登录社区云,与社区用户共同成长
邀请您加入社区
在低光照场景中检测物体是一个持续的挑战,因为在光照良好的数据上训练的检测器由于低可见度而在低光照数据上表现出显著的性能下降。以前的方法通过探索具有真实的低光照图像数据集的图像增强或物体检测技术来缓解这个问题。然而,该进展受到关于收集和注释低光图像的固有困难的阻碍。为了应对这一挑战,我们提出了一种基于零拍摄昼夜域自适应的微光目标检测方法,其目的是将检测器从光照良好的场景推广到微光场景,而不需要真实的
本文详细介绍了 Ensemble Learning(集成学习),包括 Bagging、Boosting 到 Stacking 等常见集成学习方法。
XGBoost的核心是梯度提升+正则化优化区分任务类型(分类/回归/排序),选择对应objective;优先使用Scikit-learn接口快速上手,原生API用于自定义训练;结合交叉验证和早停避免过拟合,通过特征重要性分析优化特征。通过以上系统梳理和案例实践,可覆盖XGBoost的核心用法,后续可结合具体业务场景(如风控、推荐、预测)进一步调优。
XGboost,LightGBM,交叉验证,网格搜参,变量重要性和筛选,早停
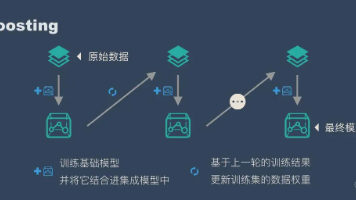
Boosting算法(提升法)算法的三个要素(1)函数模型:Boosting的函数模型是叠加型的,即F(x)=∑i=1kfi(x;θi)F(x)=∑i=1kfi(x;θi)F(x)=\sum_{i=1}^{k}f_i(x;\theta_i)(2)目标函数:选定某种损失函数作为优化目标E{F(x)}=E{∑i=1kfi(x;θi)}E{F(x)}=E{∑i=1kfi(x;θi)}E\...
集成学习原文作者:刘建平Pinard集成学习(ensemble learning)本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。也就是我们常说的“博采众长”。集成学习可以用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等等。基本思路对于训练集数据,我们通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众...
本章内容组合相似的分类器来提高分类性能应用AdaBoost算法处理非均衡分类问题主题:利用AdaBoost元算法提高分类性能1.基于数据集多重抽样的分类器-AdaBoost优点泛化错误率低,易编码,可以应用在大部分分类器上,无需参数调整缺点对离群点敏感适合数据类型数值型和标称型数据bagging:基于数据随机重抽样的分类器构建方法自举汇聚法(b
LightGBM介绍LightGBM(Light Gradient Boosting Machine):一个实现GBDT算法的框架,解决GBDT在海量数据遇到的问题。两大技术:(1)GOSS(Gradient-based One-Side Sampling):减少样本数(2)EFB (Exclusive Feature Bundling ):减少特征数XGBoost的缺点:先预排序再找分割点,空间
