThreadLocal 对象(比如我们把 ThreadLocal 变量设为了 null),下次垃圾回收时,这个 Key 就会被回收掉,于是 Map 里就出现了一个 Key 为 null,但 Value 依然存在的 Entry。这不仅是清理当前值,更重要的是它会清理掉整个 Entry,这是最有效、最安全的做法。这个 Value 是一个强引用,只要线程还活着(比如
今天分享开源项目 SubsTracker,直接在 Cloudflare 免费部署,全程不用租用服务器,依靠 Workers 运行,个人使用完全免费。操作门槛很低,小白跟着流程十几分钟就能搭建完毕,全部数据由自己保存,隐私安全更有保障,站长与经常购买各类线上服务非常适用。每月各式各样付费订阅越来越多:ChatGPT Plus、域名、云服务器、各类软件会员,经常悄无声息自动扣款,一不小心就白白浪费开销
本文旨在全面解析BeautifulSoup库中事件驱动解析模式的实现原理和使用方法。我们将覆盖从基础概念到高级用法的完整知识体系,特别关注在大规模HTML文档处理场景下的性能优化策略。文章首先介绍HTML解析的基本概念,然后深入BeautifulSoup的事件驱动机制,接着通过代码示例展示实际应用,最后讨论性能优化和未来发展趋势。DOM解析:将整个文档加载到内存中形成树状结构的解析方式SAX解析:
Beautifulsuop介绍与使用
随着C++11标准的推出,智能指针和RAII(Resource Acquisition Is Initialization)机制成为现代C++内存管理的基石,极大地简化了资源管理工作。当对象被销毁时,它自动释放资源。这种机制利用了C++的析构函数确定性调用的特性,确保资源在任何执行路径下都能被正确释放,即使在异常发生时也是如此。通过将资源封装在类中,开发者可以避免常见的资源泄漏问题,写出更加健壮和
本文详细介绍了Python爬虫开发环境的搭建步骤,重点讲解了Requests、Lxml和BeautifulSoup三个核心库的安装与配置方法。内容涵盖Windows、macOS和Linux三大操作系统的Python安装指南,pip包管理工具的配置与升级,以及各依赖库的安装验证过程。文章还提供了环境测试方案,通过编写一个简单的百度爬虫来验证环境是否搭建成功,并针对常见安装问题给出解决方案。这套完整的
本文介绍了网络爬虫的基础知识,包括定义、工作流程和常用Python工具(requests、BeautifulSoup)。重点探讨了爬虫的伦理与法律问题,如遵守robots.txt、请求频率限制和数据版权。提供了环境设置指南,并详细讲解了如何使用requests获取网页内容和BeautifulSoup解析HTML的方法,包括查找元素、提取数据的技巧。最后通过一个实战项目演示了如何爬取图书网站信息并存
Python BeautifulSoup 使用教程
他的任务是前往指定地点(URL),取回一个“加密包裹”(网页响应),然后安全地带回来。,将一长串无序的字符串,转换成一个结构化的、可以轻松遍历和搜索的Python对象。只是一个解析器,它还需要一个“引擎”来工作。这个包裹(HTML/XML内容),从中找出你需要的具体情报。他的工作是待在总部,等“外勤特工”带回包裹后,他负责。(访问网页、调用API等),并获取服务器的响应。包裹里是什么,只负责。
通过本文的介绍,你已经全面掌握了requests和的使用方法。requests:用于发送 HTTP 请求,获取网页内容。发送 GET 和 POST 请求。处理请求参数,如查询参数和请求头。处理响应内容,如获取响应文本和 JSON。异常处理,处理 HTTP 错误和连接错误。:用于解析 HTML 内容,提取所需数据。创建 BeautifulSoup 对象,解析 HTML 文档。搜索文档树,按标签名、类
Beautiful Soup是python的一个 HTML/XML 解析库,提供了简单易用的 API,适合快速提取和操作网页内容。不是解析器本身,而是一个解析工具,
Pregel的同步计算模型确保了企业级应用所需的确定性和可靠性,而其分布式架构则提供了处理海量关联数据的能力。虽然技术不断发展,但Pregel奠定的设计理念至今仍在影响新一代图计算系统。今天我们来深度拆解企业级可控AI智能体背后的核心引擎——Google Pregel分布式图处理系统。Pregel采用"顶点为中心"的编程模型,将整个计算过程抽象为多个"超级步"。Worker节点:负责本地图数据的计
本文面向 Python 网络爬虫初学者,介绍 requests 与 BeautifulSoup 的基本用法、HTML 解析、标签查找、标题与链接提取、批量抓取、保存 txt 和 Excel,以及基础反爬注意事项。
BeautifulSoup,它是一个用于解析 HTML 和 XML 文档的 Python 库,能够从网页中提取数据,常用于网页抓取和数据挖掘。安装 pip3 install lxml# 推荐使用 lxml 作为解析器(速度更快)如果你没有 lxml,可以使用 Python 内置的 html.parser 作为解析器。
