




- @Rookie_CEO
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
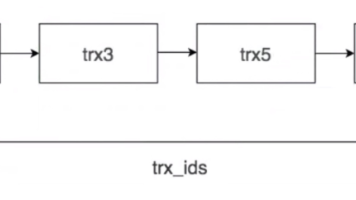
MVCC(多版本并发控制)是InnoDB实现高并发的核心技术,通过维护数据行的多个版本来实现读-写操作的非阻塞执行。其核心机制包括: 版本链:通过隐藏字段trx_id和roll_pointer构建数据修改历史链 ReadView:事务快照,包含creator_trx_id、活跃事务列表等,用于判断版本可见性 两种读操作:快照读(不加锁,读取历史版本)和当前读(加锁,读取最新版本) 在不同隔离级别下
1. 法律风险违反开源协议可能导致法律诉讼。例如,未遵守 GPL 的开源要求可能被起诉。2. 商业风险某些协议(如 GPL、AGPL)要求公开源代码,可能影响商业利益。使用宽松协议(如 MIT、BSD)可以降低商业风险。3. 专利风险某些协议(如 Apache 2.0)涉及专利授权,需注意专利条款。4. 声誉风险违反开源协议可能损害企业或开发者的声誉。

X-Pack 已经作为 Elastic 公司单独的产品线,提供安全性,警报,监视,报告,机器学习和许多其他功能,有着非常强大的功能。从6.3版本和 7.1 开始, X-Pack 默认包含在 Elasticsearch、Kibana 和 Logstash 中,所以无需再次安装,并且基础级安全永久免费,比如 用户登录权限校验等基础功能,当然也有付费的功能,但是我们用免费的就足够了。用户角色elasti

刚才启动测试环境下虚拟机上的oracle,启动过程没有报错,在我编译存储过程的时候报错如下:Thu Jul4 14:05:09 2013Errors in file /u01/app/oracle/admin/ora10g/bdump/ora10g_smon_3319.trc:ORA-00604: error occurred at recursive SQL level 1ORA-
前面我们详细梳理了OTP一次性密码,这里再看看双因素认证(2FA):2FA是结合两种不同的认证因素(如密码和OTP),增强安全性的身份验证方法。双因素认证,英文名称, 简称2FA。常规密码验证码使用2FA的主要目的是增强账户的安全性,提供额外的保护层,以防止未经授权的访问和潜在的安全威胁。降低了密码盗窃的风险弱密码尽管2FA并,但它是一种非常有效的方法,可以显著提高账户的安全性。通过多因素验证,即

一次性密码(OTP,One-Time Password)是一种用于身份验证的安全机制,通常用于提高用户账户的安全性。前面我们一步一步地分析一下OTP的工作原理。这种机制能有效防止重放攻击和钓鱼攻击,因为每个密码只使用一次且是短暂有效的。在这里我们再继续看看OTP的另一种方式RFC 6238(TOTP)。
为了确保应用程序的安全性和保护用户数据的隐私,开发者需要使用一些必备的身份验证应用安全技术。身份验证(Authentication)是网络安全的核心组成部分,指的是确认用户或系统的身份是否有效的过程。通过身份验证,可以确保只有授权用户才能访问敏感数据或系统资源。随着网络攻击手段的不断演进,传统的身份验证方式面临越来越多的挑战,因此多种身份验证机制相继出现,以应对日益复杂的安全威胁。

动态口令(OTP)有一个同名确不同翻译的前辈,一次性密码(OTP, One-Time Pad),也叫密电本,是一种应用于军事领域的谍报技术,即对通信信息使用预先约定的一次性密电本进行加密和解密,使用后的密电本部分丢弃不再使用,能够做到一次一密。可以做到一次一个动态口令,使用后作废,口令长度通常为6-8个数字,使用方便,与通常的静态口令认证方式类似,使用方便与系统集成好,因此OTP动态口令技术的应用
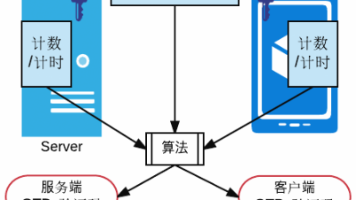
OTP生成方式:通常基于算法生成,包括TOTP和HOTP两种方式。 生成过程不依赖外部网络,具有更高的独立性。TOTP(基于时间的 OTP,计时使用):根据当前时间和共享密钥生成,基于RFC6238协议。HOTP(基于事件的 OTP,计次使用):根据计数器值和共享密钥生成,基于RFC4266 协议。
(1)首先我们要简单了解计网发展历史以及一些基本概念如因特网、网络服务提供者等的含义。因特网Internet:全球范围内的计算机网络的集合,它连接了数以亿计的设备,包括个人计算机、服务器、路由器、交换机、智能手机等,使它们可以相互通信和交换数据。网络服务提供者ISP(Internet Service Provider):通过物理方式(如光纤、DSL、电缆等)将用户设备连接到互联网,并提供连接用户到