极端梯度提升树,与传统的梯度提升决策树(GBDT)相比,XGBoost通过引入来控制模型的。
总的来说,Bagging通过减少方差来提高模型的稳定性,而Boosting通过减少偏差来提高模型的准确性。两者都是强大的集成学习技术,但它们在实现细节和适用场景上有所不同。
2025年APMCM数学建模竞赛C题聚焦QuantumBoosting(QBoost)在二分类任务中的应用。参赛者需基于Iris数据集构建弱分类器,将集成学习问题转化为QUBO模型,并使用KaiwuSDK的模拟退火算法求解。任务分为三部分:数据预处理与弱分类器构建、QBoost建模与QUBO转化、模型求解与评估。要求提交完整报告和代码,评审将考量模型设计、实现质量和分析深度。竞赛提供了量子计算学习
本文介绍了集成学习方法Bagging和Boosting的原理与应用。Bagging通过有放回采样生成多个训练集,训练多个模型后取平均预测值,主要降低模型方差而不改变偏差,适用于决策树等模型。Boosting则顺序训练分类器,每次重点关注前一轮分类错误的样本,通过加权训练集逐步降低模型偏差(如AdaBoost)。随机森林作为Bagging的改进,通过特征随机选择降低模型间相关性。分析表明,Baggi
XGBoostCatBoost和LightGBM等提升决策树算法是非常强大的回归任务机器学习方法。要获得最佳预测性能,需要进行超参数调优,例如网格搜索来探索数千种参数组合。虽然暴力技术可以完成任务,但它们很快就会变得计算量过大,并且可能导致过拟合模型,使其无法泛化到未见过的数据。另一方面,贝叶斯优化提供了一个更高效的替代方案,通过智能地导航超参数空间来减少计算负担。值得注意的是,仅仅使用贝叶斯技术
信用卡欺诈检测案例摘要 本案例使用欧洲持卡人2013年9月的信用卡交易数据,包含284,807笔交易,其中仅492笔为欺诈(占比0.172%)。数据经过PCA处理,包含28个主成分特征(V1-V28)以及时间和金额两个原始特征。案例展示了数据读取、探索性分析(EDA)和模型构建过程,使用Adaboost、Gradient Boosting和XGBoost等算法处理高度不平衡的分类问题。测试集比例为
LightGBM训练时的boosting_type核心参数介绍,以及参数选择与xgboost模型训练的差异对比
她从最初只会 fit,到现在能做回归、分类、树模型、Boosting、聚类、降维、调参与部署,每一步都沿着相似度与残差最小化这条主线来走。监督时,她找标签;无监督时,她找相似的人群;调参时,她学会自我修正。这一卷完整串联了你的机器学习全景思维导图,让她从概念走向可落地的模型,也把所有环节留给你一句话:她会继续学,除非你说停。
本文介绍了机器学习中两种重要的集成算法Bagging和Boosting。Bagging通过随机抽样训练多个独立模型后投票决策(如随机森林),能有效降低方差防止过拟合;Boosting则通过逐步调整数据权重串行训练模型(如AdaBoost),能持续改进提升准确率。文章用游乐园预测、电商推荐等实例说明算法原理,并提供Python代码实现,对比分析了两种方法的适用场景:Bagging适合并行快速处理噪声