本文详细解析了一款基于 Python 的当当网二手图书爬虫项目。该爬虫采用 requests + BeautifulSoup 技术栈,实现了对图书信息的自动化抓取,包括 ISBN、书名、作者、出版社、原价、二手价、封面图及品相等核心字段。项目核心亮点体现在三个方面:其一,采用多选择器容错解析策略,即使网页结构变化也能稳定提取数据;其二,设计了列表页与详情页相结合的二级抓取机制,确保信息完整性;其三
本文介绍了使用Python的requests和BeautifulSoup库实现网页爬虫的完整流程。首先通过pip安装所需库,然后演示如何发送HTTP请求获取网页内容,并添加User-Agent头部模拟浏览器访问。接着使用BeautifulSoup解析HTML文档,提取名言、作者和标签信息。文章还展示了翻页抓取多页数据的方法,并将结果保存为JSON和CSV格式文件。最后总结了爬虫常用技巧,包括添加延
本项目介绍了一个简易Python静态网页爬虫的实现方法,使用requests和BeautifulSoup库完成网页抓取与解析。核心流程包括发送请求、解析HTML、提取数据三个步骤,并提供了完整的实战代码示例。代码演示了如何获取网页标题和所有链接,同时讲解了请求头伪装、编码设置、标签解析等关键技术点。文章还提出了爬取不同类型数据、存储结果和优化爬虫等拓展方向,适合Python爬虫新手入门学习。通过这
网络爬虫入门:Requests与BeautifulSoup实战 摘要 本文介绍了使用Python进行网络爬虫开发的基础知识,重点讲解了Requests和BeautifulSoup两大核心库的使用方法。主要内容包括: 爬虫基本概念与工作流程 HTTP协议基础(请求方法、状态码、请求头) Requests库的安装与使用(GET/POST请求、添加headers、异常处理) BeautifulSoup的
使用python 爬虫,抓取金十数据财经早餐专栏的每天全球指数收盘情况总结图
行业看点:大模型、端侧AI算力爆发后,内存带宽、延迟成为算力核心制约,本次收购补齐AMD内存技术自研能力,服务器、AI芯片产品线竞争力将进一步提升。伴随边缘AI、工业智能设备规模化落地,Wi-Fi 7凭借高带宽、低时延、多设备并发优势,成为边缘智能场景主流通信技术,产业建设浪潮全面开启。行业看点:AI芯片、存储、功率半导体、通信芯片四大品类拉动行业整体增长,全球半导体产业进入上行周期,产业链上下游
华硕灵耀16 Air 2026在16英寸大屏机身中内置了83Wh大容量电池,可实现至高25小时的持久续航,从早9点到晚9点一整天的移动办公完全不用带充电器,即便遇到跨城出差也能从容应对。在续航管理方面,该机配备了超薄散热方案,双风扇搭配超薄均热板,加上C面几何格栅通风设计,通过2948个CNC加工散热孔提升50%气流效率,实现28W高能释放,用更低的功耗满足日常办公需求。然而,市面上不少轻薄本在宣
我做论文科普这么久,最怕的就是有人觉得"用AI就是不认真"。真不是。工具的意义从来不是替你思考,而是帮你省掉那些重复的、消耗性的劳动,让你把有限的精力花在真正需要动脑子的地方。*)做的就是这件事——主题帮你定、文献帮你找、大纲帮你搭、图表帮你预留,连开题报告都能接着你的往下走。所以,如果你现在正对着空白文档发呆,与其焦虑,不如行动。👉微信公众号搜一搜"书匠策AI"***,去试试看。说不定,你的论
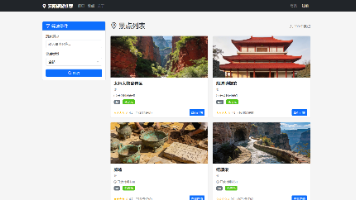
本文设计并实现了一个基于数据挖掘的安阳旅游景点个性化推荐系统。系统采用Flask框架开发,集成SVM和朴素贝叶斯情感分析算法、Apriori和FP-Growth关联规则挖掘算法,构建动态加权混合推荐模型。通过采集携程网景点数据与用户评论,实现了景点浏览、评论情感分析、个性化推荐等功能,并结合ECharts实现数据可视化展示。研究表明,该系统能有效解决旅游信息过载问题,提升用户体验。系统测试表明,混
)不是那种"一键出稿"的代写工具,它更像是一个陪你走完全程的论文搭子:选题它帮你想、大纲它帮你搭、文献它帮你找、格式它帮你调。它不替你思考,但它帮你把思考的路铺平。微信公众号搜一搜书匠策AI*直接上手。别再一个人硬扛了,让AI当你的"论文辅助",把精力留给真正需要你动脑的部分吧。💪(本文为论文写作科普,请合理使用工具,遵守学术规范。
调用多个api接口来进行不同类型(数据文件)情绪分析处理,并利用flask框架与前端联调将自己的情绪分析项目部署到服务器端。
beautifulsoup
——beautifulsoup
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 DAMO开发者矩阵
DAMO开发者矩阵

 AtomGit AI 社区
AtomGit AI 社区


 AI Agent技术社区
AI Agent技术社区











 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区










 openEuler 社区
openEuler 社区

 AtomGit开源社区
AtomGit开源社区