登录社区云,与社区用户共同成长
邀请您加入社区
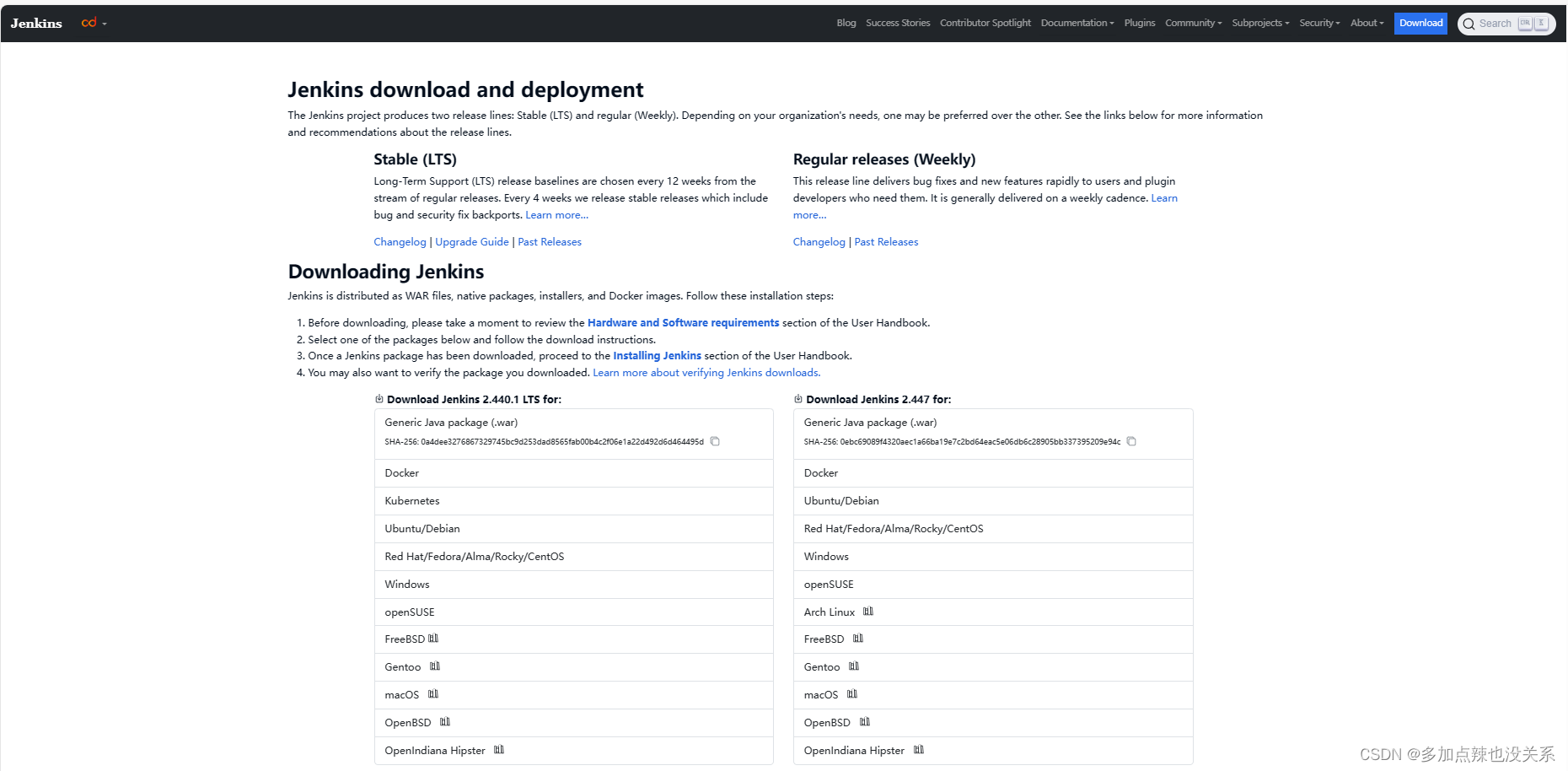
一、Windows操作系统下,Jmeter+Ant+Jenkins实现接口自动化测试1、前提条件windows系统下,已安装了jmeter、ant、jenkins(已安装jdk、tomcat)2.jenkins在windows系统下的安装##########################################前提:安装了jdk、tomcat2.1 jdk下载...
