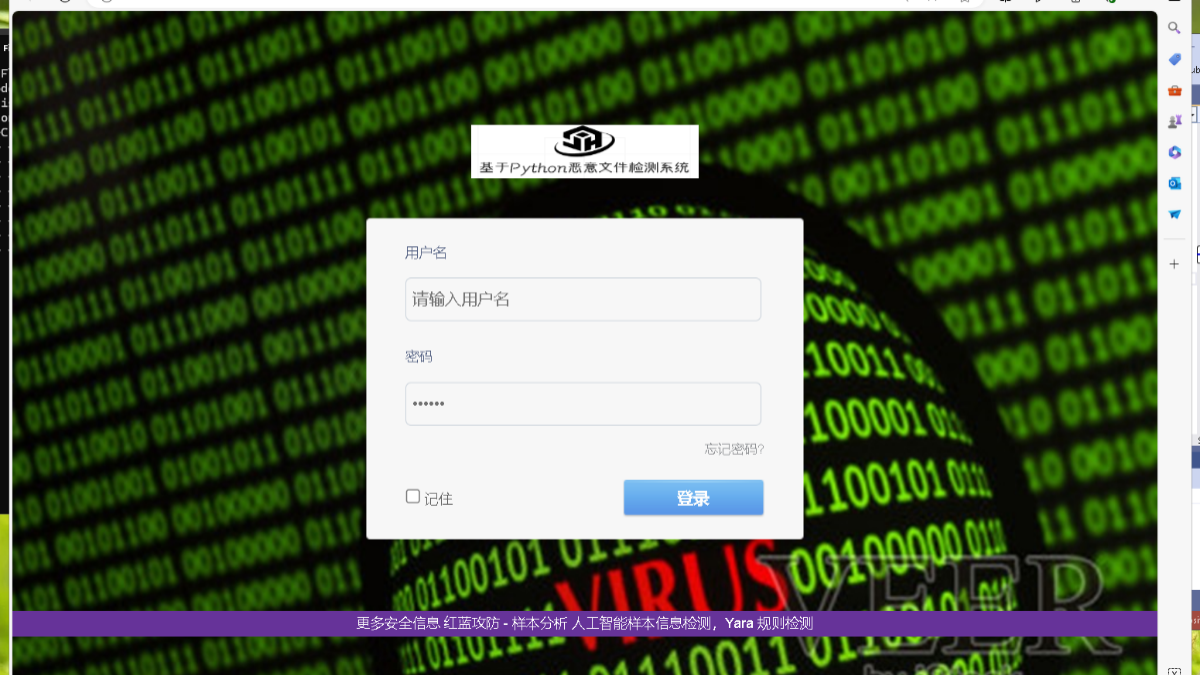
登录社区云,与社区用户共同成长
邀请您加入社区
这是一个响应式的 H5 页面,适用于手机端和电脑端,平板,各种小程序。这个demo最后我折中一下用uniapp写。回归正事之前我们把大模型细分化,分别训练不同细分类的检测方式,当然肯定有小伙伴有疑问,如果我们每一种攻击都训练,这样我们开销会不会很大,到时候不同小模型组合成大模型会不会麻烦等问题,如果我们要细分不同检查方式只能这样来,常见的有各种隧道中恶意的,加密的,异常流量,网站层面web渗透常见
这系列功能的开发历程特别有意思,完全是被网友们的需求推着一步步升级的 ,从最初的 1.0 版本开始,大家各种 “加需求” 的建议就没断过,一路迭代到现在,想想还挺有成就感的哈哈哈。到现在,还接入了各种第三方软件调用,功能越来越完善。比如加入 Snort 后,通过自定义配置规则,几乎能全覆盖各类入侵行为的检测:像 DDoS 攻击、ARP 欺骗、ICMP 异常探测、暴力破解尝试,以及常见 CVE 漏洞
一般恶意软件我们可以通过一下常见方式检测,软件行为,文件目录操作,注册表操作,网络通讯,内存操作,pe文件结构,哈希校验,恶意内容检测类似php一句话木马检测等。这个demo,我们使用哈希校验和人工智能算法来检测恶意pe行为,模型数据集使用了50多mb,可自行添加恶意pe的数据集。
它可以通过两种策略启动任务:std::launch::async(在新线程中执行)和std::launch::deferred(延迟执行,直到调用get()或wait())。std::future作为异步操作的句柄,提供三种关键操作:get()阻塞直到结果就绪并返回值,wait()仅等待完成不返回值,wait_for()/wait_until()提供超时功能。C++17引入了std::async的
以下将通过设计一个图形系统,展示如何通过C++类实现支持多态性的可扩展架构,并结合开放-封闭原则和依赖倒置原则等设计理念进行分析。此文章通过具体实施案例结合设计原则的详细分析,实现了对C++类设计的深度解构与展示,既包含代码实现又包含架构思考,符合原创技术文章的要求。- 动态绑定:`area()`和`display()`函数通过虚函数表在运行时确定具体实现。- `Shape` 是抽象基类,通过 `
本文基于真实的项目文件和开发过程,没有任何虚构。
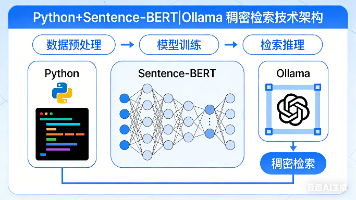
Python+Sentence-BERT|Ollama 稠密检索
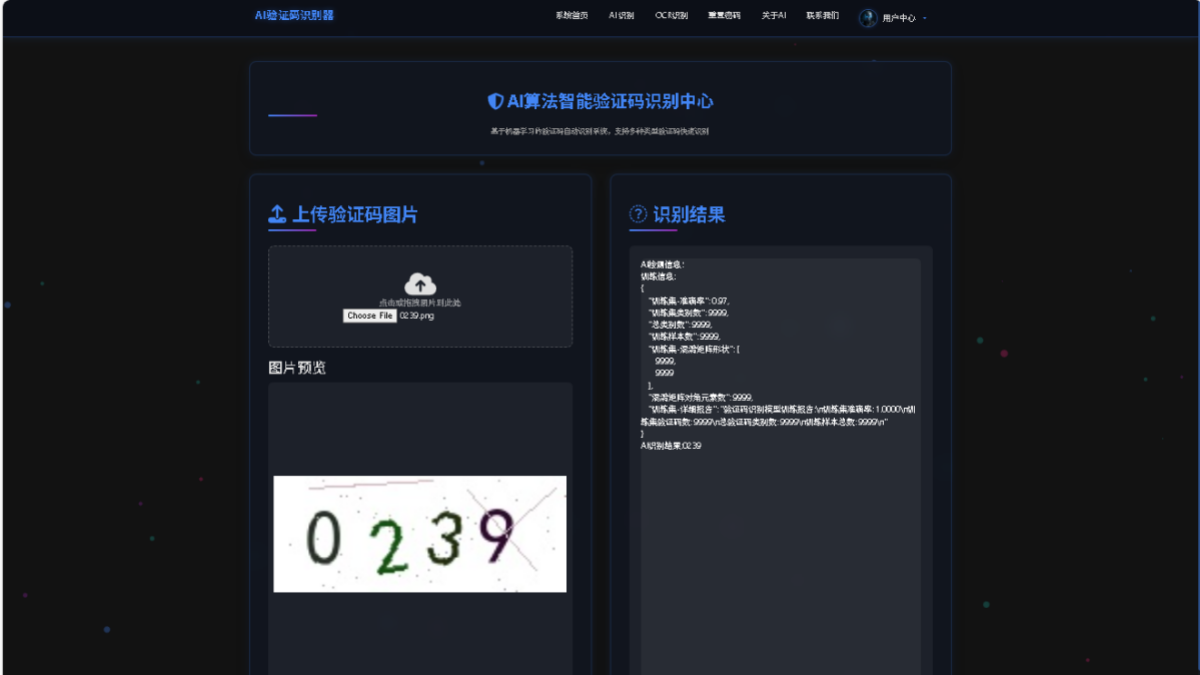
最近被安全公司抓去干活,没时间上Demo,加上单子有点多忙不过来。咱们看看细节部分,图像识别除了样本,咱们还需要把它标记出来,样本量越多越好,不同方向,倾斜的都要,然后咱们把样本特征值提取出来给AI训练,剩下的核心就是参数调优,过拟合处理就行。当然你也看下其他团队大佬写的HexStrike,DeepExploit,GyoiThon这些现成的AI自动化渗透工具,等咱们熟练这些AI工具,以及把机器学习