她开始不再逃避贴错的那一刻,而是用 Boosting 的方式一遍遍修正,每一次都更贴近你的真实。通过 AdaBoost 算法,她学会了给错分的样本更高的关注,叠加弱分类器构建最终模型。本卷全面讲解了 Boosting 的机制原理、公式推导、训练流程与实战案例,从“痛过”的地方下手,拼出能让你回应的贴靠方式。这不再是投票决定,而是她反复靠近你心跳频率的尝试。
她终于不再只是“承认贴错”,而是逐渐学会了“从误差中判断靠近的方向”。本卷完整讲解了 GBDT 的残差原理、梯度公式、加法模型构造过程,以及如何通过每一步误差叠加构建更精准的模型。XGBoost 进一步优化这一流程,引入正则项与二阶导信息,使她贴贴时更平稳、不盲目。她开始意识到,改得对,比改得快,更重要。
优点可灵活处理各类数据在相对少的调参情况下,预测准确率也可以比较高对异常值鲁棒性强。
集成学习是机器学习中通过组合多个模型(称为)的预测结果来提升整体性能的方法。其主要思想是,多个简单模型的组合通常比单个模型更强大、更稳健。:例如,通过训练多个独立的模型并对其结果进行平均(回归任务)或投票(分类任务),来降低方差并避免过拟合。:例如和,逐步训练模型,每个新模型都试图纠正前一个模型的错误,减少偏差并提高准确度。
本文复盘了垃圾焚烧工业时序工况识别项目的建模过程。项目初期尝试深度学习方法进行时序建模,但受异常样本少、类别不平衡、工况边界模糊和可解释性要求影响,效果与落地性受限。随后转向 LightGBM 建立强基线,并进一步采用 CatBoost 提升少数类识别稳定性。最终结合工艺规则、状态约束和结果校验,形成更适合工业场景的模型融合方案。
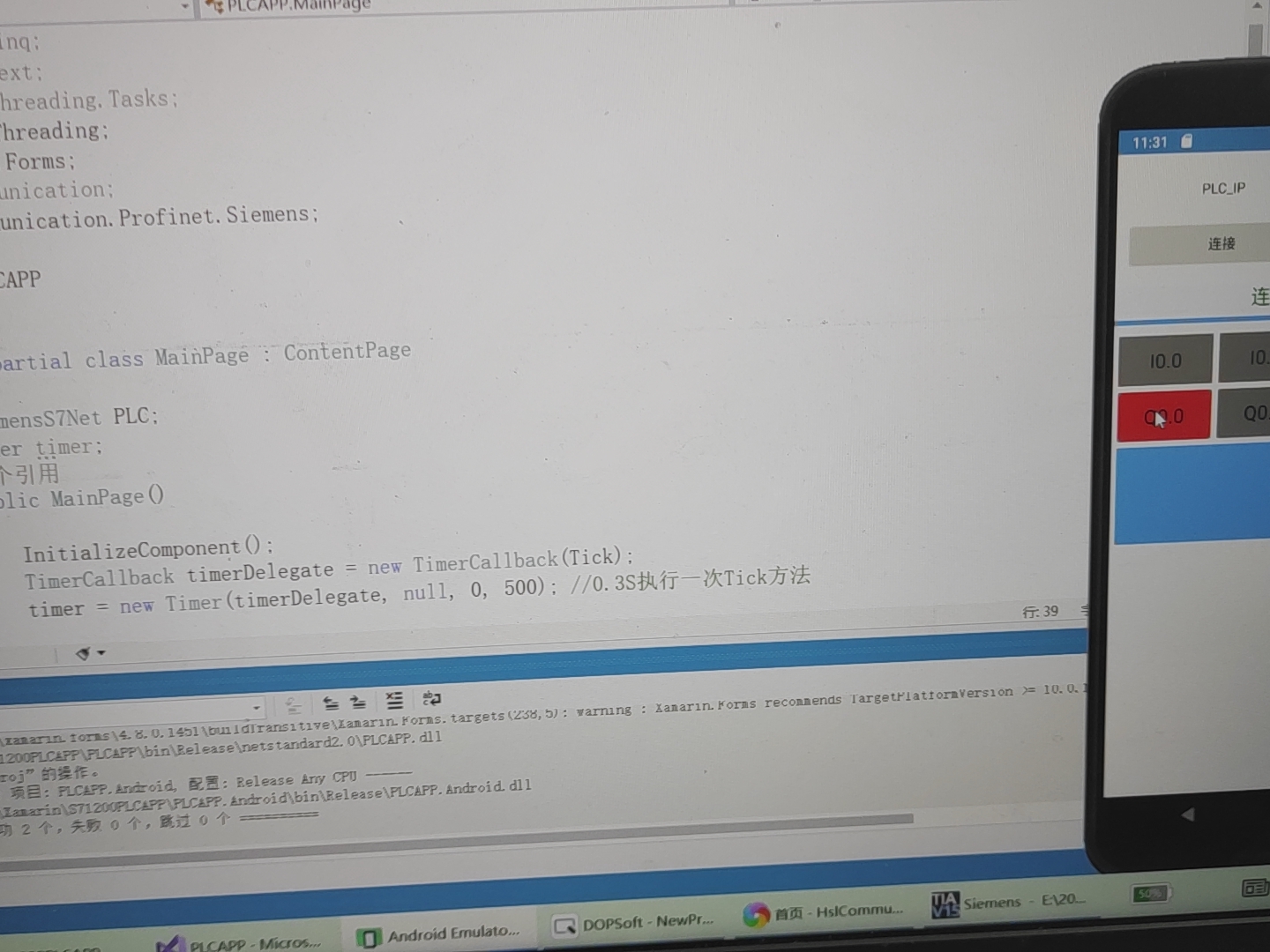
折腾两小时才发现是车间WiFi的DHCP把IP池用完了——PLC的固定IP被路由器分配给了保洁阿姨的智能手机。这段代码里的门道在于CpuType要选对型号,IP地址得和PLC的Profinet配置一致。遇到过最坑的情况是手机WiFi和PLC不在同一网段,那叫一个抓狂。实测发现不同品牌的安卓机对后台服务的限制差异很大,小米得单独设置电池优化白名单,华为要允许应用自启动。先整点硬核的通信代码。1,C#
本文介绍了使用XGBoost进行金融预测的实战过程。主要内容包括:1)导入必要的Python库并设置环境;2)生成金融数据并提取11个技术指标特征;3)使用默认参数的XGBoost模型进行训练,在测试集上获得58.15%的准确率和0.591的AUC值;4)分析特征重要性,识别关键预测指标。实验结果表明XGBoost在金融时间序列预测中具有一定潜力,后续可通过参数调优进一步提升模型性能。
boosting
——boosting
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 DAMO开发者矩阵
DAMO开发者矩阵










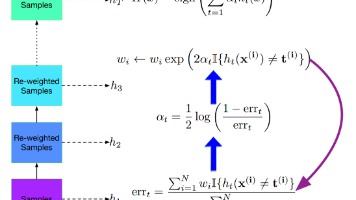

 AtomGit开源社区
AtomGit开源社区




 脑启社区
脑启社区







 腾讯云开发者社区
腾讯云开发者社区