登录社区云,与社区用户共同成长
邀请您加入社区
机器学习模型部署面临延迟敏感、内存受限和长期稳定运行等核心挑战,传统 Python 方案在 GC 暂停、解释器开销和内存泄漏等方面存在固有瓶颈。Rust 凭借零成本抽象、内存安全与细粒度控制能力,为回归与分类任务提供了高性能、低资源占用的原生实现路径。其技术价值体现在数值稳定性增强(如 SVD 截断、中心化预处理)、内存布局优化(列主序访问、缓冲池管理)及工程友好集成(ONNX 运行时、Polar
推测解码(Speculative Decoding)通过将“草稿生成”和“目标模型验证”解耦来加速大型语言模型(LLM)的推理过程。尽管近期的并行草稿生成器能够在一次前向传播中高效提出长token序列,但由于缺乏token之间的依赖建模,它们的接受率会迅速下降。此外,对这些扩展的token块进行不加区分的验证,会浪费批处理容量在高拒绝风险的token上,在高并发服务系统中严重降低吞吐量。
接口自动化难在资产管理与可持续回归。本文手把手演示 Swagger 导入、在线调试、AI 批量生用例、套件变量池、Token 授权与 cron 定时,附断言审查清单与 httpx 执行链路源码走读。
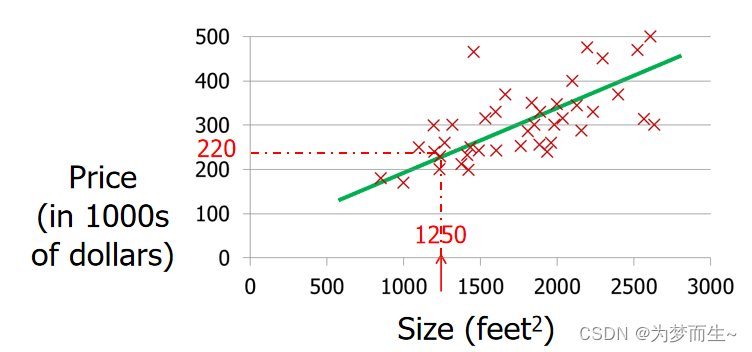
梯度下降算法的每次迭代受到学习率的影响,如果学习率α过小,则达到收敛所需的迭代次数会非常高;对没有进行特征缩放的训练集使用梯度下降法训练时,会导致迭代次数增加的情况。使用梯度下降法时,特征缩放有助于减少迭代次数,提升模型训练速度,使模型更快地收敛。在此前的单变量线性回归的基础之上增加更多的特征,构成一个多变量的回归模型,模型中的特征为(x1,x2,x3,...,xn)特征缩放:将不同特征的值量化到
线性回归是一种基础的回归方法,用于建立自变量与因变量之间的线性关系。通过最小化误差平方和来确定最佳拟合直线。
线性回归的算法:重点介绍梯度下降算法。评估模型好坏的方法:损失函数(lost function)最简单常见的损失函数:最小均方差(mse)公式如下:假如预测房价,特征值是面积,目标值是房价,需要拟合出一条线,计算出权重m和b步骤一:假设m=0,即y=b,则b为唯一的可调参数,利用最小均方差公式,计算出最小的最小均方差,在此过程中拟合出一个最优的参数b从上得知,“最优”的b值应该是mse=612对应
一元线性回归是一种统计分析方法,用于建立一个自变量和一个因变量之间的线性关系模型。在一元线性回归中,只有一个自变量(即解释变量)与一个因变量(即被解释变量)相关。
今天为大家精心整理了10大类最常用的免费机器学习数据集,无论你是要做分类还是回归任务,这里统统都有!为避免大家逐个寻找,我已将所有数据集整理打包(含国内镜像下载地址),关注后回复"数据集2024"即可获取。这里特别说明:部分大型数据集只提供下载指引,请遵循原作者的许可协议使用。对于中文实践,THUCNews中文文本分类数据集是更好的选择,包含74万篇新闻文本。欢迎在评论区分享交流!- 葡萄酒分类数
深度学习回归任务训练代码模版
2023年7月,复旦大学的学者在《BMC Psychiatry》(三区,IF=4.4)发表题为:Prevalence of depression and associationwith all-cause and cardiovascular mortalityamong individuals with type 2 diabetes:a cohort study based on NH...
