




- @weixin_39355136
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
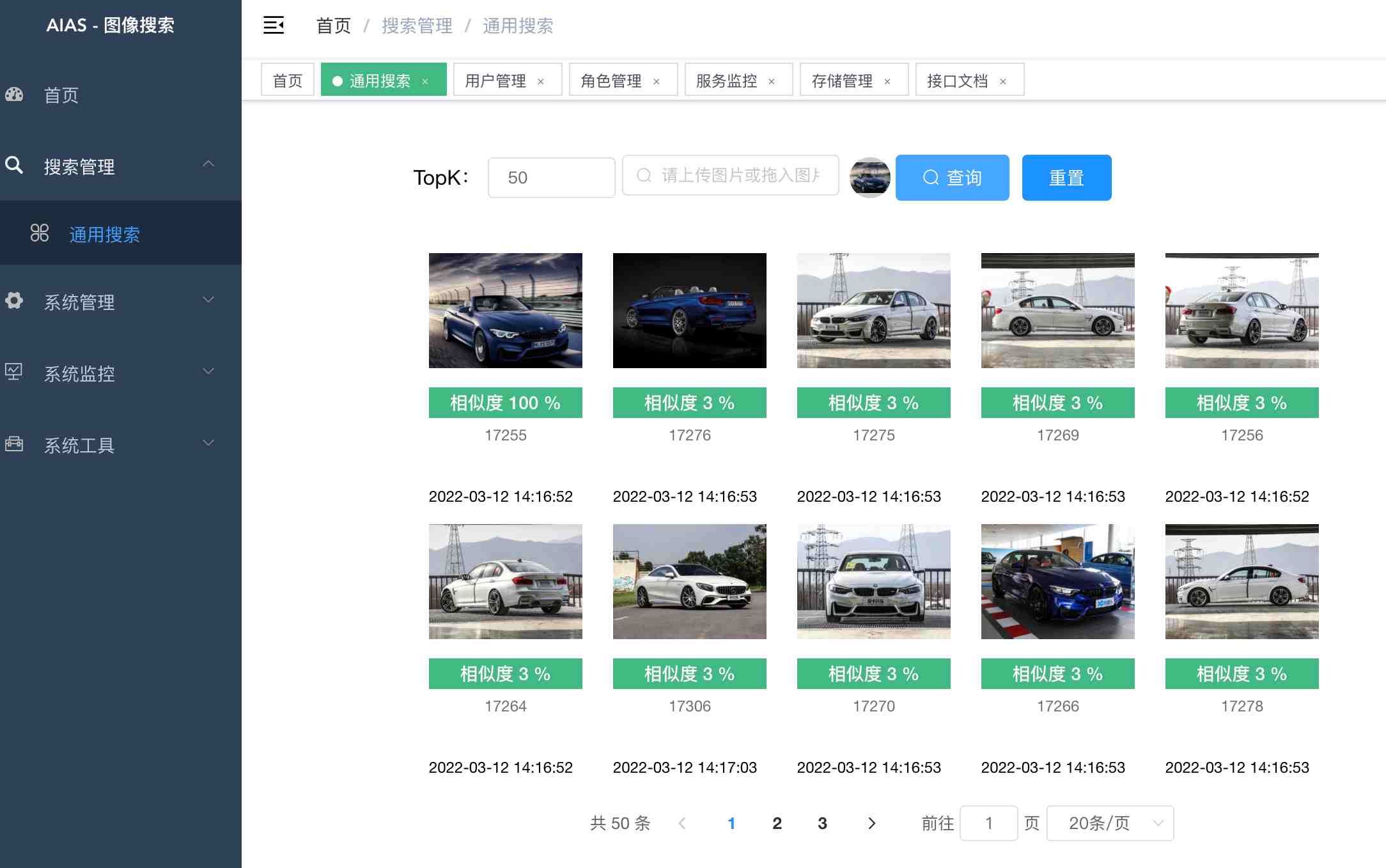
网站首页以图搜图产品主要特性底层使用特征向量相似度搜索单台服务器十亿级数据的毫秒级搜索近实时搜索,支持分布式部署随时对数据进行插入、删除、搜索、更新等操作支持在线用户管理与服务器性能监控,支持限制单用户登录系统功能搜索管理:提供通用图像搜索,人像搜索,图像信息查看存储管理:提供图像压缩包(zip格式)上传,人像特征提取,通用特征提取用户管理:提供用户的相关配置,新增用户后,默认密码为123456角
文本 - 情感分析SDK [中文]情感倾向分析(Sentiment Classification,简称Senta)针对带有主观描述的中文文本,可自动判断该文本的情感极性类别并给出相应的置信度,能够帮助企业理解用户消费习惯、分析热点话题和危机舆情监控,为企业提供有利的决策支持。SDK算法:SDK包含两个模型:SentaLstm - 该模型(约650M)基于一个LSTM结构,情感类型分为:消极(neg
一键抠图的原理通常基于计算机视觉和机器学习技术。它使用深度神经网络模型,通过训练大量的图像样本,学习如何识别和分离前景对象和背景。这些模型能够理解图像中的像素信息和上下文,并根据学习到的知识进行像素级别的分割。一键抠图是一种图像处理技术,旨在自动将图像中的前景对象从背景中分离出来。它可以帮助用户快速、准确地实现抠图效果,无需手动绘制边界或进行复杂的图像编辑操作。

运行例子 - FeatureExtractionExample。运行例子 - FeatureComparisonExample。提取图片特征值,并支持图片1:1特征比对,给出置信度。测试图片: 左右特征对比。

java 版的stable diffusion 图像生成
智慧工地检测SDK支持检测的类别:person (人体)head(没戴安全帽)helmet (戴安全帽)SDK功能工地安全检测,给出检测框和置信度。提供三个模型:小模型(yolov5s 29.7M)中模型(yolov5m 86.8M)大模型(yolov5l 190.8M)运行小模型例子 - Yolov5sExample测试图片效果(只显示安全帽检测,过滤了其它类别的显示,具体看代码)运行中模型例子
声纹识别所谓声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时使用的发声器官–舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。声纹识别(Voiceprint Recognition, VPR),也称为说话人识别(Speaker Recognition),有
语音活动检测可以运行在4种不同的模式。模式0非常严格,这意味着当VAD预测为语音时,音频片段是语音的概率更高。模式3非常激进,这意味着当VAD预测为语音时,音频是语音的概率较低。目的是从声音信号流里识别和消除长时间的静音期, 静音抑制可以节省宝贵的带宽资源,可以有利于减少用户感觉到的端到端的时延。VAD引擎需要8、16、32或48 KHz的采样率的单声道、16位PCM音频作为输入。输入应该是10、

java 版的stable diffusion 图像生成
声纹识别所谓声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时使用的发声器官–舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。声纹识别(Voiceprint Recognition, VPR),也称为说话人识别(Speaker Recognition),有