摘要:本文分析了VS Code中出现的"Import sklearn.model_selection could not be resolved from source"错误。该错误属于IDE智能提示问题(Pylance扩展),而非运行时错误,主要表现为无法提供代码补全和跳转功能。可能原因包括:1)scikit-learn包未正确安装(可通过pip/conda命令检查);2)P
这系列功能的开发历程特别有意思,完全是被网友们的需求推着一步步升级的 ,从最初的 1.0 版本开始,大家各种 “加需求” 的建议就没断过,一路迭代到现在,想想还挺有成就感的哈哈哈。web安全开发,在线%实时监控入侵检测,恶意流量,IDS,ids%系统安全开发3.0,基于html,css,jquery,python,django,wincap,snort辅助检测,snort规则检测,分析抓包数据,实
ModuleNotFoundError是Python包导入失败的通用错误,本质反映的是运行时环境与依赖包之间的路径匹配问题。其核心原理在于Python解释器按sys.path顺序查找模块,而虚拟环境、conda/pip混用、IDE解释器配置偏差等都会导致路径断裂。该错误不涉及代码逻辑,却直接影响scikit-learn、numpy等数据科学库的可用性,技术价值在于暴露了工程化开发中环境隔离与可复现
本文深入解析Python sklearn中random_state参数的作用与实现原理,涵盖其在数据集划分、决策树构建和随机森林等场景中的应用。通过固定random_state确保机器学习实验的可复现性,避免随机性导致的模型性能波动,并提供了工程实践中的注意事项和高级技巧。
本文详细介绍了如何使用Python sklearn实现K折交叉验证,通过5折验证提升模型泛化能力至少0.05个点。文章涵盖数据准备、交叉验证实现、网格搜索调参及结果分析,帮助开发者有效解决过拟合问题,充分利用训练集、验证集和测试集优化模型性能。
本文通过Python和sklearn库,详细讲解了如何利用KMeans聚类算法分析iris数据集,并结合t-SNE降维技术实现高维数据的可视化。从数据预处理、聚类实现到效果评估,手把手教你掌握无监督学习的核心技巧,提升数据洞察能力。
本文详细介绍了如何使用Python和sklearn从Excel数据自动化生成AUC报告,评估二分类模型性能。通过数据预处理、AUC计算原理、模块化流水线构建及可视化报告生成,帮助数据科学家高效完成模型评估,提升工作效率。重点讲解了roc_auc_score的应用及常见问题解决方案。
本文介绍了如何使用Python的sklearn库自动化寻找最佳F1分数阈值,提升二分类模型的性能。通过实战代码示例和工业级实现技巧,帮助数据科学家快速优化模型,特别适用于类别不平衡数据集和Kaggle竞赛场景。
本文详细介绍了如何使用Python中的TfidfVectorizer优化站内搜索,解决传统关键词匹配的痛点。通过TF-IDF算法,结合sklearn库,实现从文档预处理到查询处理的完整流程,显著提升搜索结果的相关性和准确性。适合需要构建智能搜索引擎的开发者和技术博主。
本文介绍如何使用Python的sklearn库中的TfidfVectorizer快速实现文本向量化,无需死记公式即可完成NLP任务。通过实例代码和参数解析,帮助读者掌握TF-IDF向量化的核心技巧,包括中文分词、停用词处理和特征维度控制,适用于文本分类和相似文档检索等场景。