1. 方差分析表1.1 单因素方差分析表误差来源平方和SSSSSS自由度dfdfdf均方MSMSMSFFF值PPP值FFF临界值Significance FSignificance \; FSignificanceF组间(因素影响)factor Afactor \; \bold AfactorASSASSASSAn−1n-1n−1MSA=SSAn−1MSA = \frac{SSA}{n-1}M
本周阅读了一篇关于使用GNN进行时间序列预测的论文。该论文模型的主要实现了在捕获时间序列不同尺度上的时间依赖关系外,还捕获了在不同尺度上变量之间的内部联系,例如空间上的依赖关系。同时还编写了论文提供的相关代码,了解了论文模型的定义。
定义softmax操作、softmax回归模型、交叉熵损失函数;计算准确率、训练模型、预测;以及一些python语法基础—eval(), model.train(), model.eval(), numel(),assert
关注并星标从此不迷路计算机视觉研究院公众号ID|ComputerVisionGzq学习群|扫码在主页获取加入方式计算机视觉研究院专栏作者:Edison_G少样本目标检测器通常在样本较多的基础类进行训练,然后在样本较少的新颖类上进行微调,其学习到的模型通常偏向于基础类,并且对新颖类样本的方差敏感。为了解决这个问题,腾讯优图实验室联合武汉大学提出了基于变分特征聚合的少样本目标检测模型 VFA,大幅刷新
树中的每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。后剪枝:先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点,能带来泛化性能的提升,则将该子树替换为叶节点。与分类树的主要区别在于,回归树的输出是连续的数值,而不是离散的类别标签。预剪枝:在决策树的生成过程中,对每个节点在划分
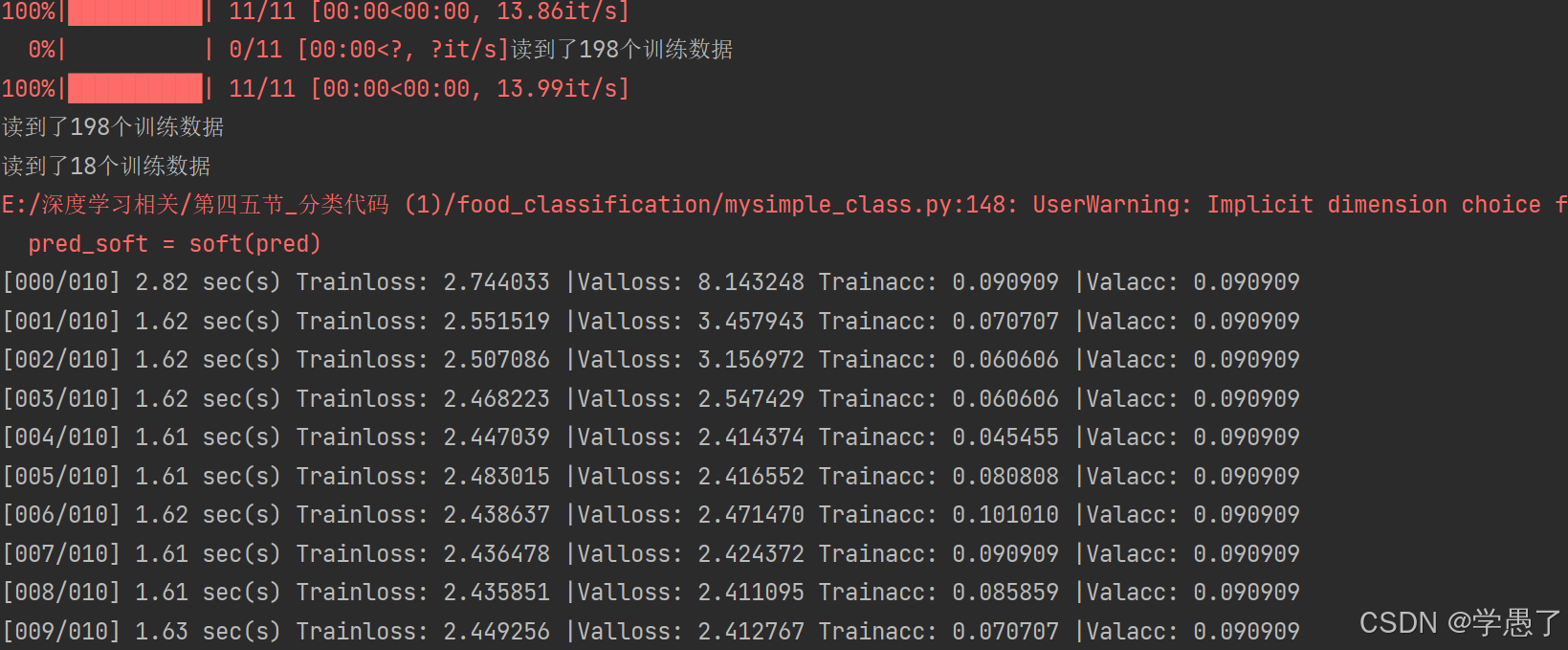