由于windows环境,反弹shell不方便,试一下远程下载命令,这里面可以用powershell执行下载命令,从上面我们知道的web绝对路径,下载到根目录下。应该是环境原因连接不了webshell,试试windows环境下的反弹shell,因为目标主机可以执行下载命令,我们下载一个nc,访问存在,上传成功。查看”/dashboard/phpinfo.php”,为phpinfo页面,发现为win1
摘要: 本文详细介绍了使用Docker搭建Jenkins服务的完整流程,包括镜像拉取、容器启动、目录挂载及权限配置。通过Jenkins实现持续集成,需安装Git、SSH、邮件通知、Allure报告等插件(支持在线/离线安装),并配置多节点环境以兼容不同操作系统任务。重点演示了新建项目、限制节点运行、Git仓库集成、定时任务设置及构建命令配置。最后,通过Allure展示测试报告,并利用Jenkins
【代码】数据分析 agent :ES和kibana 可视化工具链接。
一、ESP32 与 STM32 的使用场景简单说一下这两类芯片的定位:ESP32 集成 Wi-Fi/蓝牙,开发快、性价比高,是智能家居、物联网项目的热门选择;STM32 则以丰富的外设、强大的实时响应和工业级稳定性著称,在工业控制、汽车电子等领域占据主流。两者侧重不同,但都能用 PicoServer.Nano 快速提供 Web 能力。二、快速开始:在 ESP32 上跑一个 Web API”), “
I/O即输入输出。在现代操作系统中,输入输出是计算机完整功能必不可少的一部分。处理器负责各种计算任务,然后通过各种输入输出设备与外界进行交互。常见的输入输出设备包括键盘、鼠标、显示器、硬盘、网络适配器接口等。有了硬件设备,
若无对应日志格式的内置模块,也无法修改应用日志格式,可手动配置日志输入,9.x版本推荐使用filestream输入类型(替代旧版log输入,具备更好的性能与稳定性)。
Elasticsearch 支持多种数据类型,用于处理和存储不同格式的文档数据。主要的数据类型分为三大类:核心数据类型、复杂数据类型和特殊数据类型。
它提供了一个开放易用的平台,使软件项目能够实现持续集成。Jenkins的功能包括持续的软件版本发布和测试项目,以及监控外部调用执行的工作。。
graalvm,jenkins,java,jdk,maven
本文介绍了Jenkins自动化部署流程,重点描述了多仓库协作项目的构建过程。通过Pipeline脚本实现:1)拉取主仓库A和子仓库B、C;2)将B源码放入A/src目录;3)构建C项目并输出到A/public;4)安装主项目依赖并打包;5)根据参数化选择(dev/test/prod)部署到对应服务器。流程包含环境变量控制、多仓库协同处理、自动化构建和SSH远程部署等关键步骤,实现了从代码拉取到服务
不改变服务器jdk环境下,安装jenkins高版本。
为了避免员工自动注册,我们一般会禁止Gitlab的自动注册功能。最后,我们来讲解一下Gitlab的登录免密验证,配置完成后,可以使得我们的Gitlab自动执行Git命令而无需登录,对于脚本的编写以及其他项目(如Jenkins)的运用这一步是必须的。注意:在本次实战中,我们在认证设备上执行ssh-keygen命令时,注意设备的hostname,最好先改动设备的hostname,以防止最后出现问题。接
