登录社区云,与社区用户共同成长
邀请您加入社区
平常遇到问题,经常会在CADN中找到解决方法,今天也把自己解决问题的方法的记录一下。安装代码如下:if (!requireNamespace(“BiocManager”, quietly = TRUE))install.packages(“BiocManager”)BiocManager::install(“ChIPpeakAnno”)BiocManager::install(“ChIPseeke
matlab绘图之plot使用matlab绘图之plot使用功能介绍坐标范围限定添加标题和轴标签图形修改更改线宽更改线型线条颜色同时画多图代码下载matlab绘图之plot使用很荣幸,能够遇到您。这是我重新记录工作的开篇。希望能坚持下去 。功能介绍plot函数提供以图形的方式观察一维数据的功能。最少有一个参数,命令如下。p=plot(y);轴坐标是幅度,横坐标是数据序号。坐标范围限定可以使用xli
关于matlab的table数据结构的使用matlab中比较好使的数据结构有数组、矩阵、元胞数组、结构数组等等,但随着大数据的普及,在2013以以上版本的的matlab中,出现了类似R语言中的列表一样的一个新的数据结构——table。关于table的简单的介绍可以参考:Matlab table数据结构三篇配合着doc文档,很快就能驾轻就熟。然而Matlab求全不求精,数据分析和处理很
【代码】github安装失败的解决方法(Win/Mac通用)
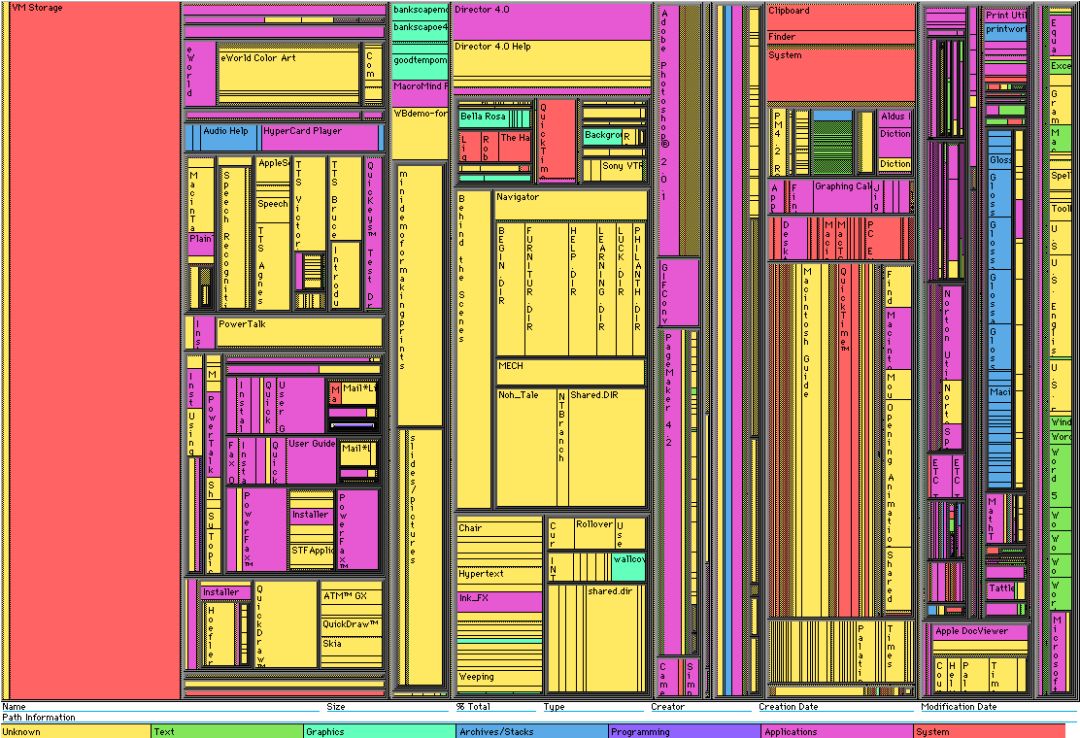
文章绘图之矩形树状图 (treemap)
如何在linux中后台运行R重要提示:本部分参考、借鉴于本博客首先运行Rscripts命令,查找Rscript所在位置。which Rscript在我的电脑得到信息如下:/usr/local/bin/Rscript在Notepad++准备代码,首行应为“#! /usr/local/bin Rscript”其他代码如R中一致,切忌不要忘了packages的调用最后准备完毕后,将代码文本命名为 my.