有11类食物,其中带标签的有28011张,无标签输出有6786张,验证集3011张,测试集有3347张。带标签的数据训练为监督学习,不带标签的数据训练为半监督学习。由上文可以训练出一个模型,用于食物分类。对于无标签的数据,可以待模型输入数据X,得到输出值predY概率超过0.99时,就将此数据打上此时的标签Y,并用作训练集。
Logistic回归:是统计学习中的经典分类方法,属于,所以也被称为对数几率回归。虽然是叫做回归,但其实这是一种,Logistic回归是一种线性分类器,针对的是线性可分问题。
本文深入讲解了核心优化算法——梯度下降,阐述了其更新规则、学习率α的关键作用,并将其应用于线性回归的参数求解。文章进一步将模型扩展至多维特征场景,引入了向量化表示以提升计算效率,并简要提及了正规方程。最后,重点介绍了一个必不可少的实践技巧——特征缩放,通过分析其如何改善代价函数等高线图的形态,解释了为何它能显著加速梯度下降的收敛速度,并总结了Z-score标准化等常用实现方法。
逻辑斯蒂回归本质上是一个算法,并不是像线性回归那样输出一个具体的值,而是输出该样本属于某个分类的例如手写的0~9的数据集,难道要拿到一张手写图,直接输出这是具体的几吗?并不是,而是输出它是0的概率P(0),它是1的概率P(1)……,最终选择概率最大的而逻辑斯蒂回归主要解决的是二分类,也就是只有两个分类。由于概率总和肯定等于1,所以我们只需要计算其中一个分类的概率即可。而逻辑斯蒂回归的核心在于将线性
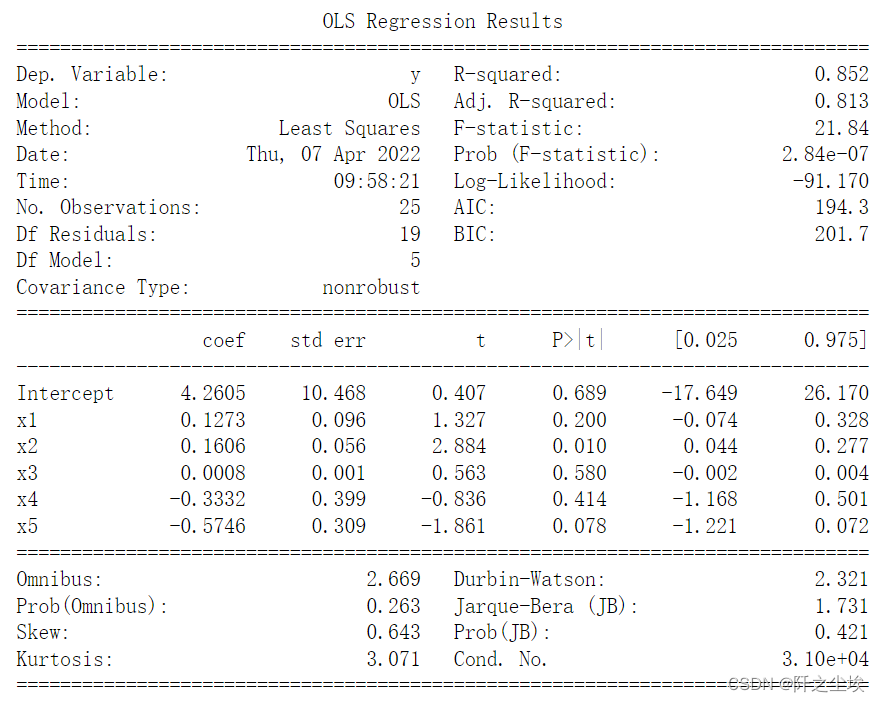
Python实现多元线性回归,残差检验,多重共线性判定,计算方差膨胀因子等
1.理解线性回归是什么?2.知道一元线性回归和多元线性回归的区别3.知道线性回归的应用场景数据介绍给定的这些特征,是专家们得出的影响房价的结果属性。我们此阶段不需要自己去探究特征是否有用,只需要使用这些特征。到后面量化很多特征需要我们自己去寻找。
回归
——回归
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区





 DAMO开发者矩阵
DAMO开发者矩阵