- @weixin_43424450
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
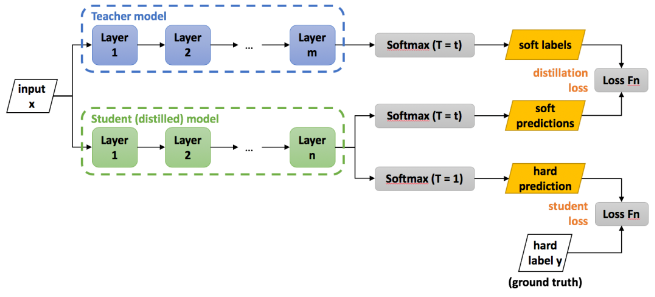
知识蒸馏是一种将知识从一个神经网络(教师)转移到另一个神经网络(学生)的技术,如需更深入地了解知识蒸馏,建议阅读[。这一过程有多种形式,可分为以下几类响应知识蒸馏: 使用 divergence 损失(即使用 KL 散度)训练输出类概率分布,使其与教师概率分布相匹配。特征知识蒸馏: 训练学生模型的内部特征,使其与教师模型的内部特征直接匹配(即:使用均方误差)。关系知识蒸馏: 训练教师模型中特征的相对
深度估计作为计算机视觉领域的核心基础任务,在自动驾驶、增强现实、机器人导航等领域具有重要应用价值。单目方法通过端到端深度学习架构,如多尺度特征融合、注意力机制,突破传统几何先验限制,结合监督或自监督范式缓解数据依赖问题,但受限于尺度模糊性。双目技术依托立体匹配的几何约束,通过代价体积构建与三维卷积网络实现亚像素级视差计算,在动态场景鲁棒性上表现突出。两类技术通过语义几何协同优化形成互补,推动算法从

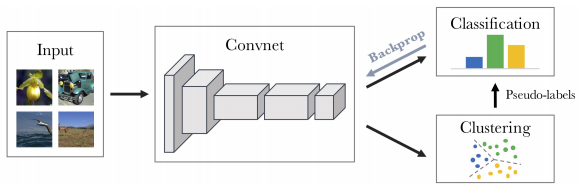
本文提出了DeepCluster,一种用于无监督视觉特征学习的深度聚类方法。该方法结合卷积神经网络(CNN)和标准聚类算法(如k-means),通过迭代进行特征聚类和网络参数更新,实现端到端的无监督训练。具体步骤包括:首先使用当前网络提取特征,通过k-means生成伪标签,然后利用这些伪标签更新网络参数。为避免平凡解,DeepCluster处理空簇和不平衡簇问题,如重新分配空簇中心、按簇大小加权损
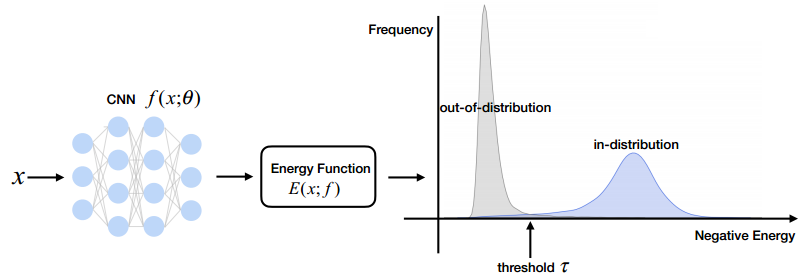
确定输入是否为非分布(OOD)是在开放世界中安全部署机器学习模型的基本构件。然而,以前依赖于softmax置信度得分的方法会受到OOD数据的过度自信后验分布的影响。我们提出了一个统一的框架,OOD检测,使用能量评分。我们表明,与使用softmax评分的传统方法相比,能量评分可以更好地区分分布内和分布外样本。与softmax置信度得分不同,能量得分理论上与输入的概率密度一致,并且不太容易受到过度自信
在开放世界中部署的现代神经网络经常与分布外(OOD)输入进行斗争,分布外(OOD)输入是指来自不同分布的样本,网络在训练期间没有接触过这些样本,因此不应该在测试时以高置信度进行预测。一个可靠的分类器不仅应该准确地分类已知的内部分布(ID)样本,而且还应该将任何OOD输入识别为“未知”。这提高了OOD检测的重要性,它确定输入是ID还是OOD,并允许模型在部署中采取预防措施。一种简单的解决方案使用最大
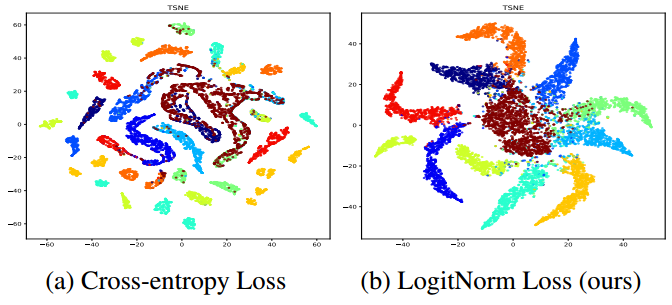
在野外使用的分类器,特别是用于安全关键系统的分类器,不仅应该具有良好的泛化特性,而且应该知道它们何时不知道,特别是远离训练数据进行低置信度预测。我们表明,产生分段线性分类器函数的ReLU型神经网络在这方面失败,因为它们几乎总是产生远离训练数据的高置信度预测。。我们表明,与标准训练相比,这种技术在降低远离训练数据的预测的置信度方面令人惊讶地有效,同时在原始分类任务上保持高置信度预测和测试误差。论文地

