登录社区云,与社区用户共同成长
邀请您加入社区
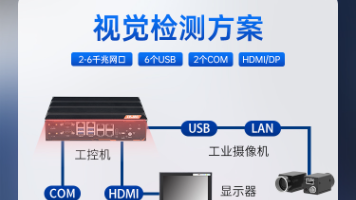
摘要: 苏州联控信息科技有限公司推出基于LionconitEMC-C007工业嵌入式工控机的全自动加油机器人控制系统解决方案。该方案针对行业痛点,如长期无人值守运行、多设备连接、复杂供电环境及空间限制,提供高稳定性、宽压输入(12V~28V)、丰富工业接口及紧凑型设计。EMC-C007搭载Intel® Elkhart Lake处理器,支持PLC通讯、数据采集及设备联网,助力实现车辆识别、精准加油、
让阵列型产品(像 miniLED)能做分区检测、精准定位故障点;
学生在这里学习机器人编程、手眼标定、视觉定位引导、复杂轨迹规划与系统联调——这是"视觉+执行"的闭环,也是智能装备产线上最常见的应用形态。工业视觉系统运维员、机器视觉应用工程师、AI机器视觉工程师、工业机器人系统集成工程师、智能装备调试工程师、3D视觉应用工程师、质量检测工程师。关键是配套20种来自真实工厂的案例:汽车螺栓头部裂纹检测、手机壳表面划痕检测、药品泡罩包装缺粒检测、PCB缺陷检测、轴承
摘要: TVA系统凭借高精度、实时性和抗干扰能力,正成为航空航天零部件检测的关键技术。该系统覆盖加工、装配、热处理及成品检测全流程,通过多视角扫描、深度学习模型和激光融合技术,实现微小缺陷识别(≥0.1mm裂纹)、超高精度测量(±0.001mm)及复杂结构三维重建,满足AS9100等行业严苛标准。典型案例显示,其检测效率提升90%以上,漏检率低于0.03%。未来,TVA系统将结合数字孪生与多技术融
《手工特征工程的困境与AI视觉的突破》一文对比了传统视觉检测与AI视觉智能体(TVA)的技术差异。传统方法依赖工程师手工设计特征提取器,通过数学公式编码视觉知识,存在参数脆弱、适应性差等缺陷。而TVA采用端到端深度学习,直接从数据中学习抽象特征,实现了从"人工调参"到"数据驱动"的范式转变。这种基于神经网络的表征学习不仅能捕捉人类难以描述的细微特征,还具备强
港口皮带运输面临跑偏、撕裂等隐患,人工巡检漏检率高且风险大。AI视觉检测与自动纠偏技术通过智能分析实现24小时精准监控(识别精度2mm),并自动调节皮带位置(响应时间≤1秒),将跑偏控制在5mm内。镇江港应用该技术后,皮带磨损率下降80%,年节省成本超200万元。技术落地需注重检测与纠偏协同适配,针对不同工况优化算法与执行机构参数。该方案有效解决了港口皮带运维中人工管控滞后、隐患预警不及时等核心痛
工业视觉检测技术正推动制造业智能化转型,通过"感知-分析-决策"闭环实现精准检测。系统由工业相机、图像处理单元和执行机构组成,采用传统算法与深度学习双轨并行,在电子、医药、汽车等领域实现微米级检测。该技术具有精度高、速度快、稳定性强等优势,未来将向3D视觉、多模态感知和少样本学习方向发展,成为智能制造的核心引擎和工业数据入口。
本文介绍了一种基于3D视觉与机器人协同的智能拆垛方案,针对传统人工拆垛效率低、成本高、安全隐患大等问题。系统采用Epic Eye D-L 3D工业相机和深度学习算法,实现±5mm高精度定位、6秒/袋的拆垛节拍,支持多种袋型与垛型的柔性适配。
港口船舶盲区问题长期困扰作业安全与效率。传统监控存在视野局限,人工巡检易受环境制约。AI视觉检测技术通过智能摄像头网络和实时分析算法,实现了对船舶轮廓、人员位置等关键信息的自动识别。系统采用目标检测和图像分割技术,结合边缘计算降低延迟,有效覆盖传统盲区。实际应用中,该系统能实时监测泊位间距、危险区域闯入等情况,显著提升安全预警能力。虽然极端天气下性能会受影响,但通过与雷达、AIS等传感器数据融合,
在全球人工智能浪潮的推动下,人工智能、机器视觉与控制领域正以前所未有的速度融合创新。2026人工智能、机器视觉与控制国际学术会议(AIMVC 2026)将于2026年6月5-7日在中国·鞍山举行。会议旨在汇聚全球学术界与产业界的专家学者,围绕智能理论、视觉感知、控制决策等前沿议题展开深入交流,构建高水平的国际学术平台。我们诚邀各国学者、工程师与产业代表踊跃参会,分享洞见,共同推动领域发展与产业升级