Jenkins官方提供了镜像:https://hub.docker.com/r/jenkins/jenkins。使用Deployment来部署这个镜像,会暴露两个端口:8080 Web访问端口,50000 Slave通。信端口,容器启动后Jenkins数据存储在/var/jenkins_home目录,所以需要将该目录使用。Jenkins是一款开源 CI&CD 系统,用于自动化各种任务,包括构建、测
除了使用jacoco.cli.jar导出并生成覆盖率报告外,还可以使用jacoco-maven-plugin,它是maven集成了jacoco的一款插件。在工程pom.xml里配置插件jacoco-maven-plugin。
jenkins中Transfers的设置
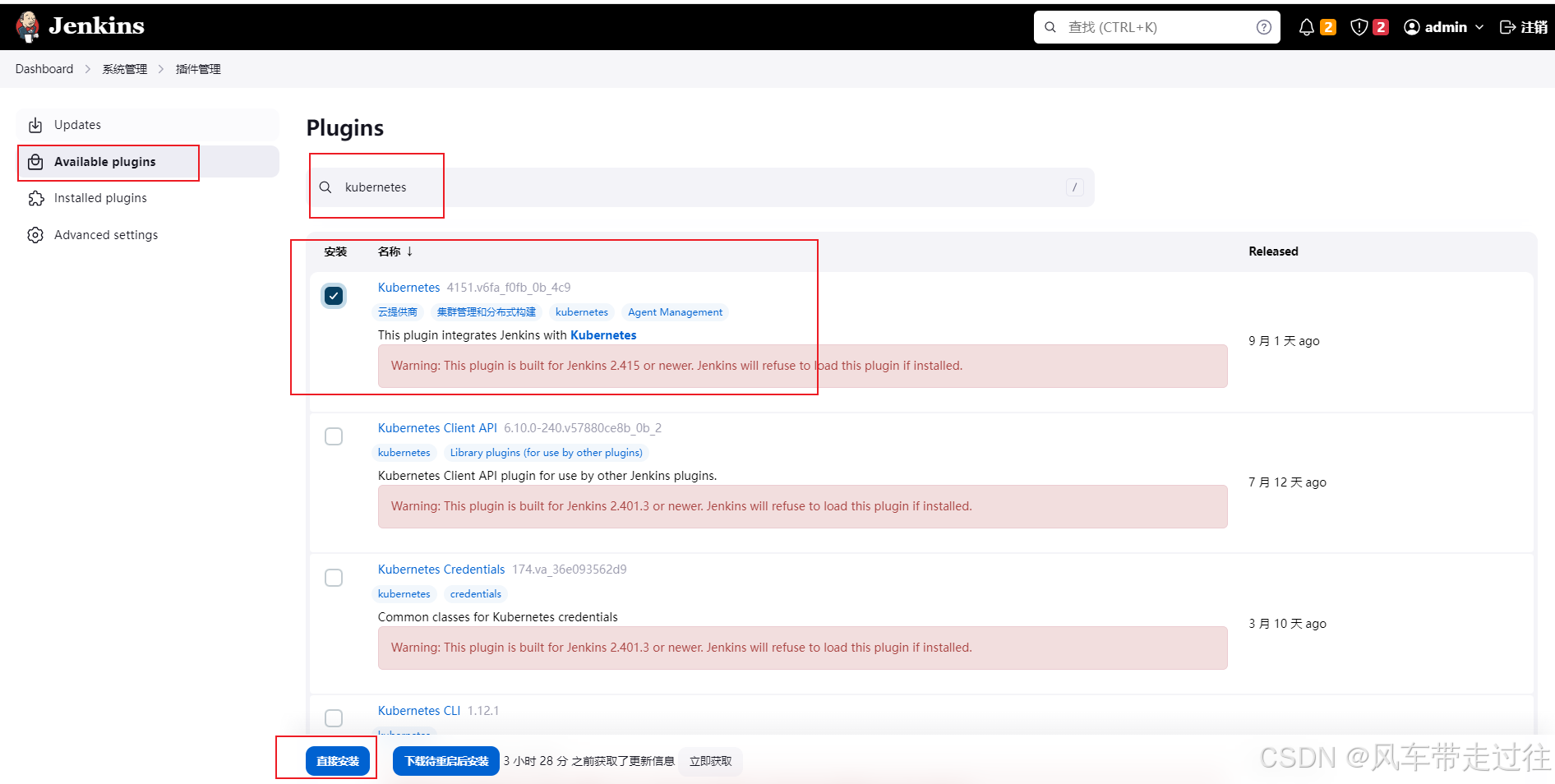
系统管理(Manage Jenkins)——插件管理(Manage Plugins)——点击可选插件(Auailable)——输入插件名称——勾选——直接安装(Install without restart)(3) 打开jenkins——系统管理——插件管理——高级——上传插件—— 选择credentials-binding.hpi——重启jenkins。(1) 去官网https://plugin
jenkins邮箱配置完成,测试发送成功,实际收不到邮件
以上是一个基本的安装流程及配置实现CICD的步骤,实际的操作可能会因环境和需求的不同而有所差异。请注意确认各组件的版本和依赖关系,以确保安装和配置的顺利进行。
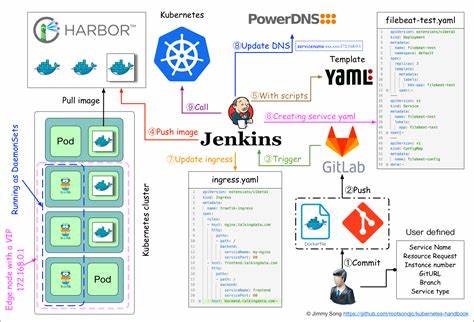
通过 Jenkins 将应用发布到 K8s 的过程可以通过Jenkins与Kubernetes的集成来实现,这一过程涉及多个步骤,包括配置Jenkins以连接Kubernetes集群、将应用打包成Docker镜像、将Docker镜像推送到容器仓库,以及最终通过Jenkins将应用部署到Kubernetes集群中。本章详细介绍如何通过 Jenkins 将应用发布到 K8s。
5.删除未挂载启动elasticsearch容器。4.删除未挂载启动kibana容器。1.以root用户身份进入容器。6.重新启动容器并挂载。1.手动创建挂在文件。
你可以在Jenkins中创建一个任务,该任务从Git仓库中拉取Jmeter的集合和测试脚本,然后使用Ant运行这些测试,并将结果输出到Jenkins的构建报告中。Ant构建文件,也叫build.xml,是一个基于XML的文件,它是由Apache Ant构建工具使用的。通过上述步骤,可以使用JMeter、Ant、Git和Jenkins进行接口自动化测试,提高测试效率和准确性,降低人工干预和错误率。在
elasticsearch进行ssl认证说明
jenkins构建阶段注入环境变量
4. 点击搜索的插件。
具体的代码实现,可以放在别的包里面。一些条件后 的块的内支持 post:部分 always,changed,failure,success,unstable,和 aborted。在 post 代码块区域,支持多种条件指令,这些指令有 always,changed,failure,success,unstable,和 aborted。这个 failure 条件一般来说,百分百会写到 Pipeline
