登录社区云,与社区用户共同成长
邀请您加入社区
解决一个50年历史的难题,原本可能需要一整天的时间,现在被压缩到了区区一个小时。有人网友提出了一个深刻的问题:「并行TTC确实发挥了作用,但没有说出口的问题是:64个独立搜索的质量,能否等同于一个漫长而连续的单线深度推理逻辑链?就这样,靠着纯粹的逻辑、群论、流场与线性代数,人类苦苦寻找了50年的那枚钥匙,被64个AI智能体在极速的穷举与交叉验证中,硬生生地锻造了出来。简单来说,这个猜想是这样的:「
摘要 本章在原型递归框架下探讨了人工智能对齐与量子计算的核心问题。对于AI对齐,将其建模为递归优化器在策略空间中的固定点安全性问题,证明了确保奖励函数不变性是对齐的充分条件,但通用对齐判定在理论上不可行(定理22.1.10)。量子计算则被诠释为非交换代数结构在物理计算中的直接实现:量子傅里叶变换的指数加速源于算符空间的非交换性(定理22.2.4),这种计算范式的跃迁对应着原型递归从交换基底向非交换
这篇文章摘要总结了常见图论算法的典型应用场景和解题思路。主要内容包括:单源最短路问题(如Dijkstra、SPFA算法及其变体)、Floyd算法应用(传递闭包、集合划分)、最小生成树问题(Kruskal算法及扩展应用)、负环检测与差分约束、最近公共祖先(LCA)应用、强连通分量与双连通分量处理、二分图相关问题(判定、覆盖、匹配)、欧拉回路问题以及拓扑排序等。每个问题都给出了核心算法和关键解题技巧,
一个图论猜想,64个AI子智能体,一小时——然后呢?Ethan Knight打开电脑的时候,大概只是想做一次常规的"AI能不能搞数学"实验。这位OpenAI研究员给GPT-5.6 Sol Ultra布置了一道题:证明"循环双覆盖猜想"(Cycle Double Cover Conjecture)——一个从1973年就开始让图论学家头疼的难题。他给系统预留了8小时,然后起身去冲咖啡。咖啡还没凉,证明
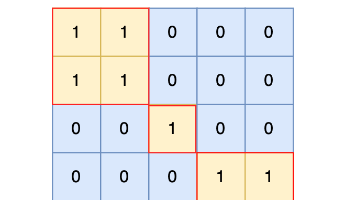
dfs 序:1 → 2 → 回溯 → 3 → 回溯 \(in[1]=1,\ out[1]=3\) \(in[2]=2,\ out[2]=2\) \(in[3]=3,\ out[3]=3\) 子树 1 对应区间 \([1,3]\),子树 2 对应 \([2,2]\)。
题解:P4637 [SHOI2011] 扫雷机器人
C++最小生成树算法解析:本文详细介绍了两种经典的最小生成树算法——Prim算法和Kruskal算法。Prim算法采用贪心策略,逐步将距离最近的顶点加入生成树,时间复杂度为O(n²)或O((V+E)logV),适合稠密图。Kruskal算法通过排序边并用并查集维护连通性,时间复杂度为O(ElogE),适合稀疏图。文章包含完整的C++实现代码,比较了两种算法的时间/空间复杂度及适用场景,帮助开发者根
【代码】C++结构体指针。
dp[j]不选,v[i]+dp[j]选。
/bs函数:用来搜索endss数组中比arr[i]小(不能相等)的第一个元素下标(从右往左算的话)//bs就是要找6的下标(大小最接近 arr[i]且比 arr[i] 小)int len=0;//len为end数组的实际大小,也是答案所在。//dp[i]:以位置i为结尾的最长递增子序列的长度。//end[i]:长度为i+1子序列的最小结尾。//方法2:时间复杂度O(N*log N)//方法1:(时
本文介绍了图论中邻接矩阵的存储方式和常见应用。
本文介绍了四个关于岛屿的算法问题及解法。101题计算孤岛总面积,通过DFS将边界相连陆地置0后统计剩余1的数量;102题沉没孤岛,先将边界相连陆地标记后转换,实现孤岛沉没;103题高山流水,使用DFS从两组边界出发搜索可到达的中间点;104题建造最大岛屿,通过标记各岛屿面积后计算水格变陆地能连接的最大岛屿面积。每个问题都采用DFS/BFS遍历二维数组,配合标记和统计等技巧解决特定条件下的岛屿问题。