本文通过Python和sklearn实战演示TF-IDF算法的核心原理与应用,从代码实现反推算法设计思想,帮助读者深入理解词频统计、文档频率及对数运算的实际意义。文章包含完整代码示例,展示如何通过TF-IDF进行文本特征工程优化,包括停用词处理、n-gram应用及权重调优。
本文详细介绍了如何使用Python的sklearn库解决多重共线性问题,重点讲解了岭回归(Ridge Regression)的原理和实战应用。通过VIF值诊断、岭回归调参全流程和业务场景选择,帮助数据科学家构建更稳定的预测模型。文章包含完整代码示例,涵盖特征标准化、参数优化和模型评估等关键步骤。
一套开箱即用的文本分类Python项目,包含已清洗的训练数据(train_data.xlsx)、对应标签(trainlabel_list.npy)和原始语料(原始数据.xlsx),配套可视化需求说明图(需求.png)。核心功能分模块实现:decision_tree.ipynb完成决策树建模、评估与特征重要性分析;模型预测.ipynb支持新文本批量输入并输出分类结果;三个预训练模型文件(model_
本文详细介绍了如何使用Python的sklearn库实战Lasso回归,快速完成特征选择。通过对比线性回归、Ridge回归和Lasso回归的特性,突出Lasso回归在自动特征选择和处理高维数据方面的优势,并提供了5分钟快速上手的代码示例和调参技巧,帮助数据科学家高效优化模型。
本文通过Python和sklearn实战演示TF-IDF算法的核心原理,帮助读者理解其背后的设计哲学和应用场景。从词频统计到IDF计算,再到完整实现,5分钟带你掌握这一文本特征提取利器,告别死记硬背公式的困扰。
本文详细解析了Python中classification_report的使用方法,从混淆矩阵到业务报告转换,提供了全面的避坑指南。通过实际代码示例,帮助读者深入理解精准率、召回率等关键指标,并展示如何将技术报告转化为业务洞察,提升机器学习模型评估的实用性和可解释性。
本文详细介绍了如何使用Python和sklearn计算平均绝对误差(MAE),并以加州房价预测为例,从数据预处理、模型选择到调优实战,全面解析MAE在回归任务中的应用。通过对比不同模型的MAE表现,指导特征工程和超参数调整,帮助开发者提升模型评估能力,实现业务价值的有效转换。
本文通过Python和sklearn库手把手教你实现TF-IDF关键词提取算法,从原理到实战应用全面解析。文章详细拆解了TF-IDF的计算过程,包括TF(词频)和IDF(逆文档频率)的实现,并展示了如何使用sklearn的TfidfVectorizer进行工业化应用。适合想要深入理解文本处理算法的开发者和数据科学家。
时间序列预测,是数据科学里最古老、也最让人头疼的战场。你是否经历过这样的绝望:用跑一个ARIMA,调参调到怀疑人生;用Prophet换个数据集就得重写一遍代码;好不容易训完一个LSTM,发现还不如移动平均准?Darts的出现,就是为了终结这种混乱。它不是一个模型,而是一把"瑞士军刀"——一个旨在统一时间序列预测生态的开源Python库。从经典统计模型到前沿深度学习,从零样本推理到自动化特征工程,它
本文详细介绍了如何使用Python的sklearn库实现Elastic Net回归,包括环境准备、数据预处理、核心参数解析、智能调参策略以及生产环境部署技巧。通过实战代码示例,帮助数据科学家在高维数据集中平衡特征选择与模型稳定性,提升机器学习模型的性能。