持续监控 Elasticsearch 集群的性能指标(如 CPU、内存、磁盘 I/O、网络流量等),并根据监控结果进行相应的调优和调整,以确保系统的稳定运行。通过增加数据节点的方式扩展集群容量,确保可以处理更多的数据和更高的查询负载。在增加节点时,确保分片和副本的合理分布,避免热点节点的出现。随着数据量的增加,Elasticsearch 的部署策略也需要适当调整,以确保集群的可扩展性和高可用性。:
这个时候会有很多人说选择第一个去验证,这个不是不可以,但是在后续使用的时候会遇到很多问题,比如 git 命令权限的问题等等。安装Jenkins的时候到验证用户的时候如果选择当前登录的账户密码验证的时候会提示验证失败,此帐户没有以服务身份登录的权限,或者无法验证该帐户。中,输入“secpol.msc”后回车,即可打开“本地安全策略”。3.选择 添加用户或组,输入用户名点击检查名称可自动匹配对应的账户
你的Jenkins地址/createItem?name=新任务名&mode=copy&from=旧任务名。根据现有的任务,然后需要拷贝出一个副本,可以直接在网页中输入下面的链接。把“你的Jenkins地址”替换为 jenkins 的地址。“新任务名”替换为要起的新名称(后续可改)“旧任务名”替换为原任务的名称。
阅读下面文档前默认已经会Jenkins基本操作。1,Jenkins构建中心的全局工具处配置nodejs工具2,新建节点加入Jenkins中,3,创建前端自由风格job,(根据自身情况来,也可以在已有节点上部署)4,复制构建产物到指定项目路径登录Jenkins找到Global Tool Configuration选项这里我选择的是Install automatically(自动安装),可以在vers
");// 返回退出码 0 表示成功。
检查集群状态安装前端。
【代码】Jenkins-Pipeline java自动化打包部署到 k8s。
使用jenkins自动化合并svn代码。
Java8、java11、java17(JRE或者 JDK都可以),从 Jenkins2.357(于2022年6月28日发布)和2.361.1LTS版本开始,Jenkins需要Java11或更高版本。此外,从Jenkins2.355(2022年6月14日发布和Jenkins2.346,1LTS(2022年6月22日发布)开始,Jenkins支持Java 17。一般我们推荐使用包管理器来进行安装,我
本文介绍了在ACK或自建K8s集群上部署Jenkins实现自动化CI/CD的方案。部署过程包括:1) 使用500Gi NAS存储卷作为持久化存储;2) 配置RBAC权限控制,为Jenkins提供pod管理权限;3) 通过StatefulSet部署Jenkins主节点,使用特权模式并挂载containerd套接字;4) 设置NodePort服务暴露8080和50000端口;5) 提供查看初始管理员密
打开浏览器,访问 http://localhost:8080。方法 1: 使用 Homebrew 安装 Jenkins。根据提示完成初始配置。启动 Jenkins。访问 Jenkins。
改用powershell解决。
Jenkins+k8s+nexus+gitlab+harbor+sonarqube+springloud构建DevOps
LTS是长期支持的版本,是稳定的版本在Windows下Jenkinswarwartomcatmsi在下载安装包之前要先确定应该下载哪个版本的JenkinsJenkins的版本依赖于Java的版本,可在中进行查看如果你下载的Jenkins版本与本地Java不支持,那么Jenkins是无法安装成功的,比如说我电脑上JDK的版本是1.8.0_172,也就是Java 8,那么我只能安装2.346.1或者该