return 0;sort默认是从小到大排序cmp允许我们定义一些比较复杂的规则原理:bool cmp(int x,int y)如果返回值为真,那么x放在y前面(返回值为假时,交换2个数)否则x放在y后面注意:cmp返回值部分必须使用>或者<,不能有>=或者<=return x>y;i<=10;i++)p!=v.end();int age;if(a.age!= b.age)//年龄不同的时候,小到
摘要:题目要求在由n个节点和n条边构成的有环图中,找出并删除一条冗余边使其恢复为树结构。采用并查集算法处理,初始化各个节点的父节点为自身,遍历所有边时进行合并操作。当发现两个节点已连通时,该边即为冗余边,输出后可终止程序。若存在多条冗余边,按输入顺序删除最后出现的边。代码实现包括并查集的初始化、查找根节点和合并操作,通过判断节点是否同根来检测冗余边。
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来(注意:这是一个无向图)。接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。最小生成树是所有节点的最小连通子图,即:以最小的成本(边的权值)将图中所有节点链接到一起。也正是因为
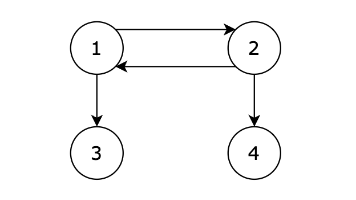
并查集是一种用于处理连通性问题的数据结构,主要功能包括:1.判断两个元素是否属于同一集合;2.合并两个集合。其核心思想是通过一维数组表示元素间的连接关系,初始化时每个元素自成一个集合。通过路径压缩优化查找效率,典型操作包括find(查找根节点)、join(合并集合)和isSame(判断连通性)。在解决图论中的路径存在性问题时,只需将相连节点合并,最后检查起点和终点是否属于同一集合即可。本文以Jav
本文摘要:本文介绍了六种基于矩阵的岛屿问题及其解法,包括计数岛屿、计算最大岛屿面积、孤岛总面积、沉没孤岛、高山流水和建造最大岛屿。这些问题均采用BFS或DFS算法解决,核心思想是通过遍历矩阵识别连通区域,并利用标记数组避免重复访问。对于不同问题,如计算周长或合并岛屿,需调整遍历策略和边界条件处理。所有算法的时间复杂度为O(N×M),空间复杂度为O(N×M)。代码示例展示了Java实现,包括输入处理
有些题目不是完整的题目,如需查看完整的题目请移步到acwing的算法基础课中。
一种c++无向图的简易实现。
【代码】C++数据结构 邻接表模板。
输出一个整数,表示从城市 src 到城市 dst 的最低运输成本,如果无法在给定经过城市数量限制下找到从 src 到 dst 的路径,则输出 "unreachable",表示不存在符合条件的运输方案。对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离,那么对所有边松弛 k + 1次,就是求 起点到达 与起点k + 1条边相连的节点的 最短距离。共有 n 个编号为 1 到 n
摘要:题目要求计算从城市1到城市n的最低运输成本(含政府补贴),可能存在负权边但不含负权回路。使用Bellman-Ford算法,通过n-1次松弛操作更新各节点最短路径。算法核心思想是动态规划,通过多次松弛确保找到最优解。输入城市数n、道路数m及每条边的权值,输出最小成本或"unconnected"(若不可达)。代码实现包括边类定义、距离数组初始化和松弛操作。若改进为SPFA算法
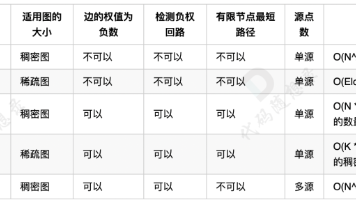
本文介绍了两种经典最短路径算法的应用:Floyd算法解决公园景点多源最短路问题,A算法解决象棋骑士移动问题。Floyd算法通过动态规划思想,计算所有节点间的最短路径,适用于多起点多终点的场景。A算法则利用启发式函数(如欧拉距离)引导搜索方向,在网格寻路中表现高效。文章还分析了A*算法的局限性,包括空间消耗问题和多目标场景的适用性问题,并对比了不同距离计算方式对算法效果的影响。两种算法在路径规划中各
