登录社区云,与社区用户共同成长
邀请您加入社区
公共部门数据面临孤岛化、质量不一和系统陈旧等挑战,阻碍AI技术的有效应用。Elastic提出以数据网格(datamesh)和语义搜索为核心的新方法,通过理解查询意图而非关键词,在严格合规下实现跨部门数据整合。语义搜索结合生成式AI(GenAI)和检索增强生成(RAG)技术,为教育、医疗、交通和劳动力发展等领域提供精准洞察:如学生个性化学习、医生临床决策支持、实时交通调度及职位智能匹配。该方案支持离
一份基于对 685 名公共部门受访者调查的最新 IDC Spotlight 报告发现,72% 的受访者认为,将 AI 从试点扩展到生产环境 “非常困难” 或 “有些困难”。¹ 选择合适的模型只是挑战的一部分。政府机构还需要为 AI 做好数据准备。成功应用 AI 的政府机构正在构建一个受治理的检索层,通常称为下一代联邦知识访问,它能够将权威知识连接到 AI agents,同时保持数据主权、可审计性以
Unity 是数字孪生行业使用最广的游戏引擎,生态与人才储备深厚;但 Unity 6 及后续版本已不再向中国用户提供,国内由团结引擎承接,叠加授权费用与信创合规问题,越来越多政企项目开始评估国产自研路线。CIMPro孪大师作为全栈信创适配的国产零代码数字孪生平台,是这一波替代潮中的务实选项。
【摘要】生成式AI正在重新定义日志数据的价值,将其从被动的故障排查工具转变为主动的业务智能来源。传统日志分析存在碎片化、缺乏上下文等问题,而GenAI通过自然语言处理能力能够自主解析日志,关联跨系统信号,识别异常模式并生成事件摘要。这种技术转变使日志成为连接系统行为与业务影响的关键纽带,能够提前预警客户体验问题,保护收入来源,并将技术指标与业务成果直接关联。现代日志分析工具需要具备GenAI集成、
2026 年人工智能与智慧城市国际学术会议(IC-AISC 2026)将于 2026 年 8 月 28-30 日在上海举办。所有的投稿,都必须经过2-3位组委会专家审稿,经过严格的审稿之后,最终所录用的论文将被ACM ICPS出版论文集(ISBN号:979-8-4007-2267-7),见刊后由出版社提交至 EI Compendex和Scopus数据库检索。目前该出版社见刊检索稳定。
先说一下自己的个人情况,23届应届生,通过校招进入到了蘑菇街,然后一待就待了差不多2年多的时间,可惜的是今年4月份受转型影响遇到了大裁员,而我也是其中一员。好在早有预感,提前做了准备,之前一直想去字节跳动,年前就已经在做准备了,这场持久战拉得很长,也最终以7个月的时间取得胜利。在踏入字节跳动,办理入职手续的那一天,作为一个男子汉,确实是落泪了。特分享一波我的真实经历,共勉。
description: "通用文本摘要,输出 3 条 bullet points"text: "string (required) - 待摘要文本"模板化:Jinja2 分离逻辑与文本版本化:Git + manifest.yaml = 可追溯可测试:渲染后本地验证,不需调 LLM可度量:A/B 测试 + 指标收集 = 数据驱动决策。
当前文档解析技术正从单纯文本提取转向为AI Agent提供结构化数据,强调表格、公式、图表等元素的精准还原。传统RAG系统将PDF压平为段落会导致表格信息失真,影响后续检索、计算和工具调用。MinerU等工具通过表格优先的解析策略(如精准OCR、版面还原、多格式输出)为Agent提供可信的结构化输入,尤其在科研和企业场景中,表格的二维关系(行列、单位、页码等)是核心数据对象。文档入库需分层验收,重
