登录社区云,与社区用户共同成长
邀请您加入社区
在多源观测数据爆炸式增长的今天,如何从复杂、高维、非线性的自然系统中提取可靠知识,已成为地球科学、生态学、环境工程与公共健康等领域科研工作者的核心挑战。本文将结合丰富的上机实战案例,带你从零开始,逐步攻克从数据预处理、超参数调优到可解释分析(XAI)、因果推断与空间异质性建模的核心难点,真正让随机森林不再只是预测工具,而成为你探索自然复杂性、讲好科学故事的智能显微镜。2、分类回归树及随机森林的能够
本文深入解析决策树的核心原理与Sklearn实战应用,从信息增益、基尼系数等数学概念到参数调优与可视化技巧。通过电商、医疗等实际案例,展示如何避免过拟合、优化模型性能,并利用Graphviz实现决策逻辑的可视化解读,帮助开发者掌握决策树在分类与回归任务中的高级应用。
本文揭示了线性代数中解空间(零空间)、最小二乘解与主成分分析(PCA)之间的内在联系。当线性方程组无解时,最小二乘解通过正交投影找到最佳近似解,而解空间则容纳不影响输出的冗余分量。PCA通过识别协方差矩阵的零空间(方差为零的方向)实现降维,保留信息量最大的主成分空间。奇异值分解(SVD)作为统一框架,将三者联系起来:解空间对应被压缩的无用信息,最小二乘解排除解空间干扰获得最优拟合,PCA则保留最重
研究采用C4.5算法构建决策树模型,通过计算各属性信息增益率确定根节点,并据此划分样本数据。决策树作为分类模型,通过内部节点测试特征属性、分支显示结果、叶节点对应类别,有效揭示属性与值间的映射关系。该建模方法为后续农业产值预测系统奠定了算法基础。
从最后一维往前比对维度:维度相等匹配,某一维是1自动拉伸对齐,维度数不够左边补 1。收获:学会基础的数据操作,数据预处理,部分线性代数(因复习考试需要,暂无更多收获。例:x = torch.arrange(12).reshape(3,4)x, y, torch.dot(x, y) #点积。例:x = torch.tensor(3.0)例:x = torch.arrange(3)形状不同的张量,自动
本文介绍决策树这一有监督学习算法,它以树形结构实现分类与回归任务,核心思想为分而治之。文中重点讲解 ID3、C4.5、CART 三类主流算法:ID3 依托信息增益划分特征,C4.5 用信息增益率优化缺陷,CART 基于基尼指数和均方误差,可兼顾分类与回归。同时对比了三种算法的差异,并讲解预剪枝、后剪枝两种方式,用以解决决策树易过拟合的问题,还结合场景给出了落地使用建议。
本文探讨了可解释性机器学习模型在金融风控和医疗诊断等关键领域的应用,详细分析了线性回归、决策树、K近邻算法和规则学习等五种高透明度算法的实战案例。通过Scikit-learn代码示例和真实业务场景,帮助开发者在项目初期规避黑箱风险,提升模型决策的透明度和合规性。
现在在样本中第一个特征是有无房产,有房产的不拖欠,无房产的容易拖欠,这样就出现了第一个分支。熵用来描述混乱程度,越混乱熵越大。因为单纯考虑信息增益对于分类过于细的特征比如 学号 ,它的信息增益非常大,但作为决策树的节点显然是不妥当的。信息增益就是信息熵 - 条件熵,得到的结果能够反映该特征分类前后数据集混乱程度的变化。Gini系数的逻辑和熵差不多,当某一类的占比越大的时候(越接近1),也就是数据集
2.特点:体现输入变量和目标变量取值的逻辑关系。分类预测是基于逻辑就,即利用if——then——的形式。1.组成:根节点,中间节点,叶子节点。2026/6/1第十四周。
大模型学习切忌急于求成、盲目啃难点,按照这套2026年最新科学学习顺序稳步推进即可:先靠Python+Transformer筑牢底层基础,用提示词工程快速收获学习成果,再深耕RAG、LangChain等落地技术,进阶掌握Agent智能体开发,最后攻克部署、微调、量化、多模态等工程化技能。全程循序渐进、理论结合实战,哪怕是零基础小白,也能快速摆脱迷茫,顺利实现大模型入门、项目落地,成功跨入AI开发赛