李恒团队开发出高效基因组组装算法hifiasm(ONT),仅需标准ONT测序数据即可实现近端粒到端粒(T2T)组装。该算法通过创新的相位校正技术克服ONT数据的高错误率,相比现有方法计算效率提升10倍且无需GPU。测试显示其组装质量优于Verkko+HERRO等算法,能解析HiFi难以处理的SMN1/SMN2等医学相关基因。这一突破使群体规模T2T基因组分析和临床样本研究成为可能,相关成果已发表于
GitHub & BitBucket HTML Preview
path<-('E:/H/论文/数据')#改成自己的路径。注意:pathname中的第二个参数要加单引号。
biomaRt是一个在 R 语言中广泛使用的软件包,它提供了一个接口来访问多个生物信息学数据库,尤其是 BioMart 数据管理系统。BioMart 是一种为基因组信息提供高效、灵活检索的数据库系统。
【代码】解决 “无法在貯藏處https://bioconductor.org/packages/3.16/bioc/src/contrib中读写索引: cannot open URL ”
从github上安装包出错
seurat 表达矩阵访问seurat有个active assay,它其中存的就是表达矩阵,用pbmc[[“RNA”]]@counts就可以访问数据标准化后的基因表达矩阵放在:pbmc[[“RNA”]]@data
Quarto 是一个由 RStudio 的母公司 Posit 团队开发的开源科学和技术出版系统,它建立在 Pandoc 之上,支持使用 Python、R、Julia 和 Observable.js 等多种编程语言来创建动态内容。Quarto 允许用户以纯文本 Markdown 或 Jupyter 笔记本的形式编写文档,并能够将这些文档发布为高质量的文章、报告、演示文稿、网站、博客和书籍等,输出格式
bioconda、rstudio的安装使用
【代码】错误: 函数‘gsva’标签‘param = “matrix“’找不到继承方法。
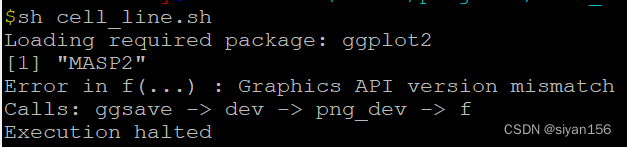
2、在服务器上进行上述操作,遇到新的报错:make: x86_64-conda-linux-gnu-ar: Command not found。,修改R/etc/Makeconf 中的AR 参数,x86_64-conda-linux-gnu-ar改为其绝对路径。最近更新把R版本更新至4.3.0版本。但是在使用ggsave函数保存图片时报错,一番资料的查找,得到解决。我是在centOS系统上,使用m
Rheatmapinstall.packages('heatmap')install.packages('treemap')library(heatmap)library(treemap)data=matrix(1:25,nrow=5,ncol=5,Rrow=FALSE,dimnames=list(c('A1','A2','A3','A4','A5'),c('B1','B2','B3','B
踩坑:官方提供的getCheckedNodes()方法适用于手动点击节点获取信息,但并不能获取搜索后出现的查询结果的节点信息查询结果如上↑,选中后获取不了节点信息。随后在网上查了一下,发现可以使用getNodeByValue方法获取,如下:<!-- HTML --><el-cascaderref="cascader"filterableclearablev-model="form
前文 在安装grpcio的依赖的时候,竟然发现了编译失败,网上找了一大圈的,都解决不了我的问题,比如下载python-devel依赖,比如升级pip等等,最后发现原来换个方式搜就能解决问题了。报错:We could not diagnose your build failure. Please file an issue at http://www.github.com/grpc/grpc wi
这是一个面向新手的 R 包构建与 GitHub 发布入门教程文档。该 Markdown 文档以“从零开始、一步不跳”为原则,完整记录了创建 R 包骨架、配置 Git、生成文档与示例数据、添加测试、通过 roxygen2 生成帮助文件,以及最终将包发布到 GitHub 并供用户安装使用的全过程。
