




- @cybersnow
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
防御前置:在文件加密修改发生前拦截风险,区别于杀毒软件事后补救;低误判:依托操作行为判断而非文件内容,办公软件、自定义二进制程序、压缩工具不会被限制;兼顾自由与安全:不剥夺用户批量加密隐私文件的需求,同时从底层断绝勒索病毒损毁资料的途径;通用性强:基于磁盘驱动底层改造,不针对某一款软件,攻击面更小,稳定性更强。
一类(你现在正在用的电脑,不用重装,直接清理蓝牙、Edge、UWP 垃圾、冗余缓存);,直接做超精简 LTSC 镜像)。全部开源、无捆绑、能自定义删减组件,支持单独关闭 / 卸载蓝牙、多媒体、Xbox、Edge 等你用不上的功能。
在v1 版本中我们讲述了 基础版的应用接下载我们做一个更复杂的的其他场景由于,V1查询字段必须 id接下来我们修改了了代码由于,V2只能查询1个字段接下来我们修改了了代码v3 由于没有 清空 操作,多选v4由于没有 读取全部 操作由于V5没有 必须传入4个参数,不满足参数就没法调用v6中没有加载默认数据,只能挨个加入由于V7不支持超级sql,多条件 or and 和 like 技术 V8加入。
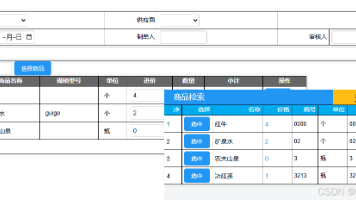
在 “未来之窗” 酒店管理系统的押金原路退回功能中,通过高效的数据库交互能力,确保了退款流程的速度与准确性。无论是批量查询待退款订单,还是通过事务保障退款状态一致性,该驱动都能适配酒店业务的高并发与数据严谨性需求。通过本文的部署步骤与代码示例,开发者可快速在 “未来之窗” 系统中集成该功能,实现从 “订单查询→退款执行→状态同步” 的全流程自动化,最终提升酒店用户的退房体验与资金安全感。

从上述场景可见,高级查询函数绝非 “锦上添花”,而是企业级系统应对复杂业务的 “刚需基建”。它如同 “仙盟创梦数据太虚” 中的 “通天眼”,让系统能根据业务变化灵活调整查询逻辑,既减少了开发者反复修改代码的成本,又赋予了用户自主挖掘数据价值的能力。在数据驱动决策的时代,这种 “灵活应变” 的查询能力,正是企业提升运营效率、优化客户体验的核心竞争力。
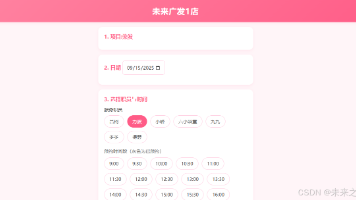
未来之窗仙盟创梦数据太虚” 是一个基于浏览器的前端数据管理类,主要用于实现数据的存储、加载、新增、更新、删除、查询等操作,支持基础条件查询与类 SQL 风格的高级查询,适用于前端轻量级数据管理场景(如小游戏、小型 Web 应用的本地数据存储)。

从东方仙盟筑基期看 JavaScript 动态生成图片技术在东方仙盟的修仙体系中,筑基期是修仙者稳固根基、开启超凡之路的重要阶段。这与初学者学习 JavaScript 动态生成图片技术有着奇妙的相似之处。让我们结合给定的代码,一同探索这其中的奥秘。
【代码】操作系统应用开发(二十八)rust OIDC服务器—东方仙盟筑基期。
无法拉去通讯录和添加地址无法登录是sll到期更新证书即可。
一、开发环境由于公安部提供的读卡和解码库都是32位DLL,所以请使用32为JDK进行对接开发。DLL调用使用JNA方式。本demo支持usb驱动型、免驱型以及串口型读卡器。二、目录文件说明开发包文件如上图所示,其中:img正反面背景照片读卡函数封装照片解码授权文件,请将此文件拷贝到C盘根目录下,否则不能解码照片。sdtapi.dll二代证读卡库二代证读卡库二代证读卡库WltRs.dll照片解码库三