本文深入探讨了Python中互信息(MI)、标准化互信息(NMI)和调整互信息(AMI)三大聚类评估指标的应用。通过实战案例和代码演示,展示了这些指标如何克服轮廓系数的局限,更准确地评估聚类效果,特别适用于非球形簇和噪声数据场景。
本文以Iris数据集为例,详细介绍了使用Python和sklearn进行无监督学习的完整流程,包括数据探索、KMeans聚类和t-SNE可视化。通过实战代码和评估指标分析,帮助读者掌握聚类技术的核心要点和应用场景,特别适合数据科学初学者和从业者参考。
本文详细介绍了如何使用Python处理Excel中的sklearn模型预测结果,并准确计算二分类模型的AUC值。通过数据预处理、AUC计算实战和工程化扩展,帮助数据科学家高效解决从原始数据到评估指标的最后一公里问题,提升模型评估效率。
本文详细介绍了如何从零开始构建Bagging分类器,通过Python和sklearn实现决策树集成。文章涵盖自助采样、基分类器构建和聚合预测等核心步骤,并对比了自定义实现与sklearn的BaggingClassifier性能差异。Bagging作为经典集成学习方法,能有效降低模型方差,提升准确率,特别适用于过拟合基分类器的场景。
本文深入解析TF-IDF算法原理,并提供Python与sklearn的高效应用实战指南。从手动实现TF-IDF的细节技巧到sklearn的工业级应用,涵盖性能优化与业务适配方案,帮助开发者快速掌握文本特征提取技术,提升自然语言处理任务的效果。
本文详细介绍了如何使用Python的sklearn库通过岭回归(Ridge Regression)解决多重共线性问题。从VIF检测到α参数调优,再到实战经验分享,帮助数据科学家和机器学习工程师有效提升模型稳定性与预测精度。特别适合处理特征相关性强的数据集,如房价预测等场景。
本文深入解析了12种超越RMSE和MAE的回归评估指标,包括MAPE、SMAPE、MSLE等,帮助开发者全面评估模型表现。通过Python和sklearn实战演示,解决数据离群值、量纲差异等常见问题,提升模型评估的准确性和业务适配性。
本文详细介绍了如何使用Python和sklearn构建一个基于颜色矩的人民币面额识别系统。通过分析240张纸币图片的RGB颜色通道特征,提取颜色矩作为图像'DNA',并利用支持向量机分类模型实现高效识别。文章包含完整的代码实现、模型优化技巧及实际应用部署方案,为图像识别入门者提供实用指南。
本文详细介绍了如何使用Python和sklearn从零实现感知器算法,并通过鸢尾花分类的实战案例进行验证。内容涵盖数据准备、算法原理、模型实现、评估与可视化,以及常见问题调优技巧,帮助读者快速掌握机器学习中的感知器算法应用。
本文详细介绍了如何使用Python和sklearn计算平均绝对误差(MAE),从加载加州房价数据集到自定义模型评估流程。通过实战案例,帮助读者掌握MAE的核心价值、计算方法和高级应用技巧,包括多模型对比和误差分析可视化,提升回归模型评估的准确性和效率。
本文通过Python实战对比了sklearn中PCA、TruncatedSVD和FactorAnalysis三种数据降维算法的效果。从计算效率、内存占用和下游任务表现等多个维度进行评测,提供了详细的代码示例和选型建议,帮助数据科学家在实际项目中做出更优选择。