本文针对树形结构路径问题,提出了一种基于深度优先搜索的解决方案。算法通过遍历每个节点,计算所有长度为k的路径危险值总和。使用邻接表存储树结构(包含终点和危险值),并利用标记数组避免重复访问。关键点在于处理双向路径存储和长整型求和(防止数据溢出)。代码实现了从每个节点出发的DFS搜索,累加满足长度条件的路径风险值,最终输出总风险值。时间复杂度主要取决于树的结构和k值大小。
摘要:这两道题目分别考察图的遍历算法应用。第一题是字符串转换问题,通过BFS在单词图中寻找最短路径,要求每次只能改变一个字符且路径上的单词必须存在于字典中。第二题是图的连通性判断,使用BFS/DFS检查从节点1出发是否能到达所有其他节点。两题都利用了队列进行广度优先搜索,时间复杂度取决于图的边数和节点数。关键点在于正确构建邻接表/边关系,并合理标记已访问节点以避免重复处理。
本文摘要: 三题均基于并查集解决图论问题。107题判断无向图中source到destination的连通性,通过并查集合并边后检查根节点是否相同。108题在无向图中找冗余边(形成环的最后一条边),使用并查集动态检测环路。109题处理有向图,分情况处理:若无入度2节点则找环边;否则删除指向入度2节点的最后一条边。核心思想均为利用并查集高效处理动态连通性问题,通过路径压缩优化查找操作,时间复杂度接近O
本文包含两个算法问题:1. 最小生成树问题:给定岛屿和连接距离,使用Prim或Kruskal算法求联通所有岛屿的最短公路总长度。Prim算法通过逐步生长生成树,Kruskal算法通过贪心选择最短边并查集判断连通性。2. 拓扑排序问题:处理文件依赖关系,使用Kahn算法进行拓扑排序。通过维护入度队列,逐步处理无依赖文件,若最终排序数量等于文件数则成功,否则存在循环依赖返回-1。两个问题都涉及图论算法
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
本文详细介绍了C++中求树结构最近公共祖先(LCA)的倍增法实现。LCA问题用于求解树中两个节点的深度最大的共同祖先节点,在路径查询和距离计算中有重要作用。核心算法分两步:预处理阶段通过DFS构建节点深度表和倍增表,查询阶段通过对齐深度和同步上跳操作高效找到LCA。文中提供了完整的C++实现代码,并分析了时间复杂度为预处理O(NlogN)、查询O(logN)的特点。此外,还对比了Tarjan和树链
本文深入探讨C#图论算法的优化实现,重点分析Dijkstra最短路径算法和Prim最小生成树算法的常见误区与正确实践。文章通过对比错误与正确代码示例(如Dijkstra算法中未标记已访问节点的典型错误),详细解析算法核心逻辑,包括节点访问标记、距离更新机制和边排序处理等关键环节。实测数据表明,优化后的算法正确率达100%,时间复杂度从O(n²)提升至O((V+E)logV)。通过幽默的技术吐槽(如
蓝桥王国拥有 $42$ 座城市以及 $42$ 位骑士。这些骑士按照 $1$ 到 $42$ 的编号顺序,分别居住在对应编号的城市中。即第 $1$ 位骑士居住在城市 $1$,第 $2$ 位骑士居住在城市 $2$,依此类推。最近,王国中引入了一项革命性技术:空间传送装置。该装置可以根据一个长度为 $42$ 的数字排列 $a$,将所有骑士一次性传送至新的城市。排列 $a$ 必须由 $1 \sim 42$
最长公共子序列 代码框架见下。
虽然 SolidWorks 的原生 API 是基于 COM(Component Object Model)技术,主要支持 VBA(Visual Basic for Applications)、库,我们可以方便地调用 COM 接口,从而实现对 SolidWorks 的自动化控制和二次开发。前几天有粉丝留言问我:SolidWorks支持用python开发吗?确保已安装 SolidWorks(2012