在Matching networks论文中对训练周期的定义上提出了episodes的概念,为了区别大数据训练的epochs,在episodes周期里,都是为了服务于few-shot任务的子类别样本训练,这个子类别就是区别于epochs中全类别子样本训练。很多meta-leaming中的任务也喜欢用episodes这个词汇,而对应神经网络中的minibatch是比较合适的。元学习旨在训练一个模型,使

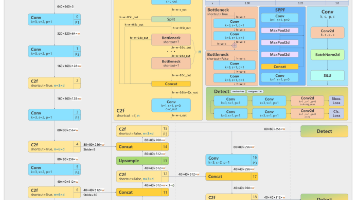
基于 YOLOv5 优化,提供 P5(640 分辨率)/P6(1280 分辨率)检测网络,以及基于 YOLACT 的实例分割网络;设计**n/s/m/l/x**5 个尺度模型,通过**深度因子(d)、宽度因子(w)、比例因子(r)** 精细化调整网络结构,适配从边缘设备到高端 GPU 的全场景需求。**无全新理论创新,聚焦工程化优化与 SOTA 技术融合**,核心改动集中在**骨干网络模块替换、检
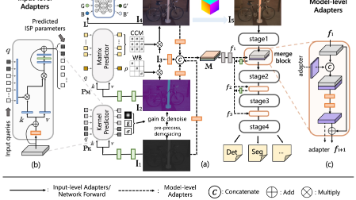
ISP 本身的设计和design是为了满足人眼视觉更好的感知,传统的ISP算法每一个step往往都需要prior knowledge,比如白平衡前需要估计光源。每一家厂商的ISP也都有自己的特点,比如Sony和华为他们的自家ISP流程的CCM以及LUT参数肯定不同,同时每家的ISP基本都是黑盒,我们很难获取里面具体的step。*SP针对人眼设计的特性也导致了,这些ISP算法并不一定能很好的满足ma
所谓平滑锯齿操作就是在Recall轴上,对于每个阈值θ计算出的Recall点,看看它的右侧(包含它自己)谁的Precision最大,然后这个区间都使用这个Precision值,Precision和Recall之间的此消彼长的矛盾关系, 既然一个模型的precision和recall是此消彼长的关系,不可能两个同时大,那怎么判断哪个模型更优呢?自蒸馏策略:为了提高 YOLOv6 较小模型的性能,我们