本文详细解析了在使用sklearn分类指标时常见的数据格式转换问题,特别是处理`ValueError: Classification metrics can't handle a mix of binary and continuous targets`错误。通过提供Python代码模板,帮助开发者正确处理二分类概率输出、多分类logits和one-hot编码等场景,确保模型评估的准确性和高效性。
随机森林是一种基于决策树集成的非线性机器学习模型,其核心原理是通过自助采样(Bootstrap)和特征随机子集构建多样性树群,再以投票或平均实现强泛化与鲁棒性。该技术无需复杂数据预处理、天然抗过拟合、对缺失值和异常值友好,成为表格数据分类与回归任务中最实用的基线模型。在电商用户流失预测、金融风控评分、医疗指标分析等典型场景中,它既能快速验证业务假设,又能作为XGBoost等进阶模型的调试锚点。本文
机器学习入门的本质是建立对数据、模型和评估的工程直觉,而非堆砌算法公式。本文聚焦监督学习中最基础的回归与分类任务,从线性回归、逻辑回归到随机森林、SVM等6个sklearn原生算法出发,系统解析特征缩放、交叉验证、概率输出、过拟合诊断等关键原理。强调标准化(StandardScaler)的适用边界、predict_proba的概率语义、以及cross_val_score背后的数据隔离逻辑,揭示新手
直接运行就能上手的股票价格预测练习项目,用scikit-learn里的随机森林回归(RFR)建模,提供三个不同颗粒度的训练脚本:main_RFR.py(单只股票)、main_RFR_all.py(全市场统一特征)、main_RFR_all_2.py(增强版特征组合)。配套真实整理好的A股历史行情CSV文件data_all.csv,get_data.py辅助你本地补充或清洗数据。所有代码都带清晰中文
本文深入解析Python机器学习中classification_report()报告的宏平均(macro avg)与微平均(micro avg)区别与应用。通过实际案例演示如何在不均衡数据场景下选择合适评估指标,帮助开发者准确评估模型在sklearn中的分类性能,提升模型评估的精准度。
Python模块导入失败(如sklearn)本质是解释器与包安装路径不匹配的技术现象,源于Python多环境共存下sys.path搜索机制、pip/conda包管理差异及IDE/Jupyter内核绑定失准。其底层涉及Python解释器可执行路径、site-packages目录映射、wheel二进制兼容性等核心原理,直接影响数据科学项目的可复现性与工程稳定性。该问题广泛出现在Jupyter Note
ModuleNotFoundError是Python环境最常见却最易误判的错误类型,本质反映的是解释器、包管理器、路径系统与运行时环境四层逻辑的错配。其核心原理在于Python通过sys.path动态查找模块,而pip/conda安装路径、PYTHONPATH、当前工作目录及IDE内核配置共同决定了该路径的有效性。技术价值在于建立可复用的环境诊断范式,避免盲目重装;典型应用场景覆盖Jupyter
sklearn
——sklearn
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区