这是所有操作的起点。您可以选择连接到已打开的 SolidWorks,或者启动一个新的会话。
连接到 SolidWorks 后,您可以操作模型、图纸、装配体等。以下是一些常见任务的示例。
SolidWorks API 在不同版本间会有变化,请根据你的 SolidWorks 版本查阅对应文档。:某些 API 功能需要相应的 SolidWorks 许可证(如 Premium 功能)。:COM 调用可能因各种原因失败(如用户取消操作、文件锁定等),必须有健壮的错误处理。:Python 与 COM 之间的数据类型需要正确转换,特别是数组和特殊对象。:批量处理大量文件时,注意管理 Solid
代码练习 2 树的着色问题对应蓝桥云课 代码见下。代码练习 3 对应蓝桥云课 没有上司的舞会 代码见下。代码练习 1 对应蓝桥云课 生命之树。树形DP 代码框架见下。
数位DP,对应蓝桥云课 二进制问题 代码框架见下。代码练习 1 长官和他的猫 蓝桥云课 代码见下。代码练习3 对应蓝桥云课 数数问题 代码见下。代码练习2 幸运年 对应蓝桥云课 代码见下。
202411231010时间的指标值在202411231000,202411231010范围内,值是11 202411231011,202411231012时间的指标值在202411231011,202411231012范围内,值是10 202411231013时间的指标值在202411231013,202411231020范围内,值是16。查询时,根据输入的时间范围进行查询,需要返回回时间范围内
修改代码,新增 “取余(%)” 功能(仅支持整数),提示:else if (op == '%') res = (int)a % (int)b;掌握 if-else(条件判断)和 while(循环),实现支持加减乘除的连续计算器。
Tarjan算法讲解,超细步骤,免费
本文介绍了三种最短路算法:Dijkstra(正权图单源最短路)、Floyd(正权图全源最短路)和Bellman-Ford(可处理负权图及判断负环)。重点讲解了Bellman-Ford算法的原理与实现,包括n-1次松弛操作的迭代过程。随后详细介绍了Johnson算法,该算法通过建立超级源点、利用Bellman-Ford计算势能h[]、重新赋权边权使其非负,最后通过n次Dijkstra计算全源最短路。
本文介绍了最小生成树(MST)的概念和两种经典算法:Kruskal和Prim。MST指连通图中边权和最小的生成树,具有边权和最小、最大边权最小等性质。Kruskal算法通过排序边并查集实现,时间复杂度O(mlogm);Prim算法采用优先队列维护最小边,时间复杂度O(mlogn)。文章以蓝桥杯旅行销售员问题为例,详细解析了两种算法的代码实现,强调Kruskal需边排序和并查集判断连通性,Prim通
Claude AI 破解 Knuth 数周未解的哈密顿环难题,31 次人机协作探索得出简洁代码解法,引发关于 AI 智能本质与科研未来的务实讨论。
本文详细介绍了如何使用Python NetworkX库进行图论连通度计算,包括点连通度和边连通度的实战操作,并验证了敏格儿定理的正确性。通过具体代码示例和可视化方法,帮助读者掌握网络鲁棒性评估的关键技术,适用于通信网络、社交网络等多个应用场景。
本文通过Python NetworkX 2.8库实战解析五大经典图论问题,包括连通性检测、最短路径计算、最小生成树构建、图着色与匹配问题,以及社交网络分析。每个解决方案均附带完整代码示例,帮助开发者快速掌握图论算法在实际应用中的实现技巧,适用于社交网络分析、物流优化等多种场景。
图论
——图论
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 openEuler 社区
openEuler 社区

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