- @weixin_50348308
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
刚做完正则化训练的课,有个很惊奇的发现,之后有时间了,再抽空去梳理吧。

看了几篇,总感觉这个XGBoost不仅仅是对GBDT的改进版,还包含了对CART决策树的改进。书上说,XGBoost有很好的性能,在各大比赛中大放异彩,行吧,冲这句,好好看看!划水一整天,模型看了仨!不错,虽然现在在打哈欠,还是很想把XGBoost梳理梳理。这仨都是前k-1轮的,相当于常数。

这是我看下来,最简单的内容,哭了,K-means,so niceK-means,由于太过简单,不需要数学推导时,一时间甚至无从下指首先,K-means需要提前锚定几个点,然后让所有数据样本根据与这几个点的距离,将分别选择最短距离凑成一簇有那么点近水楼台先得月,兔子硬吃窝边草的意思然后所有样本分别站队分组后,每个组再重新选出新的锚定点:计算出所有特征各自的均值,作为新锚定点重复分组与计算新锚点,直到
刚做完正则化训练的课,有个很惊奇的发现,之后有时间了,再抽空去梳理吧。
如果是按句取上下文,那么一个句子开头和末尾单词的下文就是None,语料文件有很多个句子,就会有很多个None。:毕竟CBOW是获取关键词的前c个和后c个单词来训练的,但开头单词没有前c个单词,末尾单词没有后c个单词。如果按所有句取上下文,那整个语料文件就只有开头有None,末尾有None,None数量很少。只希望,CBOW案例,不要太难,不然我根本寸步难行,只能天天打游戏聊以自慰。:不行,因为中文
下边这篇,让我大致理解了训练过程数据的变化,嗷。。。太牛了举例说明CBOW训练时的数据变化直到我看到这篇NLP笔记之word2vec算法(2)–Hierarchical Softmax原理+数学推导 - 张小彬的文章 - 知乎我天呐。。。瞬间有种顿悟的通透感!虽然还是有一些不明确的地方,但是朦胧之中,抓住了一丝丝的脉络看别人总结的关系,很清晰了。为了更方便自己理解,且减少工作量,只梳理【基于Hie

信息量、信息熵、条件熵、信息增益、基尼系数...通俗理解
徒手实现代码的过程,真是含泪和心酸,浪费了生命中的三天,以及工作中的划水一小时终于滤清思路后,自己实现了KNN都说KNN是最基础,最简单的分类器放屁!骗纸!!!它的想法是简单的,但实现的过程何其复杂!!!问题何其之多!!是我实现感知机、逻辑回归分类、线性回归、朴素贝叶斯中,最难实现的分类算法!!!!给多少时间都无法将这个槽吐尽,甚至算法都没完全弄好,但只剩收尾工作了。
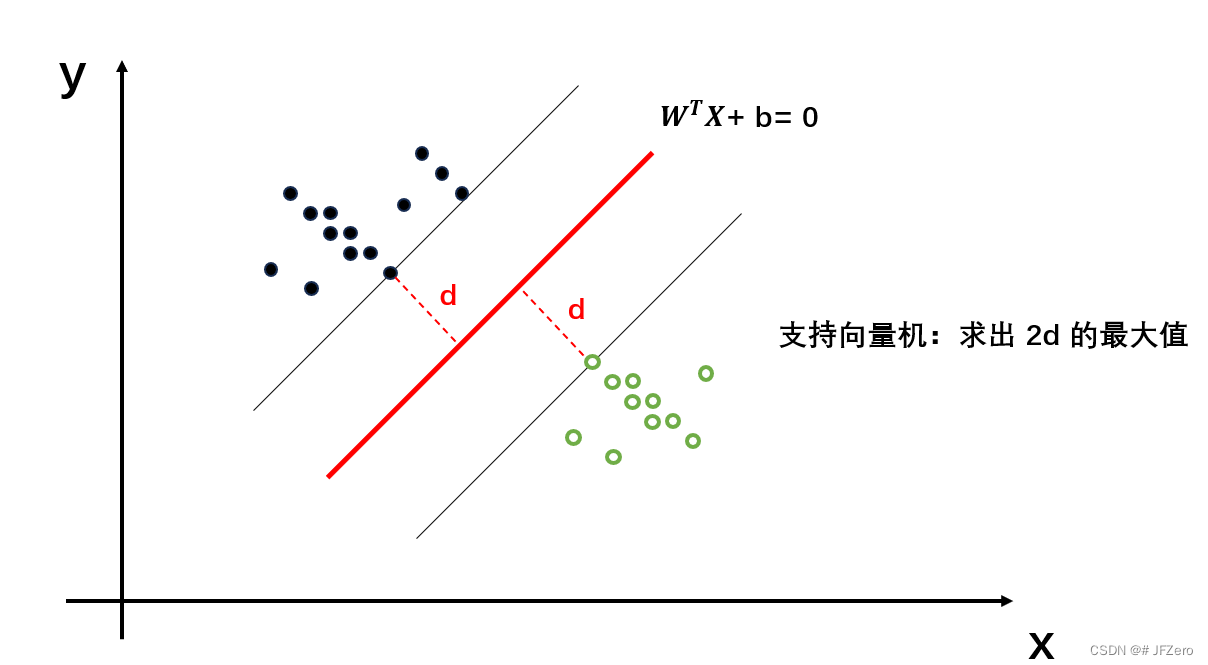
支持向量积的原理,网上已经有很多人解释了。支持向量机(SVM)——原理篇机器学习笔记(五):支持向量机(SVM)支持向量机算法(SVM)详细讲解(含手推公式)但即使看了原理篇,依然有绊倒自己的地方,或许是自己数学基础跟不上各大阿婆主,只好自己列出困惑的数学问题。当数据集线性可分时,假设有一个线性函数能将数据集分类,这就是感知机模型该做的事:找到能让数据集线性划分的一个线性函数 y=∑wixi+by
从小菜鸡的试错思考中逐步清晰!python纯手动实现朴素贝叶斯的算法,对比 sklearn实现的算法,两者结果有差异,但差异不算太大。