- @qq_41566819
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
特征预处理就是对数据进行集成、转换、规约等一系列处理,使之适合算法模型的过程。

拟合是指机器学习模型在训练的过程中,通过更新参数,使得模型不断契合可观测数据(训练集)的过程。
中文分词是指将汉字序列按照一定规则逐个切分为词序列的过程。在英文中,单词间以空格为自然分隔符,分词时自然以空格为单位进行切分,而中文分词则需要依靠技术和方法寻找类似英文中空格作用的分隔符。

对于模型的评价往往会使用损失函数和评价指标,两者的本质是一致的。一般情况下,损失函数应用于训练过程,而评价指标应用于测试过程。
KNN算法案例实现
支持向量机(Support Vector Machine,SVM)的基本思想是在N维数据找到N-1维的超平面(hyperplane)作为分类的决策边界。
特征降维是指减少特征个数,最终结果就是特征和特征之间不相关。由于特征矩阵过大,会导致计算量大、训练时间长,因此降低特征矩阵维度必不可少,特征降维是通过选取有代表性的特征,减少特征个数,得到一组不相关主变量的过程。
朴素贝叶斯算法或朴素贝叶斯分类器(Naive Bayes Classifier,NBC)发源于古典数学理论,是基于贝叶斯理论与特征条件独立假设的分类方法,通过单独考量每一特征被分类的条件概率作出分类预测。
在机器学习中,通常将数据集划分为训练集和测试集。训练集用于训练数据,生成机器学习模型;测试集用于评估学习模型的泛化性能和有效程度。
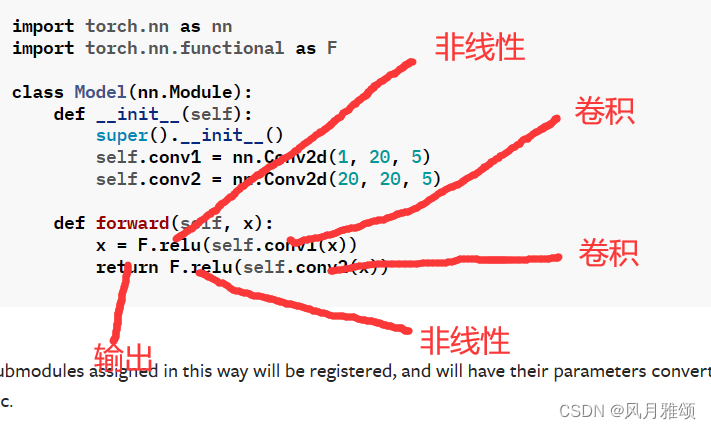
构造一个5*5的数据集,卷积核为3*3,卷积过程为,卷积核从图像的左侧开始,相对应的数据相乘在相加,最后输出。完成一次卷积后,若stride=1向右侧移动一个像素,继续卷积运算。当第一行完成后,向下移动一个像素,同时移动到图像最左侧,继续进行卷积运算。若padding=1,则在原始数据边缘增加一圈默认为0的像素,再进行卷积运算。想要运行该程序,需要添加pytorch。断点运行,以及一步运行。