本文为R语言用户提供了利用ChatGPT高效生成高质量ggplot2数据可视化的完整指南。文章首先指出R用户在数据可视化学习曲线陡峭的痛点,尤其是ggplot2语法复杂、参数繁多的问题。核心内容包括: 提问准备:详细介绍了5个关键诊断问题,包括数据特征、故事目标、受众需求、图表类型选择和代码风格偏好,强调提供结构化数据样本的重要性。 Prompt编写:提供了标准化的Prompt模板,包含数据背景、
但进入2026年,一场更深刻的变革正在发生——行业逻辑正从“卖硬件”全面转向“卖场景、卖服务、卖系统”。但现在,点位的密度已经达到一定程度,增长的下一个引擎来自“让每台设备卖出更多”。但进入2026年,我观察到一场更深刻的变革——行业底层逻辑正在从“卖硬件”转向“卖场景、卖服务、卖系统能力”。背后支撑的是一套融合了物联网、AI、大数据与本地知识库的软件体系,让每台机器具备“千机千面”的适应能力。真
理解数据中蕴含的信息是一项重要挑战。安全和可互操作的临床数据集的收集和挖掘对科学进步、人工智能训练、药物研究、科学探索、商业调查和精准医疗至关重要。
随着数据科学和人工智能的快速发展,R语言在这些领域的应用前景广阔。R语言在统计分析和数据可视化方面的优势使其在科研和教学中仍然具有重要地位。
点击“文件--导入自--设备”,选择xml文件,即可看到E-R图,再点击保存按钮,可以将E-R图保存成。.drawio文件,下次可以点击“文件--从...打开--设备”即可修改E-R图;用AI生成draw.io工具能识别的xml内容,提示词如下;“文件--导出为--图片”可将E-R图下载到本地;批量将多个表结构作为输入参数提供给AI;
这个项目的核心价值不是"自动生成笔记元数据"——是证明了后端工程师借助AI,可以独立完成跨技术栈的产品开发。
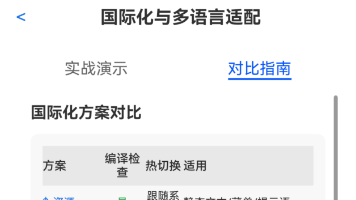
本文介绍了HarmonyOS NEXT的国际化开发方案,重点解析了i18n、intl和$r三大工具的使用方法。文章指出国际化不仅涉及文字翻译,还包括数字格式、日期格式、复数规则和排版方向等差异。系统通过i18n模块获取语言环境信息(如系统Locale、语言、地区),利用intl模块实现数字、日期等数据的本地化格式化,配合$r机制自动切换静态文本资源。三者协同工作可构建完整的国际化解决方案,避免硬编
《用R探索医药数据科学》专栏系统介绍了R语言在医药数据科学中的应用,涵盖机器学习、统计学、数据可视化、临床试验分析、文献挖掘、公共数据库挖掘等九大模块。文章对比了机器学习与传统统计学的差异,并探讨了R语言与ChatGPT结合在自然语言处理中的潜力。专栏提供5000-9000字的深度技术文章,强调实操性,指导读者从基础到进阶掌握R语言在医药领域的数据处理、建模与可视化技能,助力科研与临床研究。
机器学习(Machine Learning,ML)则是人工智能的一个分支,致力于开发能够从数据中学习和改进其性能的算法和统计模型。简而言之,机器学习让计算机通过分析大量数据自行“学习”并做出预测或决策。
机器学习则是人工智能的一个分支,致力于开发能够从数据中学习和改进其性能的算法和统计模型
R 是一种功能强大且灵活的编程语言,广泛应用于数据科学和统计分析领域。结合人工智能技术,R 不仅为智能系统开发提供了稳健的框架,还为数据处理、建模和分析带来了高效的解决方案
本文介绍了两种生物信息学数据去重方法:1. R脚本实现(带详细注释):- 支持按指定列去重,可处理CSV/TXT/Excel格式- 自动检测文件编码,解决中文乱码问题- 核心使用duplicated()函数保留首次出现的行2. 零代码云平台方案(翰佰尔HiOmics):- 一键上传文件并设置去重列- 无需编程基础,快速获得结果文章对比了不同去重列的效果差异,强调应根据分析目的谨慎选择去重依据,避免
建立input、data_raw、data_processed、scripts、notebooks、outputs、figures、arcgis_project、paper_pack等标准目录,使数据、脚本、结果和论文材料有清晰位置。利用AI对文献标题、摘要、关键词和空间数据字段进行快速整理,识别研究热点、关键词组合、空间现象和潜在研究空白。制作研究区图、空间因子图、研究对象图、指标分布图、空间叠
