登录社区云,与社区用户共同成长
邀请您加入社区
本文详细介绍了如何使用DBSCAN算法进行电商用户行为数据的聚类分析,突破K-Means在非球形数据上的局限。通过参数调优技巧和实战案例,帮助数据分析师有效识别不规则密度分布的用户群体,提升业务洞察力。
本文详细介绍了如何使用Python实现聚类性能的三大评估指标:Jaccard系数(JC)、FM指数(FMI)和Rand指数(RI)。通过数学原理和代码实战,帮助开发者从零掌握这些外部评估方法,提升机器学习聚类任务的效果分析与优化能力。
聚类算法是一种无监督学习方法,旨在将数据集中的样本划分为若干个互不相交的子集(称为“簇”),使得同一簇内的样本尽可能相似,而不同簇间的样本尽可能不同。
掌握了K-Means聚类的核心原理:通过迭代优化,最小化簇内距离。学会了使用肘部法则和轮廓系数科学地确定最佳簇数K。在鸢尾花数据集上完整实现了K-Means聚类流程,并进行了可视化分析。建立了关键联系:通过将聚类结果与真实标签对比,以及将聚类特征作为输入,直观展示了无监督学习如何为监督学习提供价值。K-Means虽简单,却是理解聚类、原型学习和数据降维思想的基石。它的局限性(如需预设K、假设球形簇
唯一实际使用的聚类方法— 基于的2D 空间邻近线段聚类(区域生长 + AABB 合并)。未使用:KMeans、DBSCAN、层次聚类、谱聚类等(sklearn仅出现在yolo_skill,与 CAD 无关)。主要应用场景:零件/图块分离 → OBB 标注、按簇导出 DXF、按簇打印 PDF。若要调效果,关键参数就是各脚本里的 distance_threshold:过小会碎成很多簇,过大则不同零件被
本文详细介绍了如何使用Python实现K-Means聚类算法,从Excel数据读取到三维可视化的完整流程。通过手把手教程,读者将学习数据预处理、算法实现、参数调优及三维可视化技巧,特别适合数据分析初学者和开发者。文章还提供了完整代码示例,帮助读者快速掌握K-Means聚类的核心应用。
本文提供了一份完整的Python脚本指南,帮助用户从Excel数据一键运行K-Means聚类并生成3D可视化图表。内容涵盖数据预处理、K-Means算法实现、三维可视化技巧及常见问题解决方案,特别针对业务场景中的常见陷阱提供实用建议。
本文以Iris数据集为例,详细介绍了使用Python和sklearn进行无监督学习的完整流程,包括数据探索、KMeans聚类和t-SNE可视化。通过实战代码和评估指标分析,帮助读者掌握聚类技术的核心要点和应用场景,特别适合数据科学初学者和从业者参考。
本文为业务分析师提供了一份从Excel数据处理到3D聚类图可视化的Python K-means实战指南。通过详细的代码示例和避坑技巧,帮助读者掌握数据预处理、聚类分析和三维可视化等关键步骤,实现客户分群的自动化分析流程。
本文详细介绍了如何使用Python和Matplotlib实现三维数据的K-Means聚类与可视化。从数据预处理、算法实现到三维可视化全流程,附完整代码,帮助读者快速掌握聚类分析技术,特别适合处理用户行为数据等多维数据集。
KMeans划分式聚类DBSCAN密度聚类。本文基于啤酒数据集,从零实现两大聚类案例,同时讲解:轮廓系数silhouette_score怎么评估聚类效果循环遍历K值,绘制折线图寻找最优聚类数为什么DBSCAN必须做数据标准化StandardScaler新手代码高频报错点逐行解析轮廓系数silhouette_score:通用聚类评估指标,越大聚类效果越好,所有无监督聚类都可以用它打分sklearn模
本文详细介绍了如何使用Python的Matplotlib库为K-Means聚类结果创建专业级的三维可视化。从数据预处理、维度选择到三维聚类实现,再到高级可视化技巧和交互式元素添加,全面提升了聚类结果的表现力和洞察力。通过三维可视化,可以更直观地展示数据的内在结构,帮助分析师发现高维空间中的有价值模式。
本文介绍了如何使用Python的Matplotlib库为K-means聚类结果创建3D可视化,突破传统二维图表的限制。通过电商用户数据的实战案例,详细讲解数据预处理、聚类建模和三维可视化技巧,帮助读者更直观地分析多维特征的空间关系,提升商业洞察力。
