登录社区云,与社区用户共同成长
邀请您加入社区
在多输入多输出(MIMO)通信系统中,信道状态信息(CSI)的准确量化对于高效的数据传输至关重要。随着通信系统复杂度的增加以及对高速、可靠通信需求的增长,传统的 CSI 量化方法面临着诸多挑战。近年来,深度学习凭借其强大的特征提取和模式识别能力,为 CSI 量化提供了新的解决方案。特别是在时相关的 MIMO 信道环境下,利用深度学习进行递归 CSI 量化具有显著的优势。本文将深入探讨基于深度学习分
本文介绍了机器学习基础概念及KNN算法应用。文章以智能寝室分配和鸢尾花分类为例,展示了KNN算法的实际应用。
智慧农业之农作物茄子计算机视觉数据集 茄子识别数据集 茄子状态识别 茄子分拣识别 茄子自动化分类数据集 茄子品质检测数据集10237期
AI的核心目标是让机器能够执行通常需要人类智能的任务,例如语言理解、突袭图像图识别、复杂问题解决等。早期阶段:以规则为基础的专家系统,依赖预设的逻辑和规则。机器学习时代:通过数据训练模型,使机器能够从数据中学习规律。深度学习时代:利用神经网络模拟人脑的复杂结构,处理更复杂的任务。大模型时代;以大规模数据和算力为基础,构建通用性强、性能卓越的AI 模型。
随着道路交通量的不断增加,交通事故的发生频率也呈现上升趋势。事故发生后,快速、准确地评估车辆受损情况,对于保险理赔、道路安全分析、交通事故责任判定以及事故风险预警具有重要意义。传统人工评估方法存在效率低、主观性强、覆盖面有限等问题,难以满足现代智能交通系统对数据实时性和精确性的需求。为此,本数据集专注于交通事故车辆受损情况的识别与分级,面向目标检测与图像分类任务,构建了覆盖多种道路环境与事故类型的
智能超市结算系统水果与蔬菜识别数据集 自动称重AI识别图像数据集 蔬菜水果分类和识别数据集 AI识别结算系统
AI Agent 框架分类与代表对比
摘要:本文介绍基于天宫二号遥感图像数据集(NaSC-TG2)的深度学习分类方法。该数据集包含10类场景(如海滩、农田、雪山等)共20000张128×128像素的RGB图像,其中2000张用于训练。建议采用卷积神经网络(CNN)模型,通过数据增强解决样本不足问题,并利用迁移学习提升模型性能。训练完成后,模型可对18000张测试集图像进行自动分类识别。该方法可应用于国土资源、生态环境等领域的遥感图像智
类别名称:['american_football','baseball','basketball','billiard_ball','bowling_ball','cricket_ball','football','golf_ball','hockey_ball','hockey_puck','rugby_ball','shuttlecock','table_tennis_ball','tenni
对无标注CT图像(共5000张),通过弱增强(翻转缩放)输入教师网络得到伪标签,同时计算证据不确定性:每个像素属于结节的概率服从Beta分布,分布的浓度参数由网络额外分支输出。训练160个epoch,初始学习率0.001,批次大小8。测试集上,分割平均Dice系数达到0.891,相比传统U-Net的0.827提升显著,对小于5mm的微小结节,Dice也从0.675升至0.748。使用多核学习分类器
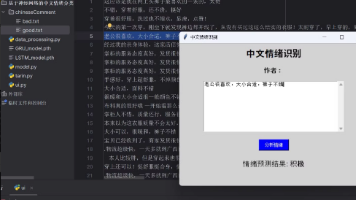
本文介绍了一个基于PyTorch的中文情绪分类系统,支持RNN、LSTM和GRU三种神经网络模型。系统包含数据预处理、模型训练与评估模块,并实现了可视化UI界面、训练过程可视化以及GPU加速训练功能。通过jieba分词处理中文文本,使用PyTorch构建可切换的神经网络模型,并提供了完整的训练流程代码。该系统能够有效完成中文文本的情绪分类任务,支持正面/负面情感判断,具有较高的实用性和可扩展性。
智慧隧道场景识别 隧道渗漏识别 隧道裂缝 隧道脱落 地铁隧道渗漏、地铁裂缝、地铁墙壁剥落 图像分类和目标检测数据集 (1)
1.加载数据集df = pd.read_csv('./data/红酒品质分类.csv')#2.查看数据集df.info()#3.抽取特征数据和标签数据y = df.iloc[:, -1] - 3 #最后一列是标签,默认标签是[3-8],-3后转换为[0,5]#4.查看数据print(f'查看标签数据是否均衡{Counter(y)}')#5.切分训练集和测试集 参5:参考数据集的标签分布#6.将上述
在预测时,每个模型都对样本进行预测,得到 N(N-1)/2 个预测结果。然而,它可能会受到类别不平衡问题的影响,因为每个模型的样本分布可能不同。OvO 策略需要训练更多的模型,但它对于类别不平衡的情况更加稳健,因为每个模型只关注两个类别,样本分布相对平衡。在预测时,对于一个新样本,每个模型都会给出一个预测概率或类别标签。在预测速度上,OvR 策略需要计算所有模型的预测结果,而 OvO 策略只需要计
智慧渔业之鱼分类检测数据集 鱼类分类识别数据 鱼种类分类识别数据集 鱼识别数据集
本文介绍了一个高质量的五类生活固体垃圾分类目标检测数据集,专为智能垃圾分类系统研发而设计。该数据集包含玻璃、金属、纸张、塑料和废弃物五大类别,采用标准YOLO格式标注,覆盖真实生活场景中的复杂环境、多光照条件和不同尺寸目标。数据集具有三大核心优势:高质量人工标注确保边界框精准;类别设置贴合实际垃圾分类需求;标准化格式兼容主流深度学习框架。该资源可广泛应用于智能垃圾分类箱、自动化分拣系统、环保巡检设
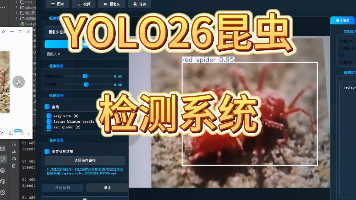
本文构建了一套基于YOLO26的农业害虫检测系统,旨在实现对10类常见水稻与小麦害虫的自动识别与定位。系统采用YOLO26作为核心检测模型,训练数据集共计995张标注图像,其中训练集696张、验证集199张、测试集100张。实验结果显示,模型在验证集上的整体平均精度(mAP50)达到0.932,mAP50-95为0.64,单张图像推理速度约为5.6ms,展现出高精度与实时性的双重优势。混淆矩阵与精
智能湿地保护鸟类识别数据集 鸟类分类数据集 八哥识别 yolov8翡翠鸟识别麻雀数据集鸟类研究目标检测数据集第10275期
标注类别名称(注意yolo格式类别顺序不和这个对应,而以labels文件夹classes.txt为准):["bianzhiyan","chenjiyan","huochengyan"]数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)对应中文类别名:["火成岩", "变质岩", "沉积岩"]图片
分类
——分类
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区






 智能体开发者社区
智能体开发者社区
 AI编程社区
AI编程社区