本文探讨了金融风控中决策树和线性模型因其可解释性而备受青睐的原因。文章分析了监管合规、业务运营和客户关系维护对模型透明度的需求,并对比了'黑箱'与'白盒'模型的优劣。通过实际案例和最佳实践,展示了如何最大化这些'老实人'模型在信贷审批、反欺诈等场景中的价值。
本文研究了C5.0决策树算法在学生成绩预测中的应用,并设计了一个多模块协同的综合平台。C5.0算法因其分类能力强和可解释性高,能有效识别影响成绩的关键因素,为个性化教学提供支持。平台包含成绩预测、行业新闻、论坛和百科等模块,其中成绩预测模块通过图像处理自动提取关键数据,行业新闻模块提供教育资讯检索和推荐功能。该平台实现了从数据采集到分析应用的全流程,为教育决策提供了科学依据和实用工具。系统功能完善
基尼指数本质上是一种衡量分布离散程度的统计工具,其核心原理是通过比例结构而非绝对数值来量化不纯度或不平等性。它在经济学中用于评估收入分配公平性,在机器学习中则被重构为分类节点的‘随机猜错率’,成为决策树分裂的关键依据。相比香农熵和误分类率,基尼指数具备计算高效、数学可导、业务解释性强等技术优势,广泛应用于风控、推荐、医疗等需兼顾精度与可解释性的工业场景。本文深入剖析其跨学科演化逻辑,并结合scik
回归树是一种基于分段常数函数的机器学习模型,其核心原理是通过特征空间的递归二分切割,实现局部最优的均值预测。相比黑箱模型,它以MSE为优化目标、以贪婪策略选择分割点,在保证一定精度的同时,天然具备强可解释性与业务对齐能力。技术价值体现在无需复杂数学基础即可理解决策路径,支持人工复现与跨角色沟通;典型应用场景包括金融风控、房产估价、医疗预后判断等需合规说明的领域。本文以静安区二手房数据为例,详解从特
决策树是一种基于if-else规则链的可解释机器学习模型,其核心原理是通过单特征二元分裂构建人类可读的决策路径。它不依赖抽象参数拟合,而是以明文结构(节点、阈值、叶子分布)直接映射业务逻辑,具备路径即证据、节点即决策点、深度即推理粒度三大技术价值。相比随机森林或神经网络,决策树无需SHAP等外部解释工具,天然支持单样本追踪、阈值审计与规则导出,广泛应用于风控审核、医疗辅助、智能客服等需高可信解释的
我们不必全盘否定AI,正如不必否定奥德修斯手中的船桨。但我们时刻不能忘记,我们是谁,我们要去向何方。当冰冷的算法试图批量生产情感,当同质化的内容试图填满我们的精神空间,我们更需要像屈原那样,以《天问》的勇气去质疑,以《九歌》的深情去吟唱。愿在这个匆忙的时代里,你依然能够找到自己安静的位置,依然能够听见内心深处那个宁静而真实的声音。那便是你最珍贵的存在,也是你穿越AI时代的风暴后,唯一值得守护的家园
来源于公开数据集(梅奥),有完整的数据处理、特征筛选、方法介绍、决策树模型构建流程,测试集AUROC值达94.79%。基于决策树算法的感冒预测3(设计源文件+万字报告+讲解)(支持资料、图片参考_相关定制)_文章底部可以扫码。
摘要:本文介绍了一个基于决策树的交通流量预测系统,通过Django框架、Spider爬虫和MySQL数据库实现用户与管理员双模块功能。用户模块提供实时天气、交通查询及预测服务,辅助出行决策;管理员模块支持数据管理与系统维护。系统利用Spider采集数据,结合决策树算法预测交通流量,并通过MySQL确保数据安全。功能模块设计清晰,用户可查看并清洗天气信息,管理员则全面监控系统运行,共同提升交通管理效
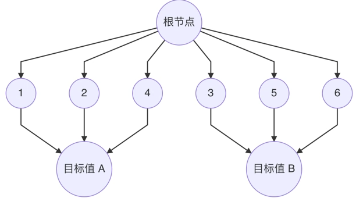