人社部预测,智能制造领域人才缺口450万。更关键的一个数据是:72%的企业认为应届生需要6到12个月培训才能胜任实际工作。院校的目标不是把12个月压缩成0,而是把这12个月的起跑线,从毕业之后挪到在校期间。具身智能的赛道刚刚鸣枪。先培养出"懂视觉的人",比先造出"更智能的机器"更紧迫。维视教育 · 专注AI+视觉实验室建设500+院校的选择 · 20年产教融合实践教育专线:400-040-0860
摘要:本文针对YOLOv8模型在稻田害虫识别中的不足,提出三阶段改进方案:1)采用C2f-Ghost-DynamicConv模块降低参数量;2)用BiFPN替换PANet增强多尺度特征融合;3)嵌入SE通道注意力机制优化特征提取。实验表明改进后模型mAP达97.9%,关键指标显著提升,满足无人机巡检实时需求。研究获国家自然科学基金等项目支持,成果发表于《人工智能与机器人研究》(DOI:10.126
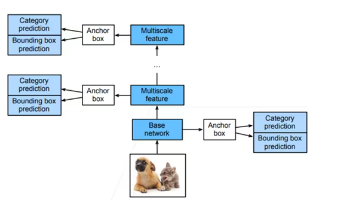
SSD(Single Shot MultiBox Detector)是一种高效的单阶段目标检测算法,通过单次前向传播同时预测目标类别和位置。其核心创新包括:1)基于多尺度特征图进行检测,利用不同层级特征识别不同尺寸目标;2)采用密集先验框(Anchor Boxes)机制,预设多种尺度和宽高比的候选框;3)将VGG16改造为全卷积网络,添加额外卷积层生成多尺度特征。相比两阶段检测器(如Faster
工业视觉检测系统正重塑制造业质量控制流程。该系统通过高清相机和AI算法替代人工检测,实现毫秒级缺陷识别,准确率随数据积累持续提升。其优势包括24小时高效运作、降低人力成本、实时异常反馈和预防性质量控制。系统生成的质量数据可与企业管理软件对接,为工艺优化提供依据,推动制造业向数字化、智能化转型。这一技术革新不仅提升检测效率,更实现了从制造到智造的理念转变。
无人机电力巡检|电力设施缺陷识别|智慧电网AI视觉检测数据集10092期
通过3D工业相机采集点云数据,结合AI算法精准识别,实现±1mm识别精度和±2mm抓取精度
SAM 3 ONNX TensorRT 导出
•视频跟踪与记忆更新(后续帧用):memory encoder:把上一帧生成的掩码和图像特征,编码成“记忆特征”,存起来。memory attention:在下一帧处理时,从 memory bank 里调取历史记忆,和当前帧的图像特征做注意力计算,从而知道 “这一帧里哪个是我之前跟踪的目标”。•“提示 - 掩码” 生成阶段(首帧用):prompt encoder:接收用户给的 “提示” ,把这些提
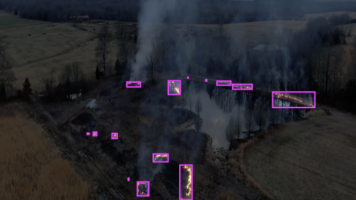
本文分享无人机森林野火专用检测数据集,配套 YOLO 训练、推理、预警全流程工程代码,快速构建全天候智能森林防火系统。
文章摘要:智能知识终端通过AI技术解决信息过载难题,实现高效知识管理。它打破文档格式壁垒,支持多元文件智能检索与语义理解;通过开放协议连接各类业务系统,实现"一个入口"的全链路服务;提供零代码配置,让用户快速搭建专属AI助手。这种新型知识管理模式已在多行业落地,显著提升信息获取效率,推动知识驱动决策的新型工作方式。
摘要:纺织质检面临人工检测效率低、标准不一及传统算法适应性差等痛点。视觉AI智能相机采用双算法融合方案,结合传统视觉技术精确测量标准化参数,利用AI深度学习识别各类不规则瑕疵,可适配不同材质面料及复杂工况。该系统实现24小时自动化检测,统一质检标准,显著提升检测效率和准确性,有效解决纺织行业漏检、误检难题,保障面料及成品布料的出厂品质。(149字)
摘要:视觉科技推出AI智能相机,集成了AI与传统视觉算法,实现单机完成图像采集、分析及输出,简化了柔性振动盘上料系统架构。该相机通过深度学习快速识别物料姿态,精准引导机器人抓取,并对不合格物料自动循环检测,解决高反光、微型工件等识别难题。产品覆盖工业检测全流程,支持定制,兼具稳定性与性价比。(149字)
视觉检测
——视觉检测
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵




 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区






 AI编程社区
AI编程社区













 AI Agent技术社区
AI Agent技术社区