随之而来的问题是在新手入门页面安装插件全军覆没,都按照失败,网络,防火墙都排查过了没有问题,那应该就是jdk版本跟不上了,我之前安装的是jdk1.8。更新jenkins版本,关于jenkins与tomcat哪些版本可以匹配我在jenkins官方文档也没有找到相关的说明,我这里就用了比较新的版本。安装建议插件,如果有部分失败的插件先不要慌,等安装结束后,右下方有重试按钮,点击重新安装即可。这样的版本
本文不再描述和Jenkins的搭建方法。
新增try-catch机制,当失败时将终止后续步骤并跳过部署阶段。通过在编译阶段检测的退出码,可以确保构建失败时不会继续执行。
为了避免直接在 Jenkins 容器内部使用宿主机的 docker 命令,使用 Docker-in-Docker (DinD) 模式。这样可以在 Jenkins 容器内部运行一个独立的 Docker 守护进程,避免 glibc 版本不匹配的问题。挂载到 Jenkins 容器后,容器内的 glibc 版本低于 Docker 所需的版本,导致无法运行。Jenkins 启动时是以容器内的 jenkins
安装Jenkins插件,例如 Jenkins Plugin for WeChat Mini Program Builder(微信小程序构建器插件)。创建新的 Jenkins Pipeline,或者在现有的 Jenkins Pipeline 中启用 WeChat Mini Program Builder 插件。配置 Jenkins 构建步骤,添加微信小程序构建相关任务。测试您的微信小程序。1、安装
jenkins 发布项目,ssh连接远程服务器时报错:Host key verification failed.原因是生成的sshkey不是用的jenkins用户,所以。重新生成sshkey。
使用华为jenkins镜像解决插件下载的问题
Jenkins 是一个基于 Java 开发的开源持续集成与持续交付(CI/CD)工具。它允许开发者将代码的变更自动集成、构建、测试,并最终部署到目标环境中,大大减少了人工干预,提高了部署的准确性和效率。Jenkins 拥有丰富的插件生态系统,通过安装不同的插件,可以扩展其功能以适应各种不同的项目需求。无论是小型的个人项目还是大型的企业级应用开发,Jenkins 都能发挥重要作用。
摘要:本文介绍了利用Jenkins REST API实现多线程批量构建项目的方法。通过接口调用替代手动操作,可一次性构建数十个项目。核心流程包括:获取queueId→通过queueId查询buildNumber→获取BuildInfo以判定构建状态。文章提供了关键代码示例(Java),涵盖参数配置、状态轮询和线程池设置(4线程/120队列)。该方法显著提升批量构建效率,适用于需频繁部署的持续集成场
jenkins
——jenkins
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 深开鸿 技术专区
深开鸿 技术专区



 2048 AI社区
2048 AI社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI编程社区
AI编程社区