一.决策树简介决策树中每一个内部节点表示一个特征上的判断,每一个分支代表一个判断结果的输出,每一个叶子节点代表一种分类结果。对于决策树的建立过程:1.特征选择:选取有较强分类能力的特征。2.决策树的生成:根据选择的特征生成决策树。3.决策树也易过拟合,通过采用剪枝的方法缓解过拟合。所以决策树本质上是一个基于“如果-那么”规则的可解释流程图,通过基尼系数或信息增益等纯度指标递归地选择最优特征对数据进
基尼指数本质上是一种衡量分布不均衡程度的基础统计量,其核心原理是通过类别占比的平方和反推系统纯度。它并非为机器学习而生,而是1912年意大利经济学家基尼在分析收入分配时提出的公平性度量工具,后被CART算法引入作为节点分裂准则。相比信息增益等指标,基尼指数具备计算高效(O(n))、尺度稳定、抗样本不平衡等工程优势,特别适用于风控、推荐、医疗等对业务代价敏感的场景。在信贷模型中,它天然倾向保护多数类
本文设计了一个基于决策树算法的大学生网购意愿研究系统,利用Spark大数据技术结合Python、Hadoop、Hive等技术栈构建了包含前端展示、后台管理和数据爬取三大模块的分析平台。研究通过爬取大学生网购行为数据,运用决策树算法构建商品销售预测模型,将分析结果通过树状图直观展示不同商品分类的销售情况,为电商平台提供精准营销策略。该系统实现了从数据采集、存储到行为预测的全流程处理,重点解决了大学生
本文设计并实现了一个基于决策树算法的个性化饮品推荐系统。系统采用Python、MySQL、Hadoop和Spark等技术栈,构建了完整的数据处理流程:通过Pandas进行初始数据处理后存入HDFS,利用Spark进行分布式计算和决策树模型训练,最终通过Django+Vue.js实现Web可视化展示。系统功能包括数据采集存储、分布式计算处理和可视化推荐三大模块,可根据用户年龄、性别、季节等特征提供个
摘要:决策树模型在健康因素分析中发挥重要作用,可用于疾病预测、治疗方案选择和健康风险评估。其树形结构通过特征分类实现数据划分,帮助识别关键健康影响因素。系统具备数据采集、处理、分析和可视化功能,提供用户友好界面。文章还展示了地区成年人肥胖率的条形图分析。尽管决策树模型应用广泛,但仍面临数据需求量大、可解释性差和过拟合等挑战。该技术在提高医疗决策质量方面具有潜力,但需注意数据质量和模型优化。
摘要: 本研究基于Django和Python框架,开发了乳腺癌患者死亡风险预测系统,旨在解决现有预测服务不明确、管理盈利低的问题。通过需求分析与模型构建,系统实现了数据获取、可视化分析(如乳腺癌资讯文本展示)及定制化风险评估功能。模块化设计按权限划分,提升了服务的精准性与便捷性。测试结果表明,该系统能有效支持乳腺癌患者的死亡风险预测,为医疗决策提供数据支持。
本文提出了一种基于决策树算法和Spark技术的农业产值预测系统,通过数据采集、处理、分析和可视化实现农业生产智能化管理。系统采用决策树模型分析农作物、地区、环境等数据间的关联,预测可能的病虫害区域和类型,帮助农户提前采取防治措施。实验表明,该系统在预测精度和稳定性上优于传统方法,且具有操作简便、适用性强的特点。基于Vue的图形化界面简化了数据处理流程,实现"一键式"交互。研究成
今天讲一个特别直观、特别好懂的算法——决策树(Decision Tree)。你平时生活里其实天天都在用决策树,只是你自己没意识到。比如:年龄合不合适?→ 长得帅不帅?→ 工作好不好?→ 见还是不见?声音闷不闷?→ 瓜蒂新不新鲜?→ 皮薄不薄?→ 买还是不买?决策树就是把这种“一问一答”的决策过程,用计算机自动学出来。CART(分类与回归树)。它是目前最主流的决策树实现,也是随机森林、XGBoost
大模型越来越强以后,很多企业都有一个直觉:既然 AI 已经能理解文本、分析数据、总结经验,那能不能直接让 AI 接入业务系统,替企业做审批、授信、定价、风控、派单、核保这些判断?JVS-Rules规则引擎如何让AI进入?