本文深入探讨了基于HarmonyOS Next API 24+的「车辆保养手册」应用资源层设计。系统讲解了ArkUI资源体系,重点解析了$r资源引用机制与$string等快捷语法的区别及适用场景,详细说明了module.json5与app.json5配置文件的资源引用边界。通过实际案例展示了字符串与颜色资源的工程组织方式,包括AppScope与模块资源的合理分工。文章还分享了从资源缺失报错到全链路
本文介绍了R语言及RStudio的下载安装步骤:首先从CRAN官网下载对应操作系统的R语言安装包(Windows/macOS),按向导完成安装并注意路径无中文;随后从Posit官网下载RStudio安装程序,同样建议英文路径安装。最后通过RStudio控制台输入print("Hello,R!")验证环境,成功输出即表示配置完成。该环境支持高效的数据分析、统计计算和可视化操作。
R 不仅功能强大,更是简单易学,所以目前成为了在数据分析领域最热门的集中编程语言之一, 广泛用于人工智能、统计学术研究在内的各个领域,鉴于 R 开源的特性和强大的功能,R 与 Python 慢慢成为了数据分析与人工智能领域最流行的语言。除了以上行业,在地学领域,R 也提供了大量的数据处理和绘图的专门包,甚至在官网还有关于 地学空间数据、时空数据以及 R 在水文数据和模拟应用上的专题。常见文件的读写
Copula理论作为现代统计学的突破性方法,通过Sklar定理突破了传统相关系数的局限,能够精确刻画变量间的复杂相依结构。该理论涵盖二元Copula建模、高维Vine Copula、时间序列分析、回归建模等核心内容,并涉及参数估计、统计检验和模型选择等关键技术。随着计算技术的发展,Copula已与贝叶斯网络、AI辅助分析等前沿领域深度融合,在金融、水文、工程等领域获得广泛应用。系统讲解从基础理论到
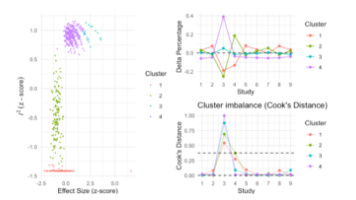
【AI大语言模型支持下的】R-Meta分析核心技术:从热点挖掘到高级模型、助力高效科研与论文发表"
这么好的事,不点一下试试?
量化交易初学者会遇到编程语言选择难题,Python和R语言各有优势。Python应用广泛且库丰富,R语言在统计分析方面表现出色。了解它们的特点,能帮助初学者做出恰当选择,从而开启量化交易之旅。
主要技术路线包括基于序列级置信度的奖励机制(奖励模型高置信度答案)、基于多路径推理一致性的奖励机制(奖励跨推理路径保持一致的答案)、低输出熵奖励(奖励确定性强的答案)、随机奖励(促进探索)以及负奖励(惩罚错误答案)。当前的LLM改进方法高度依赖大规模人工标注数据,这种范式虽然取得了显著成果但面临两个根本性限制:人类生成数据的有限性将导致训练瓶颈,以及人工数据的智能上界制约了模型超越人类能力的可能性
在语音识别技术普及过程中,“方言壁垒” 始终是下沉场景落地的关键阻碍。我国方言体系复杂,仅汉语方言就涵盖官话、吴语、粤语等十大方言区,不同方言的音素结构、词汇表达差异显著,传统通用语音模型在面对 “小众方言识别不准”“普方混说语义断层” 等问题时往往力不从心。本文将从技术原理、算法优化、工程落地三个维度,系统拆解多方言语音识别的核心难点与解决方案,结合真实测试数据提供可复用的技术思路,为开发者提供
r语言
——r语言
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



















 AtomGit AI 社区
AtomGit AI 社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 2048 AI社区
2048 AI社区

 EazyDevelop社区
EazyDevelop社区
 HarmonyOS开发者社区
HarmonyOS开发者社区


 智能体开发者社区
智能体开发者社区
 openEuler 社区
openEuler 社区

 AI Agent技术社区
AI Agent技术社区