科研Agent工具理解的关键:Sciverse的meta-catalog解决方案 当前Agent研究的热点已从"模型回答能力"转向"系统稳定调用工具"的问题。在科研场景中,这一挑战尤为突出:Agent若不了解数据库字段结构,容易产生错误的参数猜测。Sciverse平台通过分层设计解决了这一问题,其核心创新在于meta-catalog接口,它使Agent能够动态发现可用字段和筛选条件,避免了"字段幻
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。Elasticsearch的应用场景一个线上商城系统,用户需要搜索商...
练——其实练什么语言、什么形式的口语都可以。ChatGPT作为一款,自然可以用于对练口语——只要你的输入和它的输出都变换为语音的形式即可。
记录elasticsearch-analysis-dynamic-synonym从8.7.0升级到8.15.0所遇到的问题一、问题伊始今天打算用elasticsearch最新版本来学点东西,发现安装es插件就遇到了许多问题,于是便通过此篇博客来记录问题的整个过程。去年我学习用的elasticsearch版本为8.7....
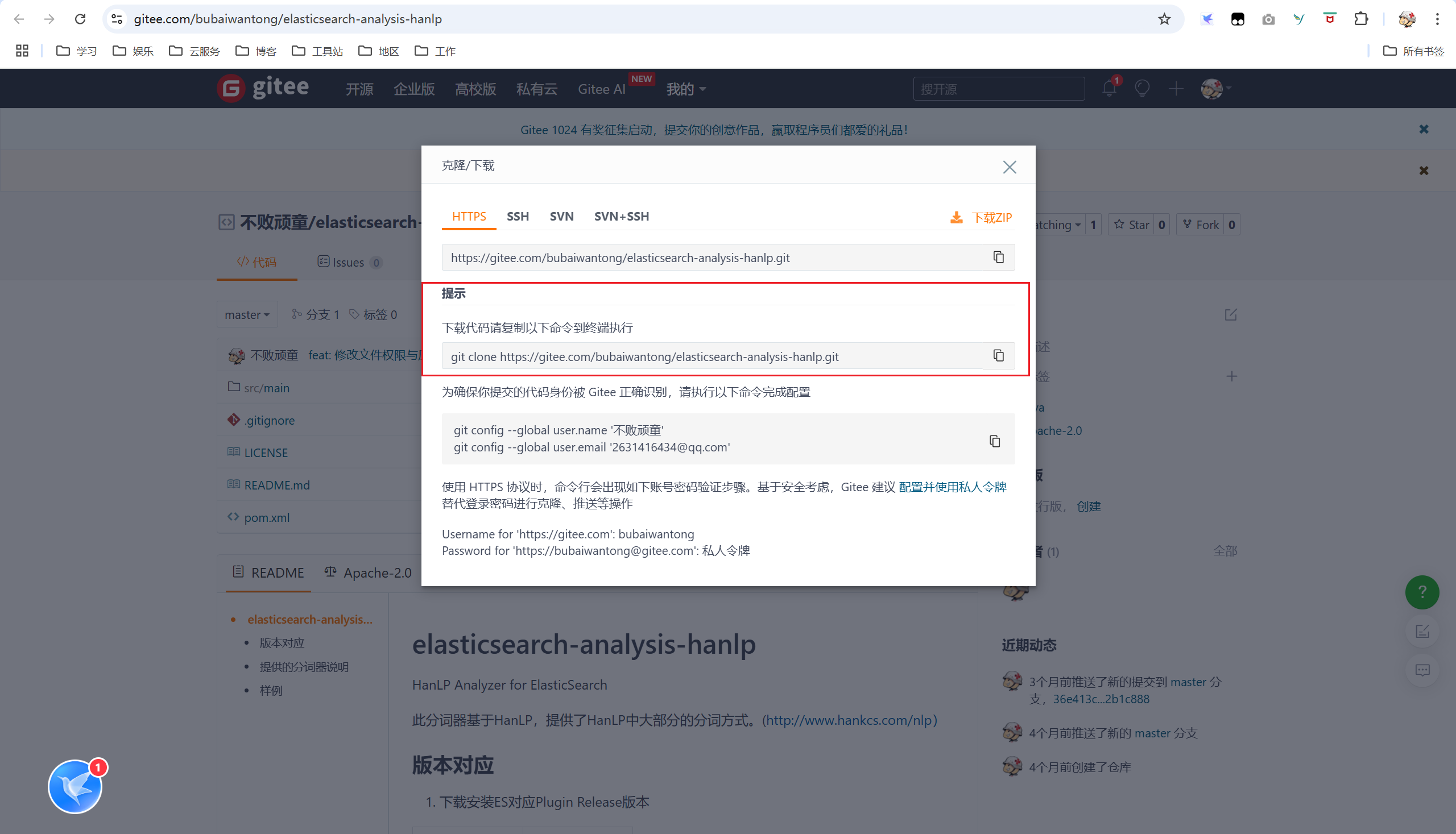
代码地址:https://gitee.com/bubaiwantong/elasticsearch-analysis-hanlp。
默认ES是没有设置用户认证访问的,所以每次访问时,直接调相关API就能查询和写入数据。现在做一个认证,只有通过认证的用户才能访问和操作ES。
Win10 安装单机版ES(elasticsearch),整合IK分词器和安装Kibana
本指南详细介绍了将 Sphinx 文档部署到 GitHub Pages 的两种方法:手动部署和通过 GitHub Actions 自动部署。内容包括项目结构准备、Sphinx 配置检查、HTML 文档生成,以及具体的部署步骤。手动部署部分讲解了如何推送 HTML 文件到 gh-pages 分支并配置 GitHub Pages 设置。自动部署部分则详细说明了如何创建 GitHub Actions 工
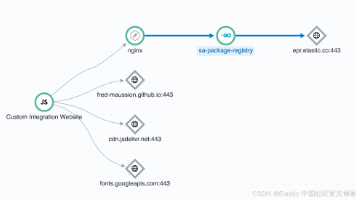
摘要:本文介绍了如何通过OpenTelemetry为Nginx实现端到端分布式追踪,解决现代架构中入口层监控缺失的问题。文章详细说明了在Debian系统上安装Nginx OpenTelemetry模块的步骤,包括全局配置和站点配置方法,以及如何将追踪数据发送到Elastic APM。通过这种集成,可以获得完整的请求链路追踪、精确的延迟分析、清晰的错误诊断以及准确的服务拓扑图,从而提升系统可观测性。
全文检索
——全文检索
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AtomGit AI 社区
AtomGit AI 社区

 智能体开发者社区
智能体开发者社区


 EazyDevelop社区
EazyDevelop社区


 AI编程社区
AI编程社区


 AI Agent技术社区
AI Agent技术社区




 MCP技术社区
MCP技术社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区