机器学习决策树同理,通过归纳(构建树)和剪枝(删除冗余)完成。主要步骤:从数据集开始,用贪婪算法选“最佳特征”分割数据,递归生成节点直至满足停止条件(如叶节点最小样本数)。回归用平方差误差,分类用基尼指数或信息增益,理想分割使节点尽量“纯”。Scikit-Learn提供内置工具,关键参数包括max_depth、min_samples_split等,配合graphviz可可视化树结构。剪枝通过评估移
本文探讨了如何运用机器学习技术分析黑龙江省旅游资源数据。研究构建了一个包含数据采集、预处理、存储、分析、可视化和决策支持等模块的系统框架,旨在挖掘游客行为模式和旅游趋势。该系统通过多源数据整合和智能算法,可为旅游管理部门提供热门景点识别、资源优化配置等决策支持,助力黑龙江旅游业发展。未来研究可进一步拓展影响因素分析维度。
摘要:本文研究了基于机器学习的个性化智能推荐系统,针对信息过载问题提出解决方案。系统包含数据抓取、处理、可视化和管理四大模块,通过分析用户行为数据实现精准推荐。研究验证了系统在提高推荐准确性和用户满意度方面的有效性,为缓解信息过载提供了技术参考,并探讨了深度学习等算法在推荐系统中的未来应用前景,同时强调需重视用户隐私保护问题。
本研究基于机器学习技术构建了一个动漫评论情感分析系统,实现了从数据采集到情感分类的全流程自动化处理。系统包含用户端和管理员端两大模块:用户端提供动漫浏览、评论分析和公告功能;管理员端具备数据管理、用户管理、评论分析和系统维护等功能。通过爬取豆瓣动漫数据,采用文本预处理、特征提取和分类器训练等技术,系统能有效识别评论的正面、负面和客观情感倾向。测试表明系统运行稳定且分类准确率高,为动漫推荐和情感分析
本研究设计实现了一个基于机器学习的景区流量分析与可视化系统,集数据采集、处理、预测和可视化于一体。系统采用随机森林回归算法,结合景点历史客流、评分、等级等多维特征构建预测模型,准确率达90%。通过数据大屏、热力图等形式实现客流、评价等信息的可视化展示,为景区提供客流预测、资源调度等管理支持,同时帮助游客规划行程。系统包含数据爬取、处理、分析预测、可视化展示和管理五大功能模块,采用Scrapy框架采
本文介绍了一个基于机器学习的敏感话题识别与监测系统开发项目。该系统整合爬虫技术、自然语言处理和机器学习算法,结合Django和Spark框架,实现网络数据的实时采集、处理与分析。系统通过预处理和特征提取提升数据质量,利用Spark处理海量数据,Django构建后端服务,Vue.js开发用户界面。功能模块图清晰展示系统结构,同时具备文本真实性变化趋势的可视化分析功能,通过折线图呈现真实性评分随时间的
本文基于机器学习技术构建电影推荐预测模型,利用万达和豆瓣的电影数据(类型、演员、导演等特征),通过算法对比优化建立高精度预测系统。研究显示上映时间、类型和演员阵容对推荐影响显著。系统采用Vue+Django架构,集成数据采集、可视化展示(图表/时间序列)和智能推荐功能,通过Hadoop处理大规模数据,为电影市场分析和营销策略提供决策支持。模型能有效预测电影市场潜力并展示关联评论信息。
决策树
——决策树
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI编程社区
AI编程社区






 AI Agent技术社区
AI Agent技术社区




 智能体开发者社区
智能体开发者社区