摘要:本文设计并实现了一个基于Python的涉军微博舆情分析系统,重点阐述了数据爬取实现过程。研究首先通过Chrome浏览器调试端口配置和WebDriver初始化,建立高效的数据采集环境。系统采用Selenium控制远程调试模式下的浏览器,避免重复启动以提升爬取效率。该技术方案为后续的舆情数据预处理、情感分析和可视化展示奠定了数据基础,对涉军舆情监测具有实践价值。(98字)
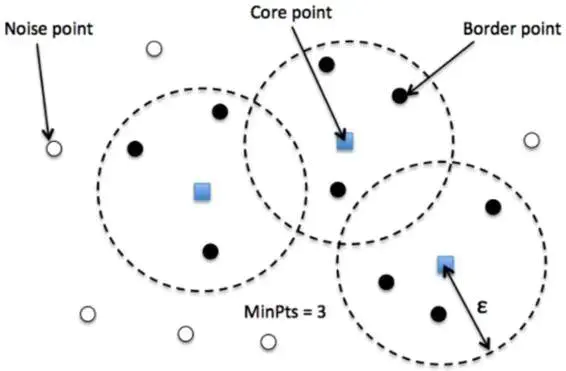
想直观看到核心点染色、向外扩张、噪声留灰的全过程,可以在「码路星球」看这套逐行代码高亮 + 动画的可视化讲解,完全免费,做任务还能得成长币。扫到一个核心点,它和邻域里的点一起被染上同一种颜色,一个新簇诞生;可视化用的数据是 28 个点:3 个密集簇 + 4 个离群噪声点,外加几个"靠簇但本身不够核心"的边界点,eps=42、minPts=3,过程清晰可复现。DBSCAN / 密度聚类 / 机器学习
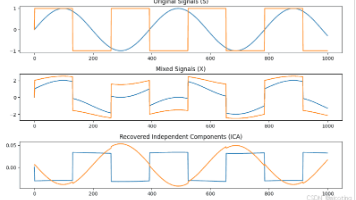
独立成分分析(ICA)是一种无监督降维方法,与PCA不同,ICA追求统计独立性而非相关性,能有效分离混合信号中的潜在独立成分。
【机器学习】DBSCAN密度聚类算法(理论 + 图解)
具体计算流程不详细写了,有很多大佬都提供了不错的学习做资料(个人的十大算法系列有kmeans,印象中有,读研的时候写的了)。这里为自己对比梳理与代码整理。聚类常用的是meanshift(均值漂移)与kmeans。效果对比暂时不放辣,后续更新。
空间转录组数据分析之CNV burden和CNV聚类(python版本)
从0入门机器学习,本篇分享几种最常用的聚类算法如k-means,参差聚类等等,包括其原理、聚类算法的评价指标,还有对各种距离公式(马氏、欧式、明氏、余弦距离、汉明距离等等)的计算。
根据聚类思想的不同,常见的聚类算法主要可以分为基于划分的方法、基于层次的方法以及基于密度的方法。
优先尝试简单算法:KMeans(大规模/凸簇)、DBSCAN(非凸/噪声);调参核心:KMeans用肘部法则/轮廓系数选K,DBSCAN调ɛ和MinPts;数据预处理:数值特征标准化,分类特征用K-Modes;评估:无标签用轮廓系数,有标签用ARI/AMI。聚类算法的选择需结合数据特性(类型、规模、分布)和业务需求,实战中建议多算法对比,通过评估指标确定最优方案。
K均值(K-Means)是一种经典的无监督学习聚类算法,其核心思想是通过迭代将数据划分为 K个簇,使得同一簇内的数据点尽可能相似,不同簇的数据点尽可能不同。它的本质是最小化簇内平方误差(Within-Cluster Sum of Squares, WCSS),即所有数据点到其所属簇中心的距离平方和。WCSSi1∑kx∈Ci∑∣∣x−μi∣∣2其中,Ci是第i个簇,μi是第i个簇的中心(
本文介绍了聚类算法的核心概念和应用。聚类算法是一种无监督学习方法,通过计算样本间相似度(如欧式距离)将数据划分为不同类别。重点讲解了K-means算法流程:随机初始化K个中心点,迭代计算样本到中心的距离并重新计算中心点,直到收敛。文章还介绍了三种评估指标:SSE误差平方和(通过"肘部法则"确定最佳K值)、轮廓系数(衡量簇内凝聚度和簇间分离度)和CH分数(综合考虑簇内距离和簇间距
聚类-DBSCAN(density base)
应用空间统计方法来识别那些不太可能由随机机会产生的聚类。它回答了一个关键问题:“观察到的空间集中是否具有统计学意义,还是可能由随机过程引起?”这种区分将需要采取行动的真实模式与浪费资源的虚假模式分离开来。Python 通过其空间统计库,提供了进行严谨热点分析的全面工具。公共卫生分析师用它来识别疾病暴发区,执法部门用它来锁定犯罪预防工作的目标,城市规划师用它来定位服务缺口,环境科学家用它来检测污染源
聚类
——聚类
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区














 DAMO开发者矩阵
DAMO开发者矩阵